---
title: "经济与商务实证研究方法 - 第 4 周:DiD 方法的前沿拓展"
subtitle: "完整讲义:从匹配 DiD 到合成 DiD,再到交错 DiD 与面板匹配"
author: "陈志远"
institute: "中国人民大学商学院"
date: "2026-05-23"
format:
html:
theme: cosmo
css: ../../lecture-notes.css
html-math-method: mathml
toc: true
toc-depth: 3
number-sections: true
code-fold: false
code-tools: true
highlight-style: github
self-contained: true
embed-resources: true
page-layout: article
execute:
echo: true
warning: false
message: false
eval: true
cache: false
fig-width: 10
fig-height: 6
dpi: 150
lang: zh
jupyter: rmeb-venv
---
```{python}
#| echo: false
#| output: false
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 150
np.random.seed(42)
```
# 引言 {#sec-intro}
W3 我们建立了经典 2×2 DiD 的识别与推断框架:两组两期、平行趋势、聚类标准误。但现实里的政策评估几乎不会出现在这样干净的设定里——处理单位选择往往依赖可观测的混杂因素、政策分批推进、某些研究只有*一个*处理单位。本讲把 W3 的工具箱拓展到四个更现实的方向。
*第一条线*是匹配与半参数。当处理组与对照组在协变量分布上*本身*就不同时,即使做了 2×2 DiD,平行趋势也可能被未观测的组间差异污染。倾向得分匹配 DiD(PSM-DID)、Abadie (2005) 的半参数 DiD,都是为了解决这个问题。
*第二条线*是合成化。当研究只有一个处理单位(加州 Prop 99、英国脱欧、海南自贸港),DiD 无法直接使用——合成控制法(SCM)和它的现代继承者*合成 DiD*(Arkhangelsky et al., 2021)填补了这个空白。
*第三条线*是交错处理。Goodman-Bacon (2021) 证明 TWFE 在交错处理下可能给出*错误符号*的估计量——这是最近十年计量学界最大的一场震动。Callaway-Sant'Anna、Sun-Abraham、de Chaisemartin-D'Haultfoeuille、Borusyak-Jaravel-Spiess 提供了系统的修复方案。
*第四条线*是动态与历史。Ashenfelter (1978) 提醒我们过去的 $Y$ 本身就是时变混杂;Imai-Kim-Wang (2021) 用面板匹配的语言系统地刻画“条件在 $L$ 期历史之后的 ATT”——对不稳定、可逆的政策尤其有用。
## 上节课回顾
W3 的核心要点:面板数据解锁了组内变异,固定效应扣除时不变异质性;经典 2×2 DiD 在“平行趋势 + 无预期”下识别 ATT;TWFE 回归与 DiD 估计量在 2×2 下等价;推断必须聚类到政策分配的最细层级。本讲的六个话题都可视为 W3 框架在不同维度上的拓展:PSM-DID 拓展了“对照组构造”,合成 DiD 拓展了“单位权重”,交错 DiD 拓展了“多时点多组群”,Imai-Kim-Wang 拓展了“时间路径条件化”。
# 第一部分:倾向得分匹配 DiD {#sec-psm}
## 从潜在结果到选择偏误
把“是否选修 RMEB 课程”看作一个二元决定 $D_i \in \{0, 1\}$,未来收入 $Y_i$ 是我们关心的结果变量。每个学生都有两种潜在结果:选修下的收入 $Y_i^1$ 和不选修下的收入 $Y_i^0$。我们只能观测到一个:
$$Y_i = D_i Y_i^1 + (1 - D_i) Y_i^0$$
受处理组的平均效应(ATT)定义为
$$ATT = E[Y_i^1 - Y_i^0 \mid D_i = 1, \boldsymbol{X}_i]$$
但我们无法同时观测 $Y_i^1$ 和 $Y_i^0$。最朴素的做法是用对照组的结果近似处理组的反事实:
$$\underbrace{E[Y_i \mid D = 1, \boldsymbol{X}] - E[Y_i \mid D = 0, \boldsymbol{X}]}_{\text{观测差异}} = \underbrace{\delta(\boldsymbol{X})}_{ATT \mid \boldsymbol{X}} + \underbrace{E[Y_i^0 \mid D = 1, \boldsymbol{X}] - E[Y_i^0 \mid D = 0, \boldsymbol{X}]}_{\text{选择偏误}}$$
右端第二项就是*选择偏误*:处理组与对照组的“无政策下结果”的系统差异。选择偏误为 0 时,观测差异直接识别 ATT;当它不为 0 时,简单比较就会偏。
### 条件独立假设(CIA)
一个关键的识别假设是 Rubin 的 CIA:
$$Y_i^0 \perp D_i \mid \boldsymbol{X}_i$$
在 $\boldsymbol{X}_i$ 给定的前提下,处理状态相当于*随机指派*。此时 $Bias(\boldsymbol{X}_i) = 0$,ATT 可识别。Angrist (1998) 研究自愿服兵役时即用此假设。
CIA 的*失效*场景:当不可观测特征(能力、偏好、私人信息)同时驱动 $D$ 与 $Y^0$ 时,CIA 不成立。实证研究的核心任务之一就是论证 CIA 的合理性——这通常需要制度背景、数据结构与稳健性检查三者合力。
### 回归与匹配:两种加权
“Regression can be motivated as a particular sort of weighted matching estimator.” (Angrist & Pischke) 匹配与回归最大的区别在*权重结构*:
- *匹配估计量*把权重放在 $\Pr(D=1 \mid \boldsymbol{X})$ 较高的协变量格子上——这些格子“更接近处理组”;
- *回归*则把权重放在 $\Pr(D=1 \mid \boldsymbol{X}) \cdot [1 - \Pr(D=1 \mid \boldsymbol{X})]$ 较大的格子上——处理 / 对照比例接近 50:50 的区域权重最高。
*共同支撑*(Common Support)要求 $0 < \Pr(D=1 \mid \boldsymbol{X}) < 1$:若某些 $\boldsymbol{X}$ 值下*没有*处理单位,或*没有*对照单位,权重无法定义,估计量无解。实证中必须先画倾向得分的分布重叠图才能继续。
## 倾向得分匹配(PSM)
当 $\boldsymbol{X}$ 的维度很高,逐维匹配在有限样本下几乎不可行。Rosenbaum & Rubin (1983) 的突破是:在 CIA 成立时,匹配*倾向得分*就够了。
**排除限制**(Heckman-Ichimura-Todd, 1998):把 $\boldsymbol{X}$ 拆成 $(\boldsymbol{T}, \boldsymbol{Z})$:
$$Y_i^0 = g_0(\boldsymbol{T}_i) + U_i^0, \quad Y_i^1 = g_1(\boldsymbol{T}_i) + U_i^1$$
$$\Pr(D_i = 1 \mid \boldsymbol{X}_i) = \Pr(D_i = 1 \mid \boldsymbol{Z}_i) = P(\boldsymbol{Z}_i)$$
$\boldsymbol{T}$ 进入潜在结果方程,$\boldsymbol{Z}$ 进入选择方程,两者不必互斥。识别 ATT 只需要*弱一些*的假设:
$$U_i^0 \perp D_i \mid P(\boldsymbol{Z}_i) \quad (\text{PSM 下的 CIA})$$
这是一个结构式的解释——把 PSM 嵌入经济学的选择模型:
$$D_i = \mathbb{1}\{\lambda(\boldsymbol{Z}_i) - v \geq 0\}$$
若 $\boldsymbol{Z} \perp v$,则 $P(\boldsymbol{Z}) = F_v[\lambda(\boldsymbol{Z})]$;若再有 $\lambda(\boldsymbol{Z}) \perp (U^0, v)$ 且 $E(U^0) = 0$,则对任意 $s$ 有 $E(U^0 \mid v = s) = 0$——不可观测维度上不再选择。
## PSM-DID:把匹配嫁接到面板
单期横截面的 PSM 能处理*可观测混杂*,但对不可观测的时不变混杂束手无策。面板数据给我们一个额外的差分机会:
$$\hat{\delta}^{PSM\text{-}DID}(\boldsymbol{X}) = E[Y_{i1} - Y_{i0} \mid \boldsymbol{X}, D_{i1} = 1] - E[Y_{i1} - Y_{i0} \mid \boldsymbol{X}, D_{i1} = 0]$$
在平行趋势假设下,这个量恰好识别 ATT:
$$\hat{\delta}^{PSM\text{-}DID} = E[U_i^1 - U_i^0 \mid P(\boldsymbol{Z}), D = 1] - E[U_i^1 - U_i^0 \mid P(\boldsymbol{Z}), D = 0]$$
PSM-DID 比单期 PSM 多承担两件事:
- 允许*选择依赖于潜在结果的水平*:个体固定效应被差分掉;
- 允许*部分不可观测维度上的选择*:只要那些维度时不变。
### 实施步骤
1. 用 `probit` 或 `logit` 估计 $P(\boldsymbol{Z}_i)$;
2. 按*队列-年份*在 $\hat{P}(\boldsymbol{Z}_i)$ 上做最近邻匹配;
3. 生成差分结果 $\Delta Y_{it} = Y_{it} - Y_{i0}$,加权聚合到 $ATT_{gt}$。
推断依赖 Abadie & Imbens (2006) 的解析标准误(考虑匹配引入的额外不确定性);Stata 命令 `teffects psmatch` 直接支持。
### Stata 实战:完整 DGP(Lab §2)
以下代码复现配套实验室 `L4-Diff-in-Diffs-More.ipynb` 中的 DGP:
```stata
* ===== DGP:500 个体 × 2 期面板 =====
clear all
set seed 10101
set obs 500
g id = _n
g lambda = rnormal(0, 0.5) // 个体固定效应
expand 2
bys id: g t = _n - 1
g x = rnormal(0, 1)
g u1 = rnormal(0, 0.2)
g u0 = rnormal(0, 0.2)
g v = rnormal(0, 1) if t == 1 // 选择方程噪声
scalar delta = 0.1 // 时间趋势
scalar alpha1 = 0.1
scalar alpha2 = 0.2
g y0 = alpha1*x + alpha2*x^2 + lambda + delta*t + u0
g y1 = alpha1*x + alpha2*x^2 + lambda + delta*t + u1
g D = 0
bys id (t): replace D = 1 if t == 1 & x > v // x 大的单位进入处理
g tau_u = cond(D == 1, 0.15, 0) // 真实 ATT = 0.15
replace y1 = y1 + tau_u if D == 1
g y = D*y1 + (1 - D)*y0
save simdata_did1.dta, replace
```
### 估计倾向得分 + 重叠检查
```stata
qui probit D x if t == 1
predict pr1 if t == 1
qui probit D x x^2 if t == 1 // 非线性倾向得分
predict pr2 if t == 1
twoway (hist pr1 if t==1 & D==1, color(blue%30)) ///
(hist pr1 if t==1 & D==0, color(red%30)), ///
legend(order(1 "treated" 2 "control")) ///
title("Propensity Score Overlap")
```
### PSM-DID 估计与近邻数敏感性
```stata
tsset id t
g dy = y - l.y // 差分结果
* 不同近邻数下的 ATT
matrix Res = J(10, 3, .)
forv i = 1/10 {
qui teffects psmatch (dy) (D x, probit) if t==1, ///
atet nn(`i') vce(robust)
matrix Res[`i', 1] = (_b[r1vs0.D], _se[r1vs0.D], `i')
}
```
**实操建议**:2–5 个近邻是稳健的默认选择;若 ATT 对近邻数极度敏感,说明重叠不好或处理效应异质。
### Python 演示:PSM-DID 的核心思想
下面用 Python 直接复现 DGP 并比较“TWFE vs. PSM-DID”:
```{python}
#| code-fold: show
#| code-summary: "点击查看 PSM-DID Python 代码"
#| fig-cap: "PSM-DID:当处理选择依赖 x 时,简单 TWFE 产生偏差"
#| fig-width: 12
#| fig-height: 5
from sklearn.linear_model import LogisticRegression
from scipy.spatial.distance import cdist
rng = np.random.default_rng(10101)
n = 500
lam = rng.normal(0, 0.5, n)
x = rng.normal(0, 1, n)
v = rng.normal(0, 1, n)
D = (x > v).astype(int)
delta, a1, a2 = 0.1, 0.1, 0.2
tau_true = 0.15
# t = 0, 1
def outcome(t, d):
u = rng.normal(0, 0.2, n)
base = a1*x + a2*x**2 + lam + delta*t
return base + u + (tau_true * d if t == 1 else 0)
y0 = outcome(0, np.zeros(n, dtype=int))
y1 = outcome(1, D)
dy = y1 - y0
# (1) 朴素差分
naive = dy[D == 1].mean() - dy[D == 0].mean()
# (2) PSM-DID:用 logit(x, x^2) 估计倾向得分,1-近邻匹配
X = np.c_[x, x**2]
ps = LogisticRegression().fit(X, D).predict_proba(X)[:, 1]
ps_treated = ps[D == 1]
ps_control = ps[D == 0]
dy_treated = dy[D == 1]
dy_control = dy[D == 0]
# 为每个处理单位找最近邻对照
dist = cdist(ps_treated.reshape(-1, 1), ps_control.reshape(-1, 1))
nn_idx = dist.argmin(axis=1)
matched_control = dy_control[nn_idx]
psm_did = (dy_treated - matched_control).mean()
print(f"真实 ATT = {tau_true:.3f}")
print(f"朴素差分(有偏) = {naive:.3f}")
print(f"PSM-DID(1 近邻) = {psm_did:.3f}")
# 可视化倾向得分分布
fig, ax = plt.subplots(1, 2, figsize=(12, 5))
ax[0].hist(ps[D == 1], bins=30, alpha=0.55, color='#003153', label='处理组')
ax[0].hist(ps[D == 0], bins=30, alpha=0.55, color='#AE0B2A', label='对照组')
ax[0].set_xlabel('估计倾向得分 P(Z)', fontsize=12)
ax[0].set_ylabel('频数', fontsize=12)
ax[0].set_title('倾向得分分布(重叠检查)', fontsize=13)
ax[0].legend(fontsize=11)
ax[0].grid(alpha=0.3)
ax[1].bar(['朴素差分', 'PSM-DID', '真实值'],
[naive, psm_did, tau_true],
color=['#AE0B2A', '#003153', '#00A8CC'],
edgecolor='white')
ax[1].axhline(tau_true, color='gray', linestyle='--', alpha=0.6)
ax[1].set_ylabel('ATT 估计', fontsize=12)
ax[1].set_title('三种估计量对比', fontsize=13)
ax[1].grid(axis='y', alpha=0.3)
plt.tight_layout()
plt.show()
```
# 第二部分:半参数 DiD {#sec-semi}
Abadie (2005, *ReStud*) 给出了一个*权重形式*的 ATT 表达,既不必显式选择近邻,也不要求协变量进入线性回归。其核心恒等式:
$$E[Y_{i1}^1 - Y_{i1}^0 \mid \boldsymbol{X}, D_{i1} = 1] = E[\rho_0 (Y_{i1} - Y_{i0}) \mid \boldsymbol{X}]$$
其中权重为
$$\rho_0 = \frac{D_{i1} - P(D_{i1} = 1 \mid \boldsymbol{X})}{P(D_{i1} = 1 \mid \boldsymbol{X}) \cdot [1 - P(D_{i1} = 1 \mid \boldsymbol{X})]}$$
取期望得到
$$ATT = E\left[\frac{Y_{i1} - Y_{i0}}{P(D = 1)} \cdot \frac{D_{i1} - P(D_{i1} = 1 \mid \boldsymbol{X})}{1 - P(D_{i1} = 1 \mid \boldsymbol{X})}\right]$$
直觉:用倾向得分对*差分后的结果*加权,让对照组被重新加权成与处理组可比的反事实。这与 IPW(Inverse Probability Weighting)同源。
### 子群 ATT
对子集 $\boldsymbol{X}^{sub}_i$ 的 ATT 可以通过求解如下最小化问题得到:
$$\hat{\delta}(\boldsymbol{X}^{sub}) = \arg\min_\theta E\{P(D_{i1} = 1 \mid \boldsymbol{X}) \cdot [\rho_0 (Y_{i1} - Y_{i0}) - g(\boldsymbol{X}^{sub}; \theta)]^2\}$$
*估计步骤*:
1. 估计倾向得分 $\hat{P}(D = 1 \mid \boldsymbol{X})$(用 probit 或 logit);
2. 把拟合值代入样本类比式,得到 $\widehat{ATT}$ 或其子群拓展。
Stata 命令 `absdid` 直接封装了这一流程。手工实现也很简单:
```stata
use simdata_did1.dta, clear
qui logit D x if t == 1
predict pr1 if t == 1
egen pD = mean(D) if t == 1
tsset id t
gen ab_diff = (y - l.y)/pD * ((D - pr1)/(1 - pr1)) if t == 1
qui sum ab_diff if t == 1
display "半参数 ATT = " r(mean) ", SE = " r(sd)
* 或直接调用 absdid
g dy = y - l.y
absdid dy, tvar(D) xvar(x) sle
```
真实 ATT = 0.15,半参数估计值应该落在 0.14–0.16 附近。
# 第三部分:合成 DiD {#sec-sdid}
## 合成控制法:背景
合成控制法(SCM)由 Abadie & Gardeazabal (AER 2003) 首创,Abadie, Diamond & Hainmueller (JASA 2010) 给出完整统计理论。核心思想是:当只有一个(或极少数)处理单位时,用对照池的*凸组合*构造合成反事实:
$$\hat{Y}_{1t}^{SCM} = \sum_{j=2}^{J+1} \omega_j^* \cdot Y_{jt}$$
权重 $\omega_j^* \geq 0$,$\sum_j \omega_j^* = 1$,通过最小化处理前结果路径的匹配距离来选择:
$$\min_\omega (X_1 - X_0 \omega)^\top V (X_1 - X_0 \omega)$$
**经典案例:加州 Proposition 99**。1988 年加州通过控烟法案大幅提高烟草税。用其他 38 个州合成加州:Utah 33%、Nevada 23%、Montana 20%、Colorado 14%、Connecticut 10%。1989–2000 年实际加州的人均香烟消费比合成反事实低约 26 包/年。
## 合成 DiD 的目标函数
Arkhangelsky et al. (AER 2021) 提出合成 DiD(SDiD),同时引入*单位权重* $\omega_i^{sc}$ 和*时期权重* $\lambda_t^{sc}$:
$$(\hat{\delta}^{sdid}, \hat{\mu}, \hat{\alpha}_i, \hat{\beta}_t) = \arg\min \sum_i \sum_t (Y_{it} - \mu - \alpha_i - \beta_t - \delta D_{it})^2 \cdot \omega_i^{sc} \cdot \lambda_t^{sc}$$
**直觉**
- *像 SCM*:单位权重让处理前路径匹配 → 弱化对平行趋势的依赖;
- *像 DiD*:保留 TWFE 结构 → 允许大面板渐近推断、允许多个处理单位。
DiD 是 SDiD 的特例(所有权重相等);SCM 也是 SDiD 的特例(只有单位权重、不考虑时期权重)。
### 何时用 SDiD
- 处理组不止一个,但个数有限且平行趋势不太放心;
- 对照池丰富;
- 需要 bootstrap / jackknife 推断而非置换检验;
### Stata 实战:SDiD(Lab §4)
```stata
use simdata_did1.dta, clear
g x2 = x^2
* 合成 DiD(自带单位 + 时期权重)
sdid y id t D, covariates(x x2, projected) ///
vce(bootstrap) seed(123)
* 提取单位权重 omega(仅存在于 t==1 且 D==0 的对照单位)
g omega = .
qui sum D if t==1 & D==0
qui forv i = 1/`r(N)' {
scalar uw = e(omega)[`i', 1]
scalar ctr_id = e(omega)[`i', 2]
replace omega = uw if id == ctr_id
}
* 权重 × 协变量的投影:合成样本的代表性
g x_proj = x * omega
ta t, sum(x_proj)
```
**权重诊断**是 SDiD 的*核心透明度*:权重集中(少数对照单位承担主要作用)→ 可解释性强;权重分散 → 更接近 TWFE,平行趋势要求更严。论文应常规地报告单位权重分布图。
# 第四部分:交错处理下的 TWFE 陷阱 {#sec-stag}
## 交错处理是常态
中国自贸区从 2013 年上海开始、2015 年扩至闽粤津、2017-2020 年再陆续覆盖其他省份;美国无过错离婚法在 37 个州于 1969–1985 年间分批通过;企业数字化转型则完全由企业内生决定时点。交错处理(staggered treatment)是常态而非例外。
最直觉的做法是把 TWFE 直接扩展:
$$Y_{it} = \alpha_i + \lambda_t + \delta D_{it} + \varepsilon_{it}$$
形式上与 2×2 一样。但 Goodman-Bacon (2021, *JoE*) 证明,在交错处理下这个 $\hat{\delta}$ 的含义已经*面目全非*。
## Goodman-Bacon 分解定理
**定理**。设数据包含 $k = 1, \ldots, K$ 个按处理时点排序的组群。TWFE 估计量等于*所有可能的 2×2 DiD*的加权平均:
$$\hat{\delta}^{TWFE} = \sum_{j \neq U} s_{jU} \hat{\beta}_{jU}^{2 \times 2} + \sum_{k < \ell} s_{k\ell} \left[\mu_{k\ell} \hat{\beta}_{k\ell}^{2\times 2, k} + (1 - \mu_{k\ell}) \hat{\beta}_{k\ell}^{2\times 2, \ell}\right]$$
其中三种 2×2 DiD 估计量是
$$\hat{\beta}_{jU}^{2\times 2} = (\bar{Y}_j^{post(j)} - \bar{Y}_j^{pre(j)}) - (\bar{Y}_U^{post(j)} - \bar{Y}_U^{pre(j)})$$
$$\hat{\beta}_{k\ell}^{2\times 2, k} = (\bar{Y}_k^{mid(k,\ell)} - \bar{Y}_k^{pre(k)}) - (\bar{Y}_\ell^{mid(k,\ell)} - \bar{Y}_\ell^{pre(k)})$$
$$\hat{\beta}_{k\ell}^{2\times 2, \ell} = (\bar{Y}_\ell^{post(\ell)} - \bar{Y}_\ell^{mid(k,\ell)}) - (\bar{Y}_k^{post(\ell)} - \bar{Y}_k^{mid(k,\ell)})$$
$K$ 个时点组产生 $K^2$ 个 2×2 DiD:$K$ 个“处理 vs 从未”比较 + $K(K-1)$ 个“处理 vs 已处理”比较。权重之和为 1,但*可能为负*。
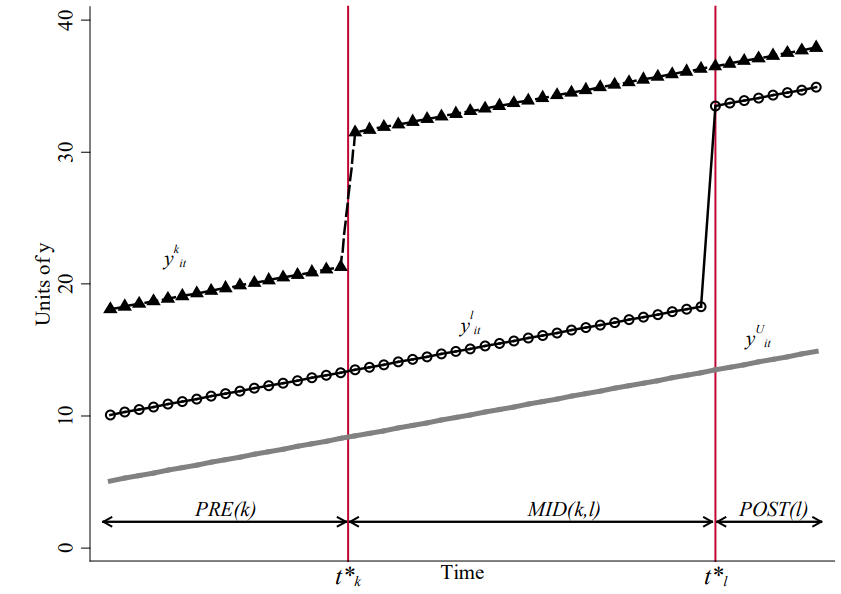{#fig-dd3by3}
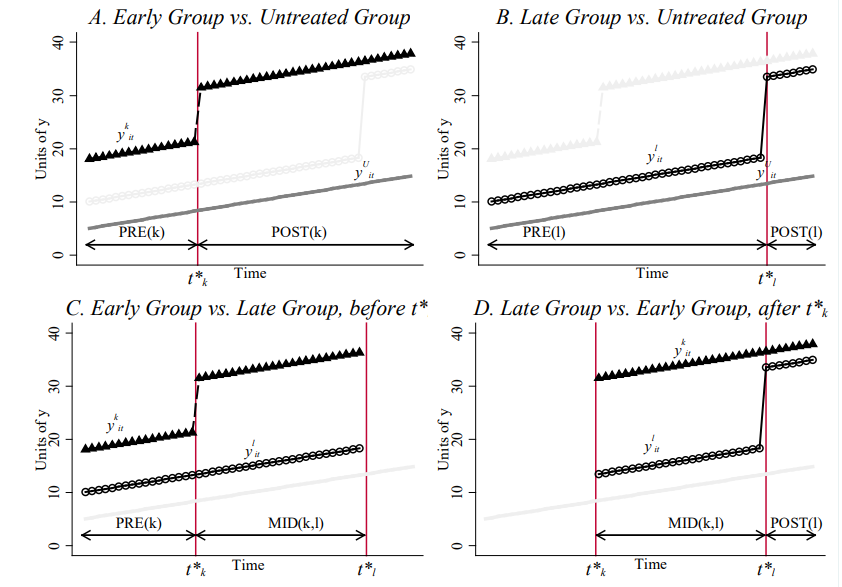{#fig-all-dd}
## 权重公式
每个 2×2 DiD 的权重由*子样本大小的平方*和*固定效应调整后处理变量的方差*共同决定:
$$s_{jU} = \frac{(n_j + n_U)^2 \hat{V}_{jU}^D}{\hat{V}^D}$$
$$s_{k\ell}^k = \frac{[(n_k + n_\ell)(1 - \bar{D}_\ell)]^2 \hat{V}_{k\ell}^{D,k}}{\hat{V}^D}, \quad s_{k\ell}^\ell = \frac{[(n_k + n_\ell) \bar{D}_k]^2 \hat{V}_{k\ell}^{D,\ell}}{\hat{V}^D}$$
样本的*子样本方差*在两个时点组规模相近、或处理时点接近时间窗口中部时最大——这些比较的权重就最大。这意味着 TWFE 会*放大*规模相当、时点居中的比较,*缩小*边缘样本的影响。
## VWATT-VWCT-ΔATT 分解
Goodman-Bacon 进一步证明 TWFE 系数可以解释为:
$$\hat{\delta}^{TWFE} = \underbrace{VWATT}_{\text{方差加权 ATT}} - \underbrace{VWCT}_{\text{方差加权共同趋势}} + \underbrace{\Delta ATT}_{\text{偏误项}}$$
- $VWATT = \sum_{k \neq U} \sigma_{kU} ATT_k^{post(k)} + \sum_{k < \ell} [\sigma_{k\ell}^k ATT_k^{mid(k,\ell)} + \sigma_{k\ell}^\ell ATT_\ell^{post(\ell)}]$
- $VWCT = 0$ 若平行趋势成立
- $\Delta ATT = \sum_{k<\ell} \sigma_{k\ell} [ATT_k^{post(\ell)} - ATT_k^{mid(k,\ell)}]$
**负权重的根源**。当早处理组 $k$ 在晚处理组 $\ell$ 的“post”期继续累积效应($ATT_k^{post(\ell)} > ATT_k^{mid(k,\ell)}$)时,$\Delta ATT > 0$——TWFE 把这部分“累积”误读为“控制组的趋势下降”,从而让新处理组 $\ell$ 的系数被下拉。极端情况下,$\hat{\delta}^{TWFE}$ 可以与真实平均 ATT *符号相反*。
**解读 TWFE 的三条结论**:
1. 即使 $\Delta ATT = 0$(效应在时间上不变),权重仍是样本份额与处理方差的函数,$VWATT$ 一般不等于样本 ATT;
2. 效应在时间上变化($\Delta ATT \neq 0$)时,TWFE 给出实际不可信的估计;
3. *始终处理组*作为新处理组的对照,最容易引发偏误——Roth 等人的经验是*先检查 Bacon 分解再报告 TWFE 系数*。
## 案例:无过错离婚法对女性自杀率的影响
Stevenson & Wolfers (2006) 利用 37 个州无过错离婚法的*分批通过*作为自然变异。Goodman-Bacon (2021) 重新审视这一研究。事件研究估计显示后处理期的平均效应 $\approx -4.92$,但 TWFE 系数仅为 $-3.08$。差距从何而来?
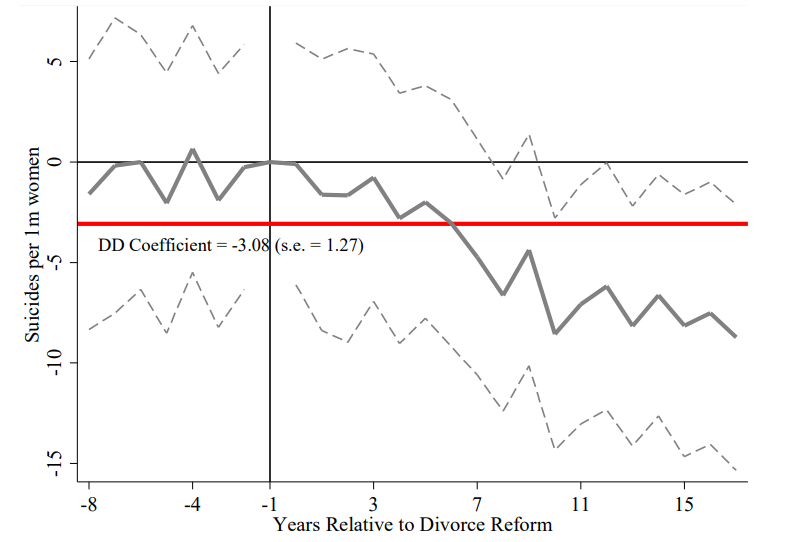{#fig-divorce-es}
`bacondecomp` 命令给出完整的权重分解:
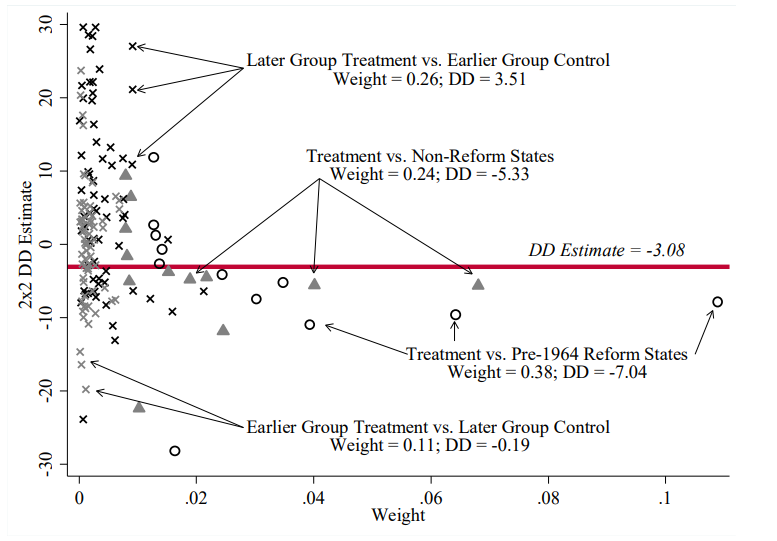{#fig-divorce-decomp}
- 时点比较权重总和:$s_{k\ell}^k + s_{k\ell}^\ell = 0.26 + 0.11 = 0.37$(这部分有偏误)
- 处理-从未对照权重:$s_{jU} = 0.38 + 0.24 = 0.62$
- *排除“晚 vs 早”*:ATT = -5.45
- *再排除“始终处理 vs 新处理”*:ATT = -3.71
## Stata 实战:Bacon 分解(Lab §5)
配套实验室使用 Borusyak et al. (2021) 的交错 DGP 模板:
```stata
* ===== 交错处理 DGP =====
clear all
set seed 10
global T = 15
global I = 500
set obs `=$I * $T'
gen i = int((_n - 1)/$T) + 1
gen t = mod((_n - 1), $T) + 1
tsset i t
gen Ei = ceil(runiform() * 7) + $T - 6 if t == 1 // 首次处理年份 10..16
bys i (t): replace Ei = Ei[1]
gen K = t - Ei // 相对处理期
gen D = K >= 0 & Ei != .
gen tau = cond(D == 1, (t - 12.5), 0) // 动态效应
gen Y = i + 3*t + tau*D + rnormal()
* Bacon 分解
qui xtreg Y D i.t, fe robust
ssc install bacondecomp, replace
bacondecomp Y D, ddetail
```
典型输出会展示每种 2×2 DiD 的权重和估计值。在这个 DGP 下,“晚 vs 早”比较的权重约 10%,但估计值为负——正是 Goodman-Bacon 警告的 negative weight 现象。
# 第五部分:现代 DiD 估计量 {#sec-modern}
## 共同原则
四个现代方法的共同修复思路:
1. *按组群-时期* $(g, t)$ 分别估计 $ATT(g, t)$;
2. *对照组*只使用“从未处理”或“尚未处理”的单位;
3. 按研究问题聚合——整体 ATT、事件时间 ATT、或组群 ATT。
## Wooldridge (2021) 的 Mundlak 视角
Wooldridge 给出了一个优雅的诊断:“TWFE 并非估计方法本身有问题,问题在于它被应用到一个对处理效应异质性施加强假设的模型上。” 他的修复办法是把*完整的组群-时期交互项*放入回归:
$$E(Y_{it} \mid \boldsymbol{G}) = \eta + \sum_{g=2}^T \lambda_g G_{ig} + \sum_{s=2}^T \theta_s \mathbf{1}(t = s) + \sum_{g=2}^T \sum_{s=g}^T \tau_{g,s}(G_{ig} \cdot \mathbf{1}(t = s))$$
**识别假设**:
- *无预期*:$E[Y_t(g) - Y_t(\infty) \mid \boldsymbol{G}] = 0$ 当 $t < g$;
- *平行趋势*:$E[Y_t(\infty) - Y_1(\infty) \mid \boldsymbol{G}] = E[Y_t(\infty) - Y_1(\infty)] \equiv \theta_t$。
Mundlak 回归直接用 POLS 估计上述交互项;$\hat{\tau}_{g,s}$ 就是 $ATT(g, s)$。
## Sun & Abraham (2021, JoE)
SA 的关键洞察:*传统的事件研究回归*
$$Y_{it} = \alpha_i + \lambda_t + \sum_e \beta_e \mathbf{1}(t - g_i = e) + \varepsilon_{it}$$
的系数 $\beta_e$ 在异质处理效应下*不是*事件时间 ATT 的平均——它被“已处理组的污染”扭曲。SA 的修复:把事件时间虚拟变量*与组群虚拟变量交互*:
$$Y_{it} = \alpha_i + \lambda_t + \sum_g \sum_{e \neq 0} \delta_{g,e} G_{ig} \cdot \mathbf{1}(t - g + 1 = e) + \varepsilon_{it}$$
$\hat{\delta}_{g,e}$ 一致估计 $ATT(g, g+e-1)$。报告的事件研究系数是按组群规模的加权平均:
$$\hat{\theta}(e) = \sum_g \hat{w}_g \hat{\delta}_{g, e+1}$$
**优势**:仍在回归框架内,协变量易加入;
**劣势**:对“从未处理”或“最后处理”组群的假设更敏感。
### Stata:`eventstudyinteract`
```stata
sum Ei
gen lastcohort = Ei == r(max)
forv l = 0/5 { gen L`l'event = (K == `l') }
forv l = 1/14 { gen F`l'event = (K == -`l') }
drop F1event // 基准期 k = -1 设为 0
eventstudyinteract Y L*event F*event, vce(cluster i) ///
absorb(i t) cohort(Ei) control_cohort(lastcohort)
matrix sa_b = e(b_iw)
matrix sa_v = e(V_iw)
```
## Callaway & Sant'Anna (2021, JoE)
CS 放弃回归框架,直接在*非参数*层面定义 $ATT(g, t)$:
$$ATT(g, t) = E[Y_t(g) - Y_t(\infty) \mid G_g = 1]$$
*两种平行趋势假设*:
- **从未处理对照**:$E[Y_t^0 - Y_{t-1}^0 \mid G_g = 1] = E[Y_t^0 - Y_{t-1}^0 \mid C = 1]$
- **尚未处理对照**:$E[Y_t^0 - Y_{t-1}^0 \mid G_g = 1] = E[Y_t^0 - Y_{t-1}^0 \mid D_s = 1]$ ($s > t$)
对应两种 ATT 估计量:
$$\widehat{ATT}^{never}(g, t) = \frac{\sum_i G_{ig}(Y_{it} - Y_{i,g-1})}{\sum_i G_{ig}} - \frac{\sum_i C_i (Y_{it} - Y_{i,g-1})}{\sum_i C_i}$$
$$\widehat{ATT}^{ny}(g, t) = \frac{\sum_i G_{ig}(Y_{it} - Y_{i,g-1})}{\sum_i G_{ig}} - \frac{\sum_i C_i(1 - G_{ig})(Y_{it} - Y_{i,g-1})}{\sum_i C_i(1 - G_{ig})}$$
### Stata:`csdid`
```stata
gen gvar = cond(Ei == ., 0, Ei)
csdid Y, ivar(i) time(t) gvar(gvar) notyet
estat event, estore(cs) // 事件研究系数 + 95% CI
estat simple // 简单 ATT 聚合
```
## de Chaisemartin & D'Haultfoeuille (2020, AER)
dCdH 关注*即期处理效应*:
$$\hat{\delta}^{dCdH} = \sum_{g=2}^T \hat{P}(G_g = 1 \mid \text{Treated for period} \geq 1) \cdot \widehat{ATT}(g, g)$$
其中
$$\widehat{ATT}^{ny}(g, t) = \frac{\sum_i G_{ig}(Y_{it} - Y_{i,g-1})}{\sum_i G_{it}} - \frac{\sum_i (1 - D_{it})(1 - G_{ig})(Y_{it} - Y_{i,g-1})}{\sum_i (1 - D_{it})(1 - G_{ig})}$$
dCdH 提供了动态扩展(`dynamic(F)`)与安慰剂检验(`placebo(P)`),推断基于 bootstrap。
### Stata:`did_multiplegt`
```stata
did_multiplegt Y i t D, robust_dynamic dynamic(5) ///
placebo(5) breps(100) cluster(i)
matrix dcdh_b = e(estimates)
matrix dcdh_v = e(variances)
```
## Borusyak, Jaravel & Spiess (2024, ReStud)
BJS 的插补思想:
1. 用*未处理*观测 $(D_{it} = 0)$ 估计 TWFE 模型的 $\hat{\alpha}_i, \hat{\lambda}_t$;
2. 对处理观测插补反事实:$\hat{Y}_{it}(0) = \hat{\alpha}_i + \hat{\lambda}_t$;
3. 单位-时期效应:$\hat{\tau}_{it} = Y_{it} - \hat{Y}_{it}(0)$;
4. 按需聚合。
**BJS 的卖点**:
- 在齐次方差下效率最优(BLUE);
- 推断基于*随机化*——小样本可靠,不依赖渐近理论;
- 自带对预趋势的正式检验。
### Stata:`did_imputation`
```stata
did_imputation Y i t Ei, allhorizons pretrend(5)
estimates store bjs
```
## 四种方法对比
| 维度 | *CS* | *SA* | *dCdH* | *BJS* |
|:---|:---|:---|:---|:---|
| 框架 | 非参数 | 回归(IW) | 匹配式 | 插补 |
| 关注对象 | $ATT(g, t)$ | $\delta_{g, e}$ | 即期 ATT | 所有 $(i, t)$ |
| 对照组 | 从未 / 尚未 | 最后处理 | 从未 + 尚未 | 所有未处理观测 |
| 协变量 | 需显式加权 | 直接入回归 | 需显式加权 | 直接入回归 |
| 小样本 | Bootstrap | 渐近 | 渐近 | 正式随机化 |
**实务建议**
1. 主力方法用 *CS*(以 `csdid` 出默认结果);
2. 事件研究图用 *SA*(以 `eventstudyinteract` 出带 CI 的图);
3. 关注即期用 *dCdH*(以 `did_multiplegt` 出 robust_dynamic);
4. 效率导向用 *BJS*(以 `did_imputation` 作为稳健性)。
至少报告其中两种,并说明结果一致或不一致的原因。
## 五种估计量在同一 DGP 上的对比
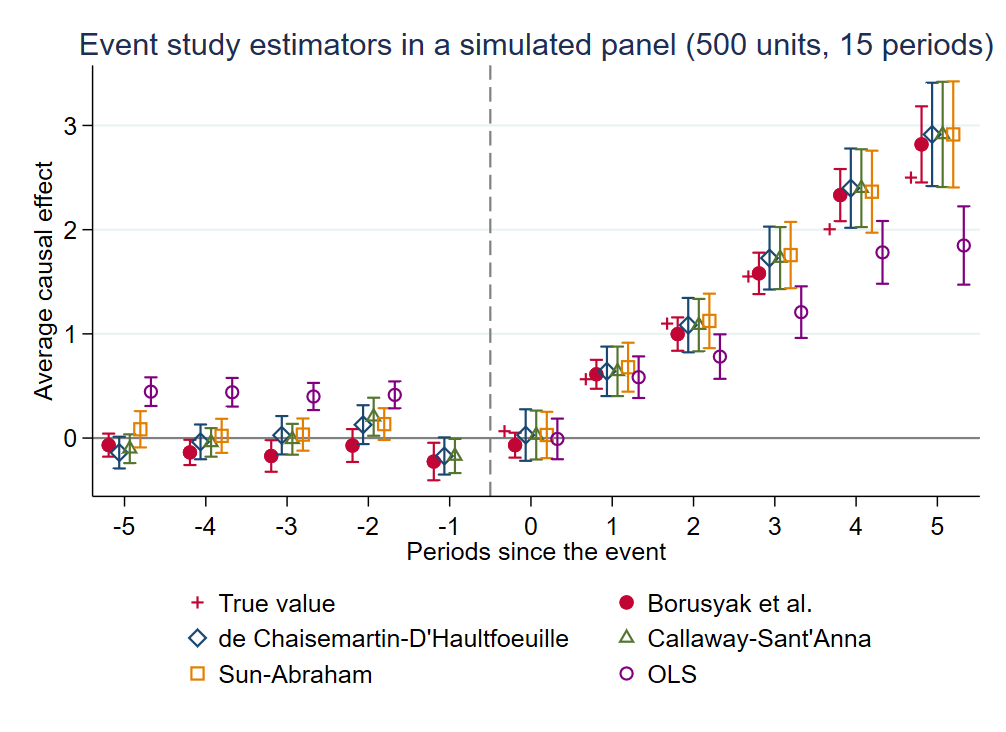{#fig-five-estimators}
这张图来自配套实验室 `L4-Diff-in-Diffs-More.ipynb` 的最后一个单元格。500 单位 × 15 期,处理时点在 10-16 年间随机分配,真实动态效应 $\tau_{it} = t - 12.5$ 当 $t \geq E_i$。OLS 事件研究在 post 期系统性偏低;四种现代估计量都与真值基本重合。
### R 语言对照
```r
library(did) # Callaway-Sant'Anna
library(fixest) # Sun-Abraham via sunab()
library(DIDmultiplegt)
library(didimputation)
# CS
atts <- att_gt(yname = "Y", tname = "t", idname = "i",
gname = "Ei", data = df, control_group = "notyettreated")
aggte(atts, type = "dynamic")
# SA via fixest
es <- feols(Y ~ sunab(Ei, t) | i + t, data = df, cluster = ~i)
iplot(es)
# dCdH
did_multiplegt(df, "Y", "i", "t", "D",
robust_dynamic = TRUE, dynamic = 5, placebo = 5)
# BJS
did_imputation(data = df, yname = "Y", gname = "Ei",
tname = "t", idname = "i", horizon = TRUE)
```
# 第六部分:当历史重要——Imai-Kim-Wang {#sec-history}
## 动态经济变量
许多经济变量天然具有*自回归结构*:当期值依赖过去值。典型例子:
$$Y_{it} = \rho Y_{i,t-1} + X_{it}^\prime \alpha + \lambda_t + \mu_i + \varepsilon_{it}$$
迭代展开:
$$Y_{it} = \rho^t Y_{i0} + \sum_{s=0}^{t} \rho^s (X_{i,t-s}^\prime \alpha + \lambda_{t-s} + \mu_i + \varepsilon_{i,t-s})$$
当处理 $D_{it}$ 在 $t$ 期启动并长期维持时,效应会通过 $\rho$ 传递到后续所有期。
**Cobb-Douglas 生产函数** 是一个经典例子。生产率冲击自相关 $v_{it} = \rho v_{i,t-1} + e_{it}$,产出方程就带上了滞后项:
$$y_{it} = \rho y_{i,t-1} + (\beta_k k_{it} - \rho \beta_k k_{i,t-1}) + (\beta_l l_{it} - \rho \beta_l l_{i,t-1}) + (\gamma_t - \rho \gamma_{t-1}) + (1 - \rho)\eta_i + \xi_{it}$$
## 动态效应的三种尺度
假设处理在 $t = 0$ 启动并持续,真实瞬时效应为 $\delta$。
- *即期效应*:$\delta$
- *中期效应*($F$ 期后):$\delta \cdot \dfrac{1 - \rho^F}{1 - \rho}$
- *长期效应*:$\dfrac{\delta}{1 - \rho}$
一次性政策冲击在动态模型下会“回响”很久。报告哪种效应取决于研究问题:审稿人通常想看*动态效应全图*(event study);政策建议强调*长期效应*;成本效益分析对应*中期效应*(预算周期)。
## Ashenfelter (1978) 的 Dip
Ashenfelter 发现:接受职业培训的人,*在培训前*收入就出现一个“坑”——通常是因为失业、家庭变故等冲击触发了培训决定。如果直接用“培训前后”比较,这个 dip 会*夸大*培训的正效应。关键问题是:过去的 $Y_{i,t-1}$ 成为*时变混杂因子*,无法被固定效应吸收。
修正后的平行趋势假设:
$$E[Y_{it}(0) - Y_{i,t-1}(0) \mid D_{it}, \{Y_{i,t-\ell}\}_{\ell=1}^L, X_{it}] = E[Y_{it}(0) - Y_{i,t-1}(0) \mid \{Y_{i,t-\ell}\}_{\ell=1}^L, X_{it}]$$
在实务中这意味着*控制滞后因变量*,或使用 Imai, Kim & Wang (2021) 的面板匹配方法。
## 政策不稳定时的处理定义
$$
\begin{array}{c|cccc|l}
& t=1 & t=2 & t=3 & t=4 & \text{类型} \\ \hline
i=1 & 0 & 1 & 1 & 1 & \text{稳定处理} \\
i=2 & 0 & 1 & 0 & 1 & \text{不稳定 I} \\
i=3 & 0 & 1 & 1 & 0 & \text{不稳定 II} \\
i=4 & 0 & 0 & 1 & 0 & \text{不稳定 III} \\
i=5 & 0 & 0 & 0 & 0 & \text{从未处理}
\end{array}
$$
“什么是处理?”这个问题在政策不稳定时变得非平凡。三种应对:
1. *强制吸收态*:把曾被处理的单位都当作持续处理;
2. *进入 vs 退出分离*:ATT(进入效应)vs. ART(退出效应);
3. *按历史路径条件化*:Imai-Kim-Wang 的核心思路。
## ATT(F, L) 与 ART(F, L)
条件在相同的 $L$ 期历史上,Imai-Kim-Wang (2021, AJPS) 定义
$$ATT(F, L) = E\left[Y^{01}_{it+F}(L) - Y^{00}_{it+F}(L) \mid D_{it} = 1, D_{i,t-1} = 0\right]$$
$$ART(F, L) = E\left[Y^{10}_{it+F}(L) - Y^{11}_{it+F}(L) \mid D_{it} = 0, D_{i,t-1} = 1\right]$$
其中 $Y^{ab}_{it+F}(L)$ 表示当 $(D_{it}, D_{i,t-1}) = (a, b)$、$\{D_{i,t-\ell}\}_{\ell=2}^L$ 为任意给定历史时的潜在结果。
**$F$ 与 $L$ 的选择权衡**:
| 参数 | 大值的好处 | 大值的代价 |
|:---:|:---|:---|
| $L$ | 更可信的历史条件 → carryover 效应被允许 | 匹配样本缩小 → 估计精度下降 |
| $F$ | 长期效应的信息 | 单位可能切换处理状态 → 解释困难 |
## 面板匹配估计量
**匹配集合**
$$\mathcal{M}_{it}^{ATT} = \{(m, t) \mid m \neq i, D_{mt} = 0, (D_{m, t-\ell})_{\ell=1}^L = (D_{i, t-\ell})_{\ell=1}^L\}$$
$$\mathcal{M}_{it}^{ART} = \{(n, t) \mid n \neq i, D_{nt} = 1, (D_{n, t-\ell})_{\ell=1}^L = (D_{i, t-\ell})_{\ell=1}^L\}$$
只有*完全相同的历史路径*的单位才能进入匹配集合。
**估计量**
$$\widehat{ATT(F, L)} = \frac{1}{\sum G_{it}} \sum_{i, t} G_{it} \left[Y^{01}_{it+F} - Y^0_{it-1} - \sum_{m \in \mathcal{M}_{it}} w_{it}^m (Y_{m, t+F} - Y_{m, t-1})\right]$$
- $G_{it} = (D_{it} - D_{i,t-1}) \cdot \mathbb{1}\{|\mathcal{M}_{it}| \geq 1\}$:只有“处理刚发生变化且有匹配”时才记录;
- 权重 $w_{it}^m$ 可用 Mahalanobis 距离 或 PSM。
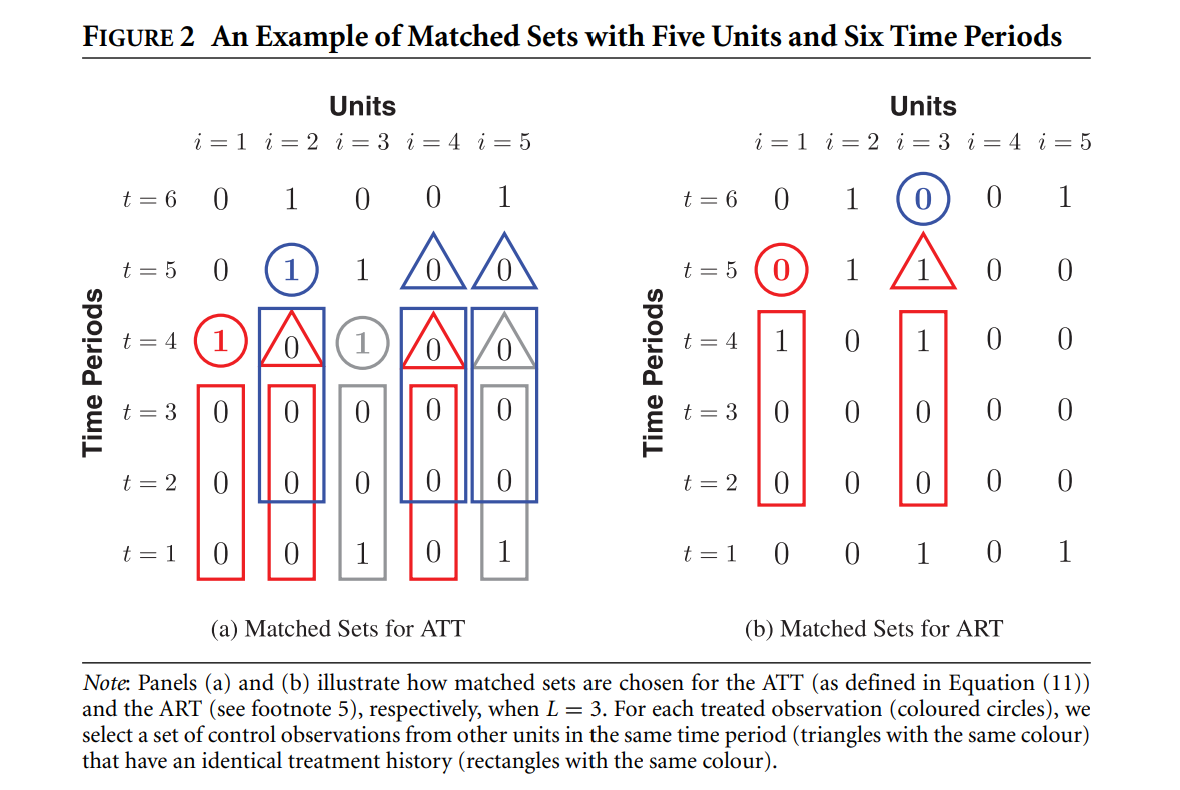{#fig-panel-matching}
R 实现:`PanelMatch` 包(Imai, Kim & Wang 自家维护)。
# 第七部分:实务指南 {#sec-practice}
## 平行趋势不放心时怎么办
**层层递进的应对**:
- 加入*丰富的协变量*:条件平行趋势;
- 强制*重叠条件*:每个处理单位存在 $\boldsymbol{X}$ 接近的对照;
- 检查*无预期*:处理前是否已有行为调整;
- 更换识别框架:IV、RD、SCM、CiC(quantile DiD)。
**不该做的事**:
- 简单“加个时间趋势”——往往吸收真实效应;
- 数据驱动地切样本——违反预注册;
- 说“通过了平行趋势检验”——这是错误措辞,只能说“未拒绝事前平行的假设”。
## DID 研究的标准清单
{#fig-checklist}
Roth, Sant'Anna, Bilinski & Poe (JoE 2023) 的综述给出了一份写在论文审稿评论里的“必做清单”。审稿人读完正文先对着这份清单挑你没做的事——论文提前在附录里主动回答,是最稳妥的策略。
## 软件工具
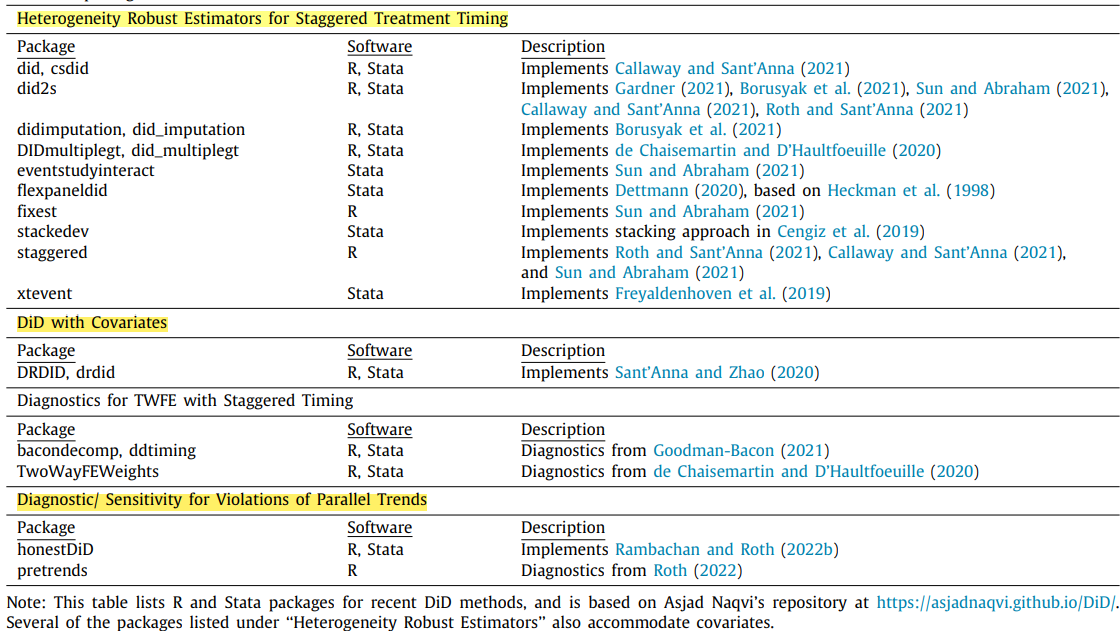{#fig-software}
- *Stata*:`csdid`、`eventstudyinteract`、`did_multiplegt`、`did_imputation`、`sdid`、`bacondecomp`、`honestdid`、`absdid`、`teffects`
- *R*:`did`、`fixest`(`sunab()`、`i()`)、`synthdid`、`DIDmultiplegt`、`didimputation`、`HonestDiD`、`PanelMatch`
# 总结 {#sec-summary}
## 本讲要点回顾
### 1. 匹配类 DiD 处理可观测混杂
PSM-DID(Heckman-Ichimura-Todd 1998)降维到倾向得分、做面板差分,允许选择依赖于潜在结果水平和时不变不可观测特征。半参数 DiD(Abadie 2005)用权重公式直接写出 ATT,不需要显式选择近邻。
### 2. 合成 DiD 融合 SCM 与 DiD
Arkhangelsky et al. (2021) 同时引入单位权重与时期权重,弱化平行趋势依赖,保留大面板推断。正在成为政策评估的默认方法。
### 3. TWFE 在交错处理下失灵
Goodman-Bacon (2021) 分解显示 TWFE 等于所有 2×2 DiD 的加权平均。“已处理组做对照”产生负权重,导致估计量符号错误。VWATT-VWCT-ΔATT 分解给出精确公式。
### 4. 四个现代估计量修复异质性问题
CS、SA、dCdH、BJS 都坚持“只用从未 / 尚未处理做对照”。至少报告两种,观察一致性。
### 5. Imai-Kim-Wang 处理动态与历史
按 $L$ 期历史路径条件化,分开估计 ATT(F, L)(进入)与 ART(F, L)(退出)。适用于不稳定政策、动态反事实。
## 关键公式汇总
| 概念 | 公式 | 说明 |
|:---|:---|:---|
| ATT 分解 | 观测差异 = ATT + 选择偏误 | 识别的核心挑战 |
| PSM-DID | $E[\Delta Y \mid \boldsymbol{X}, D=1] - E[\Delta Y \mid \boldsymbol{X}, D=0]$ | 在 $P(\boldsymbol{Z})$ 上匹配 |
| Abadie 权重 | $\rho_0 = \frac{D - P(X)}{P(X)[1-P(X)]}$ | 半参数 DiD |
| SDiD | $\min \sum (Y - \mu - \alpha_i - \beta_t - \delta D)^2 \omega_i^{sc} \lambda_t^{sc}$ | 单位 + 时期双权重 |
| Bacon 分解 | $\delta^{TWFE} = VWATT - VWCT + \Delta ATT$ | 交错 TWFE 的因果结构 |
| CS ATT | $ATT(g, t) = E[Y_t(g) - Y_t(\infty) \mid G_g = 1]$ | 组群-时期 ATT |
| SA IW | $Y_{it} = \sum_g \sum_e \delta_{g,e} G_{ig} \mathbf{1}(t-g+1=e) + \alpha_i + \lambda_t + \varepsilon_{it}$ | 交互加权 |
| BJS 插补 | $\hat{\tau}_{it} = Y_{it} - (\hat{\alpha}_i + \hat{\lambda}_t)$ | 用未处理观测估计 FE |
| Imai-Kim-Wang | $ATT(F, L)$, $ART(F, L)$ | $L$ 期历史条件化 |
## 下一讲预告
**第 5 周:因果机器学习**
当控制变量的维度与样本量可比(甚至超过)时,传统线性回归会失效。机器学习提供了*预测能力*,但*预测 ≠ 因果*。下一讲将覆盖:
1. 预测 vs. 因果:ML 能做什么、不能做什么;
2. LASSO 与高维控制变量选择——Post-LASSO 的陷阱;
3. Double / Debiased ML(DML)——Neyman 正交化 + 交叉拟合;
4. 因果森林与异质处理效应(HTE)估计;
5. 实战:`doubleml` / `econml` / `grf`。
## 课后思考
1. **PSM-DID 与 CS-DID 的选择**:如果你研究 2015 年某省自贸区试点对企业出口的影响,处理组只有一个省,对照池 30 个省,预处理期 5 年。你会优先用 PSM-DID、合成 DiD、还是 CS(每省作为一个组群)?三者在*识别假设*和*推断可靠性*上有什么关键差异?
2. **Goodman-Bacon 分解的直觉**:在你的研究领域中,选一个典型的“分批推进”的政策。用 Bacon 分解的视角分析:哪种 2×2 比较最可能产生偏误?是因为处理效应累积,还是因为处理组间的异质性?
3. **Imai-Kim-Wang 的应用场景**:面板匹配相对于 CS/SA 的最大优势是什么?*什么样的研究问题*必须使用面板匹配才能合理回答?请举一个具体例子(政策领域 + 数据结构)。
---
**联系方式**
- 邮箱:chenzhiyuan@rmbs.ruc.edu.cn
- 办公室:919
- Office Hours:邮件或微信预约
*本讲义基于 Heckman-Ichimura-Todd (ReStud 1998)、Abadie (ReStud 2005)、Abadie-Diamond-Hainmueller (JASA 2010)、Arkhangelsky et al. (AER 2021)、Goodman-Bacon (JoE 2021)、Callaway-Sant'Anna (JoE 2021)、Sun-Abraham (JoE 2021)、de Chaisemartin-D'Haultfoeuille (AER 2020)、Borusyak-Jaravel-Spiess (ReStud 2024)、Imai-Kim-Wang (AJPS 2021)、Roth et al. (JoE 2023) 与 Wooldridge (2021) 等文献整理而成。*








