经济与商务实证研究方法
第 2 周:计算基础与 AI 辅助可重复工作流
2026-04-25
AI 编程工具的谱系
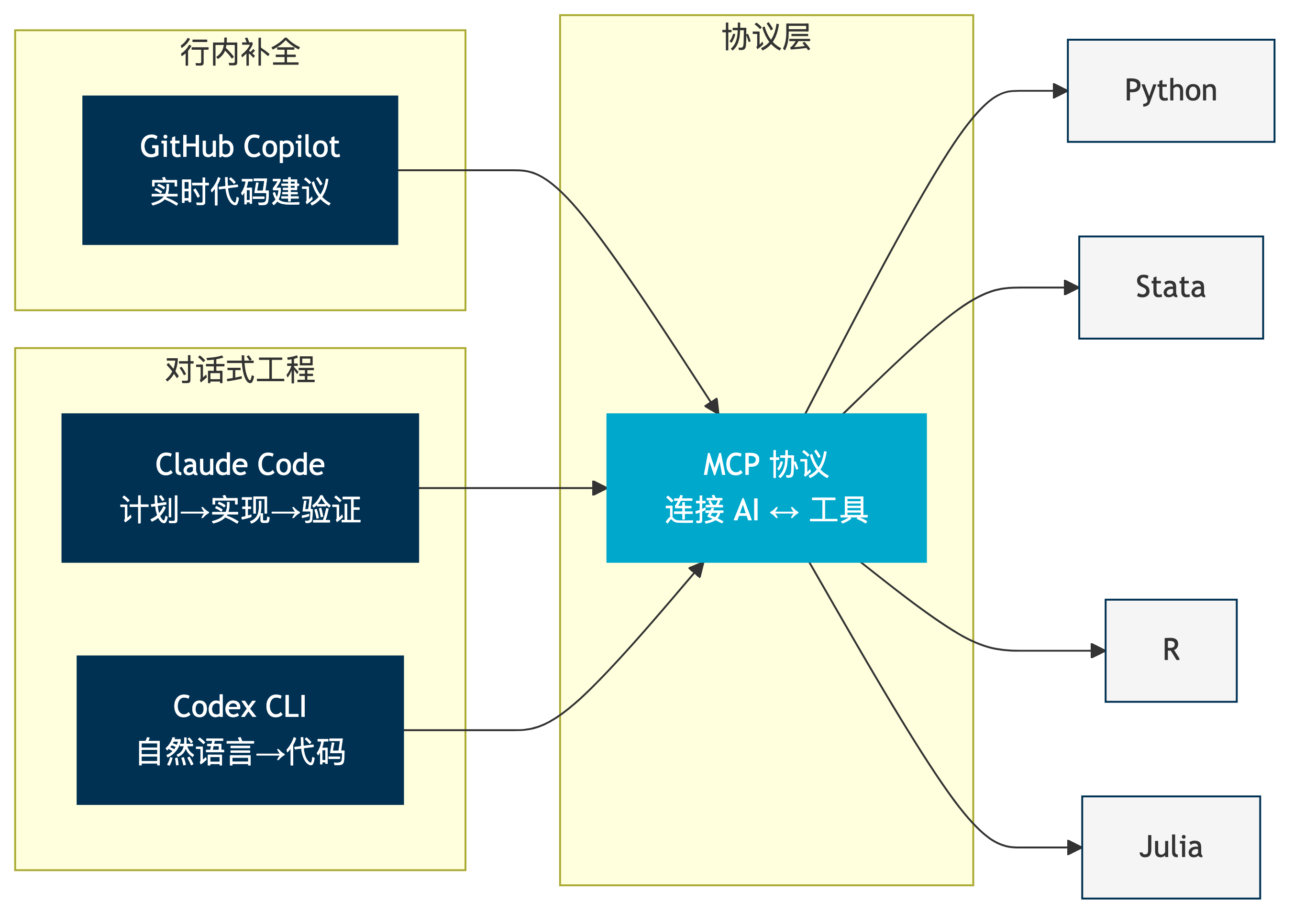
三类工具,三种交互模式——但都通过 MCP 协议连接到你的研究工具链。
MCP 架构:AI 如何调用你的工具
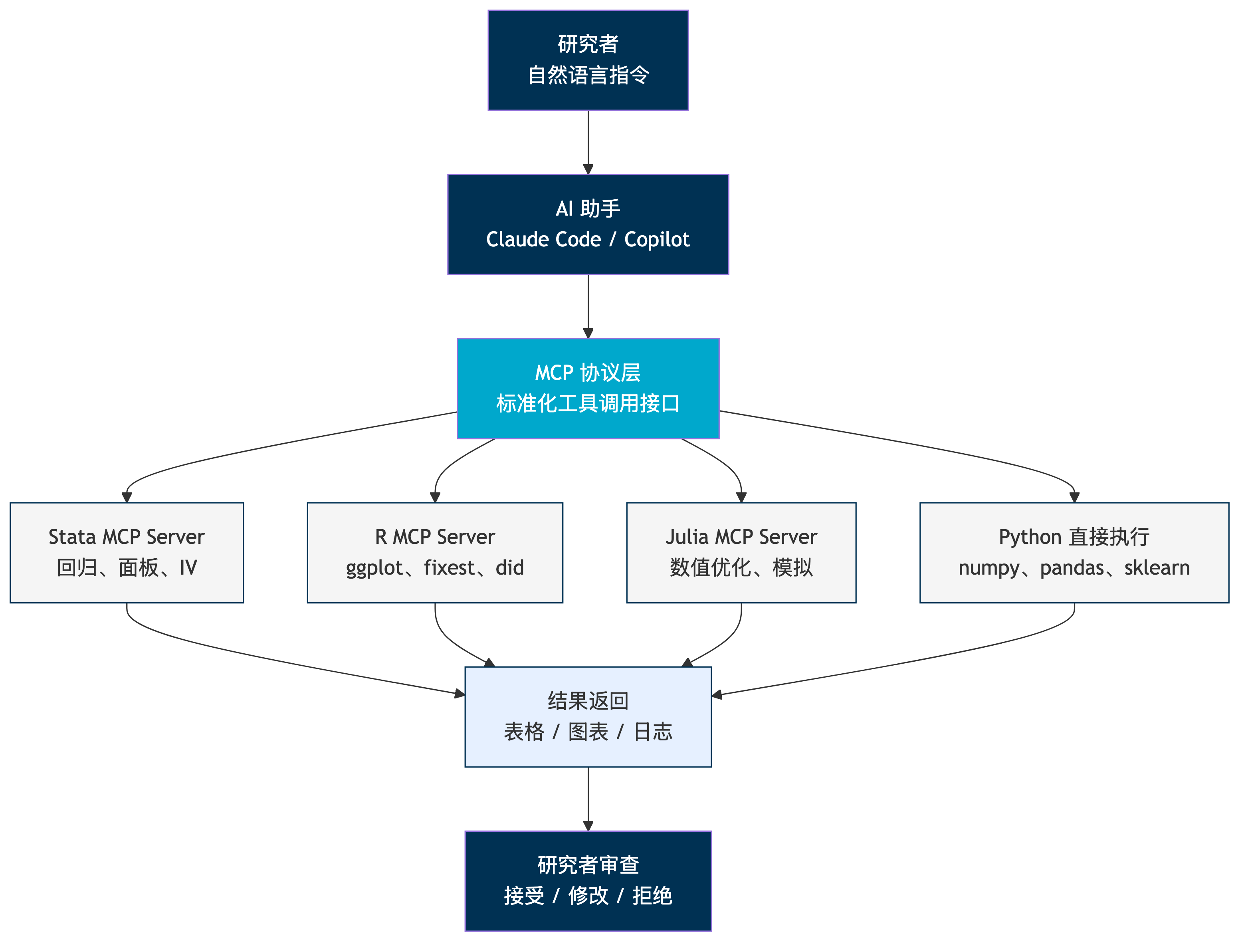
核心思想:研究者发出自然语言指令 → AI 翻译为工具调用 → MCP 路由到正确的执行引擎 → 结果返回给研究者审查。
例 1:抛硬币与大数定律
问题:抛一枚公平硬币,正面朝上的概率是 0.5。但如果只抛 10 次呢?
np.random.seed(2026)
n_flips = 10000
flips = np.random.binomial(1, 0.5, n_flips) # 1=正面, 0=反面
cumulative_prop = np.cumsum(flips) / np.arange(1, n_flips + 1)
fig, ax = plt.subplots(figsize=(12, 5))
ax.plot(range(1, n_flips + 1), cumulative_prop, color='#003153', linewidth=1)
ax.axhline(y=0.5, color='#00A8CC', linestyle='--', linewidth=2, label='真实概率 p = 0.5')
ax.set_xlabel('抛硬币次数', fontsize=14)
ax.set_ylabel('正面比例', fontsize=14)
ax.set_title('大数定律:样本越大,频率越接近概率', fontsize=16)
ax.set_xscale('log')
ax.legend(fontsize=13)
ax.set_ylim(0, 1)
plt.tight_layout()
plt.show()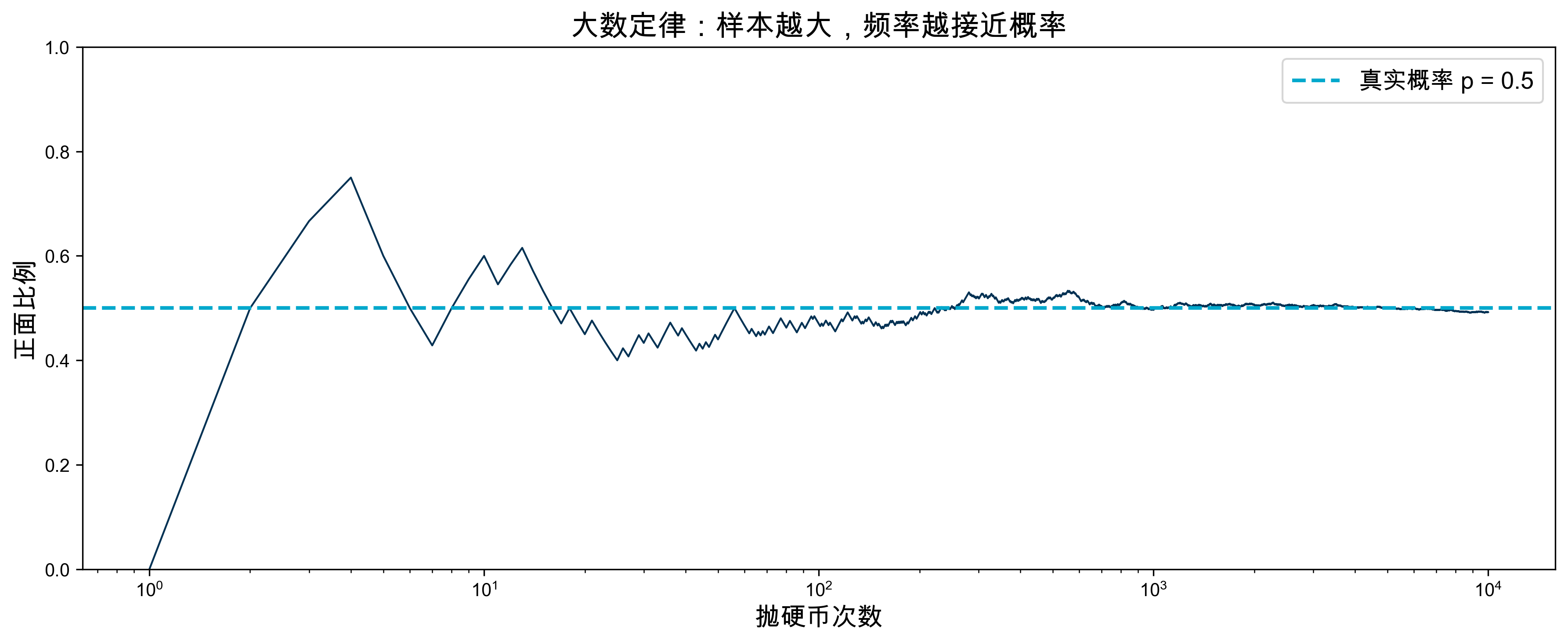
例 2:抽样分布与中心极限定理
问题:从一个非正态总体中抽样,\bar{X} 的分布是什么形状?
np.random.seed(42)
population = np.random.exponential(scale=2, size=100000) # 指数分布,偏态
sample_sizes = [5, 50, 500]
R = 5000 # 重复次数
fig, axes = plt.subplots(1, 3, figsize=(12, 5))
for idx, n in enumerate(sample_sizes):
means = [np.mean(np.random.choice(population, n)) for _ in range(R)]
axes[idx].hist(means, bins=20, color='#003153', alpha=0.7, edgecolor='white', density=True)
axes[idx].axvline(np.mean(population), color='#00A8CC', linestyle='--', linewidth=2)
axes[idx].set_title(f'n = {n}', fontsize=15)
axes[idx].set_xlabel('样本均值', fontsize=12)
if idx == 0:
axes[idx].set_ylabel('密度', fontsize=12)
fig.suptitle('中心极限定理:总体为指数分布(偏态),但样本均值趋于正态', fontsize=14)
plt.tight_layout()
plt.show()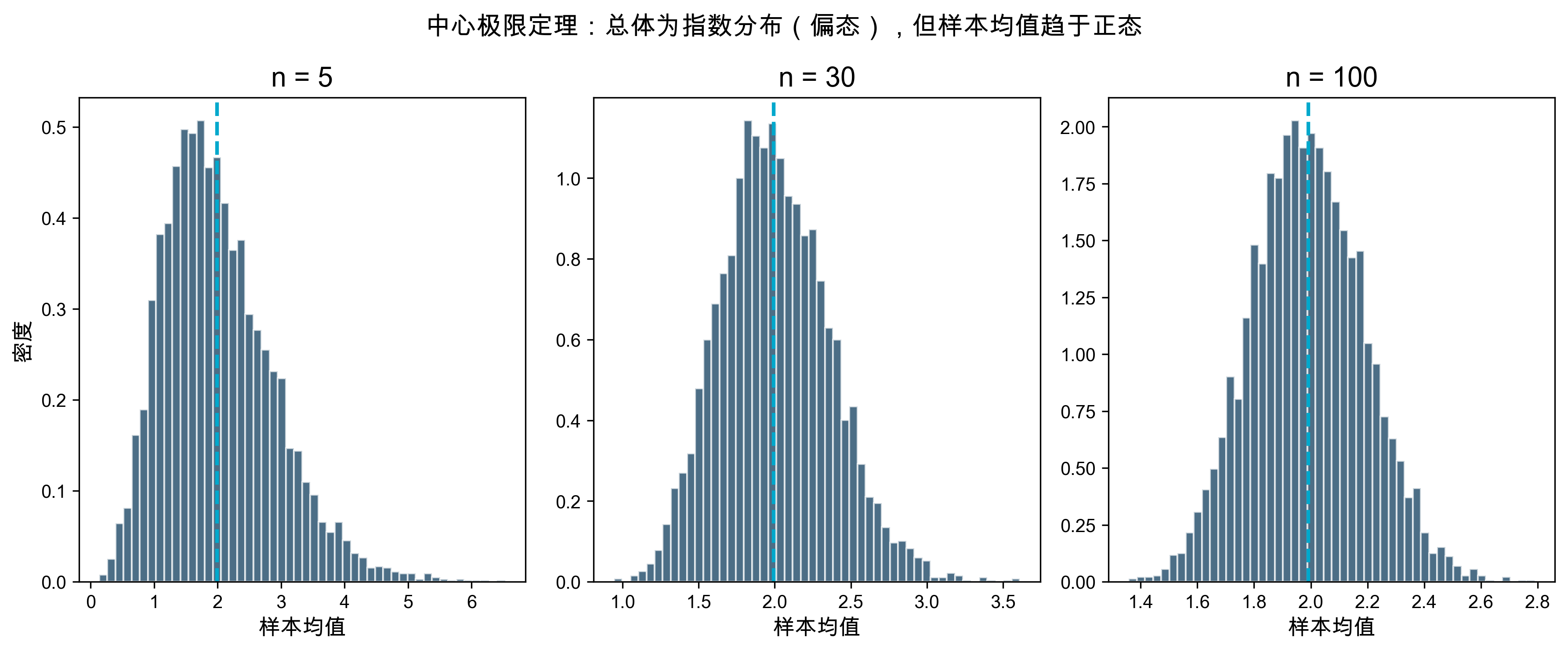
例 3:OLS 估计量的 Monte Carlo 验证
问题:OLS 的 \hat{\beta} 真的无偏吗?模拟验证。
np.random.seed(42)
beta_true = 2.0 # 真实参数
R = 300000 # 重复次数
n = 100 # 每次样本量
beta_hats = []
for _ in range(R):
x = np.random.normal(0, 1, n)
epsilon = np.random.normal(0, 1, n)
y = beta_true * x + epsilon # DGP: y = 2x + ε
beta_hat = np.sum(x * y) / np.sum(x ** 2) # OLS 公式
beta_hats.append(beta_hat)
beta_hats = np.array(beta_hats)
fig, ax = plt.subplots(figsize=(12, 5))
ax.hist(beta_hats, bins=60, color='#003153', alpha=0.7, edgecolor='white', density=True)
ax.axvline(beta_true, color='#00A8CC', linestyle='--', linewidth=2.5, label=f'真实值 β = {beta_true}')
ax.axvline(beta_hats.mean(), color='#e74c3c', linestyle=':', linewidth=2, label=f'MC 均值 = {beta_hats.mean():.4f}')
# set the x-axis limits to focus on the distribution around the true value
ax.set_xlim(1.5, 2.5)
ax.set_xlabel('β̂ 的值', fontsize=14)
ax.set_ylabel('密度', fontsize=14)
ax.set_title(f'OLS 估计量的抽样分布(R={R}, n={n})', fontsize=16)
ax.legend(fontsize=13)
plt.tight_layout()
plt.show()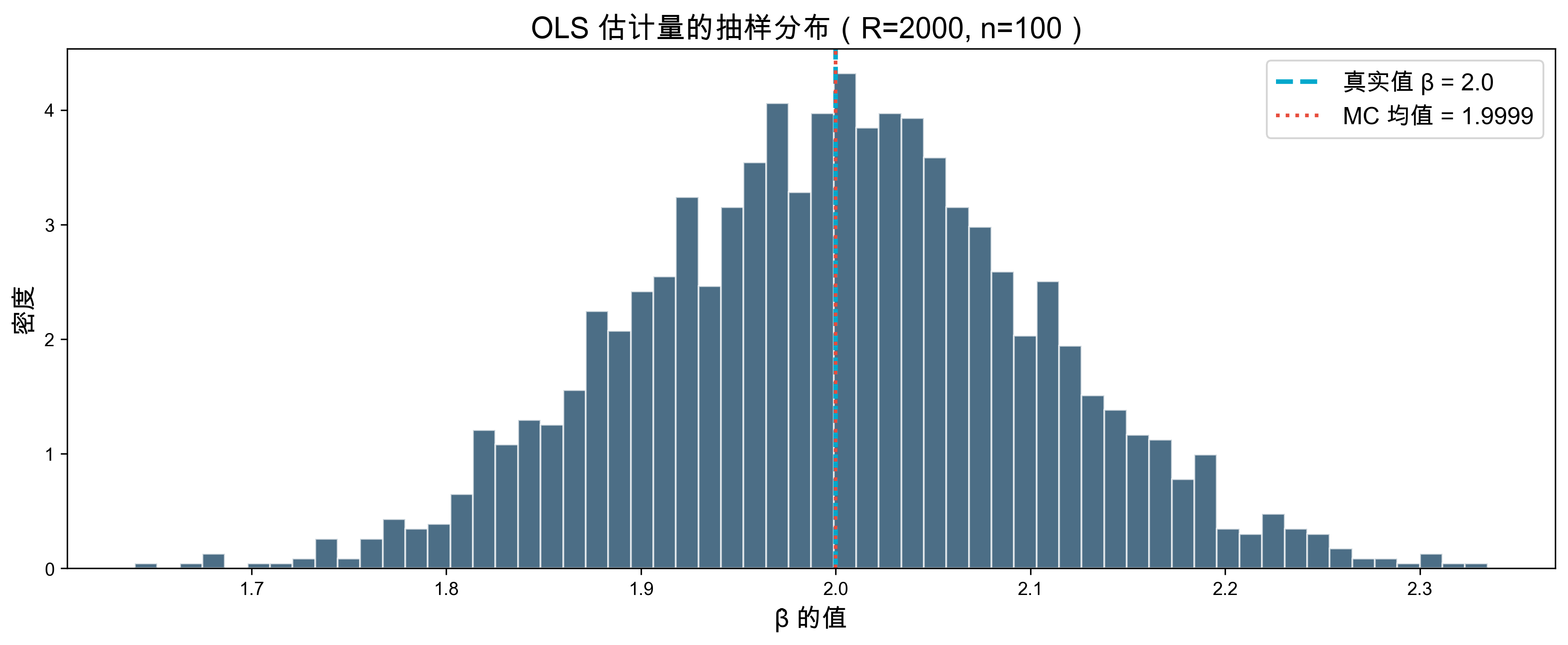
OLS 一致性的可视化
np.random.seed(42)
beta_true = 2.0
R = 2000
fig, axes = plt.subplots(1, 3, figsize=(12, 5), sharey=True)
for idx, n in enumerate([30, 100, 1000]):
betas = []
for _ in range(R):
x = np.random.normal(0, 1, n)
eps = np.random.normal(0, 1, n)
y = beta_true * x + eps
betas.append(np.sum(x * y) / np.sum(x ** 2))
axes[idx].hist(betas, bins=50, color='#003153', alpha=0.7, edgecolor='white', density=True)
axes[idx].axvline(beta_true, color='#00A8CC', linestyle='--', linewidth=2)
axes[idx].set_title(f'n = {n},SD = {np.std(betas):.3f}', fontsize=14)
axes[idx].set_xlabel('β̂', fontsize=13)
axes[idx].set_xlim(1.4, 2.6)
axes[0].set_ylabel('密度', fontsize=13)
fig.suptitle('一致性:样本量越大,估计量分布越集中', fontsize=15)
plt.tight_layout()
plt.show()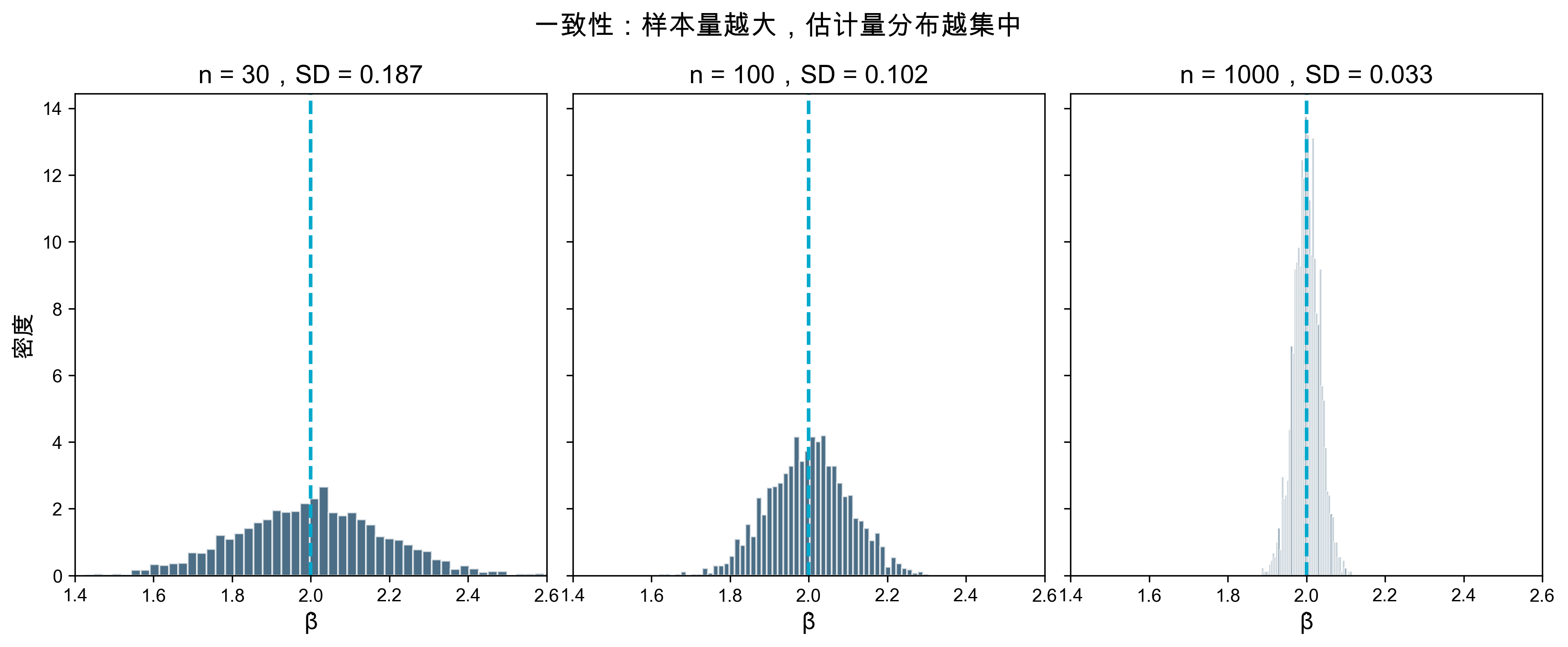
Monte Carlo 模拟的一般框架
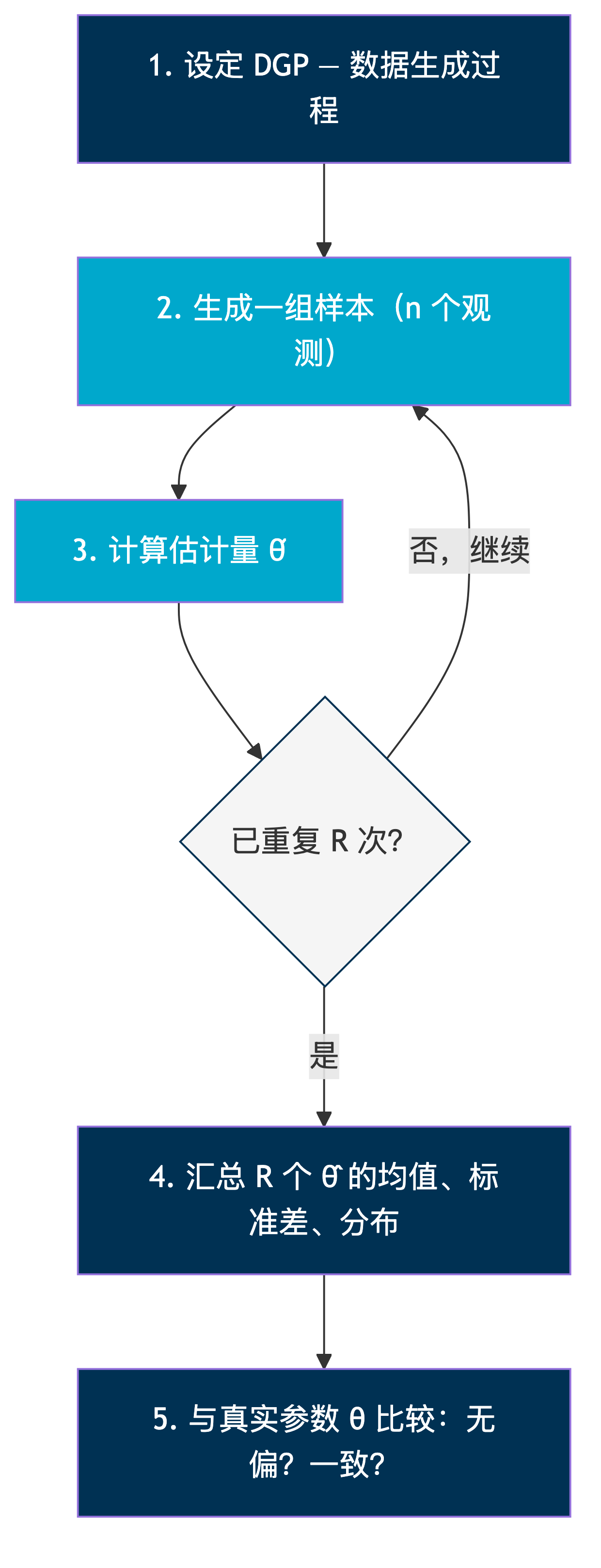
MC 设计三要素
- 固定种子:
np.random.seed(42)或set seed 12345——确保可重复 - 足够的重复次数:R \geq 1000(通常 2000–10000)
- 结果可视化:直方图比数字更直观
工作流的三个阶段

三个阶段,循环迭代
- 构建(Build):搭建项目骨架——做一次,持续受益
- 执行(Execute):从原始数据到最终结果——全程可追溯
- 迭代(Refine):审稿反馈、规格修改——不是重新开始,而是增量更新