经济与商务实证研究方法
第 4 周:DiD 方法的前沿拓展——匹配、合成、交错与实战
中国人民大学商学院
2026-05-23
上节课回顾
核心要点
- 面板数据 + 固定效应:消灭时不变异质性
- 经典 2×2 DiD:TWFE 在“两组两期”下与 DiD 等价
- 平行趋势不可直接检验;预趋势只是必要条件
- 聚类标准误:BDM(2004) 的 45% 过度拒绝警钟
本节课目标
- 把 DiD 从“2×2”扩展到更现实的设定:匹配、半参数、合成
- 看清交错处理下 TWFE 为何失灵——Goodman-Bacon 分解
- 学会 Callaway-Sant’Anna、Sun-Abraham、de Chaisemartin、Borusyak 四大现代估计量
- 掌握一份可直接用于论文的DiD 实战清单
本讲路线图
六个层层递进的环节
- 倾向得分匹配 DiD(PSM-DID)——把“可观测特征”拉平
- 半参数 DiD(Abadie 2005)——权重形式的 ATT
- 合成 DiD(Arkhangelsky et al. 2021)——SCM 与 DiD 的融合
- 交错处理下的 TWFE 陷阱——Goodman-Bacon 分解
- 现代估计量——CS、SA、dCdH、BJS 四兄弟
- 当历史重要——Imai-Kim-Wang 面板匹配
提示
配套实验室
所有 Stata 代码在 2026Spring/Labs/L4-Diff-in-Diffs-More.ipynb 中可独立运行。
一、倾向得分匹配 DiD
从潜在结果到选择偏误
潜在结果与 ATT
- 每个个体 i 有两种潜在结果 (Y_i^1, Y_i^0),但只能观测到 Y_i = D_i Y_i^1 + (1 - D_i) Y_i^0
- 关心的参数是受处理组的平均效应(ATT)
ATT = E[Y_i^1 - Y_i^0 \mid D_i = 1,\, \boldsymbol{X}_i]
观测差异的分解
\underbrace{E[Y_i \mid D=1, \boldsymbol{X}] - E[Y_i \mid D=0, \boldsymbol{X}]}_{\text{观测差异}} = \underbrace{ATT \mid \boldsymbol{X}}_{\text{真实效应}} + \underbrace{E[Y_i^0 \mid D=1,\boldsymbol{X}] - E[Y_i^0 \mid D=0, \boldsymbol{X}]}_{\textcolor{red}{\text{选择偏误}}}
选择偏误是阻挡“简单比较”识别 ATT 的核心障碍。
条件独立假设(CIA)
CIA 假设
Y_i^0 \perp D_i \mid \boldsymbol{X}_i
在 \boldsymbol{X}_i 条件下,处理分配相当于随机;此时 Bias(\boldsymbol{X}_i) = 0,ATT 可被识别。
CIA 何时失效
- 未观测特征驱动处理选择(能力、偏好、私人信息)
- 即使 \boldsymbol{X}_i 很丰富,也无法排除选择于不可观测维度
- 匹配方法的前提是“混杂都可观测”——这在实证中是一个需要论证的假设
回归 vs 匹配:两种加权
Angrist-Pischke 的观察
“Regression can be motivated as a particular sort of weighted matching estimator.”
权重差异
- 匹配:权重集中在 \Pr(D=1 \mid \boldsymbol{X}) 较高的格子——靠近处理组
- 回归:权重集中在 \Pr(D=1 \mid \boldsymbol{X}) \cdot [1 - \Pr(D=1 \mid \boldsymbol{X})] 较大的格子——处理/对照“拉锯”最激烈处
提示
共同支撑(Common Support)要求
0 < \Pr(D_i = 1 \mid \boldsymbol{X}_i) < 1
若某些 \boldsymbol{X} 值下只有处理组(或只有对照组),匹配/回归的权重无法定义。
倾向得分匹配(PSM)
Rosenbaum-Rubin (1983) 的降维
当 \boldsymbol{X} 维度高,逐维匹配困难。PSM 把 \boldsymbol{X} 压缩为一维倾向得分:
P(\boldsymbol{Z}_i) = \Pr(D_i = 1 \mid \boldsymbol{Z}_i)
匹配改在 P(\boldsymbol{Z}_i) 上进行。
Heckman-Ichimura-Todd (1998) 的结构解释
- 把 \boldsymbol{X} 拆成 (\boldsymbol{T}, \boldsymbol{Z}):\boldsymbol{T} 进入潜在结果方程,\boldsymbol{Z} 进入选择方程
- 排除限制:\Pr(D = 1 \mid \boldsymbol{X}) = \Pr(D = 1 \mid \boldsymbol{Z})
- 足够假设:U_i^0 \perp D_i \mid P(\boldsymbol{Z}_i)
PSM-DID:把 PSM 嫁接到面板
PSM-DID 估计量
\hat{\delta}^{PSM\text{-}DID} = E[Y_{i1} - Y_{i0} \mid \boldsymbol{X}_i, D_{i1} = 1] - E[Y_{i1} - Y_{i0} \mid \boldsymbol{X}_i, D_{i1} = 0]
匹配处理组与对照组在 P(\boldsymbol{Z}_i) 上相近的单位,对差分后的结果取平均。
PSM-DID 优于简单 PSM 之处
- 允许选择依赖于潜在结果水平——用面板差分消去个体固定效应
- 允许一部分不可观测维度上的选择——只要它们时不变
PSM-DID 实施步骤
三步走
- 用
probit/logit估计 P(\boldsymbol{Z}_i) - 按队列-年份在 \hat{P} 上做最近邻匹配
- 生成差分结果 \Delta Y_{it} = Y_{it} - Y_{i0},按权重聚合到 ATT_{gt}
提示
推断:Abadie & Imbens (2006) 的解析标准误;Stata 命令 teffects psmatch 直接支持。
Stata 实战:PSM-DID(Lab §2)
* ===== DGP:500 个体 × 2 期面板(选入处理依赖 x)=====
clear all
set seed 10101
set obs 500
g id = _n
g lambda = rnormal(0, 0.5) // 个体固定效应
expand 2
bys id: g t = _n - 1 // 0/1 两期
g x = rnormal(0, 1)
g u1 = rnormal(0, 0.2)
g u0 = rnormal(0, 0.2)
g v = rnormal(0, 1) if t == 1 // 选择方程噪声
scalar delta = 0.1 // 时间趋势
scalar alpha1 = 0.1
scalar alpha2 = 0.2
g y0 = alpha1*x + alpha2*x^2 + lambda + delta*t + u0
g y1 = alpha1*x + alpha2*x^2 + lambda + delta*t + u1
g D = 0
bys id (t): replace D = 1 if t == 1 & x > v // x 大的单位进入处理
g tau_u = cond(D == 1, 0.15, 0) // 真实 ATT = 0.15
replace y1 = y1 + tau_u if D == 1
g y = D*y1 + (1 - D)*y0
save simdata_did1.dta, replaceStata 实战:估计倾向得分
Stata 实战:PSM-DID 估计
* ===== Step 2:生成差分结果,Step 3:匹配 =====
tsset id t
g dy = y - l.y // 差分结果
* 1 近邻 PSM-DID
teffects psmatch (dy) (D x, probit) if t==1, atet nn(1) vce(robust)
* 2 近邻 PSM-DID
teffects psmatch (dy) (D x, probit) if t==1, atet nn(2) vce(robust)
* 3 近邻 PSM-DID
teffects psmatch (dy) (D x, probit) if t==1, atet nn(3) vce(robust)选择近邻数的权衡:近邻越多 → 偏误越小,但方差越大。
近邻数对 ATT 的影响
matrix Res = J(10, 3, .)
forv i = 1/10 {
qui teffects psmatch (dy) (D x, probit) if t==1, atet nn(`i') vce(robust)
matrix Res[`i', 1] = (_b[r1vs0.D], _se[r1vs0.D], `i')
}
drop _all
set obs 10
svmat double Res, names(c)
twoway connected c1 c3 || connected c2 c3, ///
legend(order(1 "ATT" 2 "SE")) xtitle("# of Neighbors")提示
实操经验
- 2–5 个近邻是稳健的默认选择
- 若 ATT 对近邻数极度敏感 → 说明重叠有问题,或处理效应异质
二、半参数 DiD
Abadie (2005, ReStud):权重表示
条件平行趋势下的 ATT 权重表达
ATT = E\left[\frac{Y_{i1} - Y_{i0}}{\textcolor{blue}{P(D = 1)}} \cdot \textcolor{red}{\frac{D_{i1} - P(D = 1 \mid \boldsymbol{X})}{1 - P(D = 1 \mid \boldsymbol{X})}}\right]
直观:用倾向得分对差分结果加权重,使得“对照组”被重新标定为处理组的可比反事实。
为什么重要
- 不需要选择任何近邻,权重由数据驱动
- 天然适合做子群(subgroup)的 ATT:只要定义 \boldsymbol{X}^{sub}
- Stata 命令:
absdid
Stata 实战:半参数 DiD(Lab §3)
三、合成双重差分
从合成控制说起
SCM(Abadie-Diamond-Hainmueller, JASA 2010)
单一处理单位的反事实用对照池的加权组合构造:
\hat{Y}_{1t}^{SCM} = \sum_{j=2}^{J+1} \omega_j^* \cdot Y_{jt}, \quad \omega^* \geq 0,\ \sum_j \omega_j^* = 1
- 权重选法:让合成单位处理前的结果路径与处理单位尽可能接近
- 经典案例:加州 Proposition 99 → 用 Utah + Nevada + … 合成出一个“没有控烟的加州”
SCM 的短板
何时 SCM 不够用
- 处理组有多个单位:权重解释变复杂,推断依赖渐近理论不适用
- 平行趋势“几乎成立”:不需要扔掉时间维度的结构
- 对照池很大:纯粹匹配路径可能过拟合
Arkhangelsky et al. (AER 2021) 的融合
合成 DiD(Synthetic DiD, SDiD)= SCM 的单位权重 + DiD 的时期权重 + TWFE 的面板结构
SDiD 的目标函数
同时使用单位权重 \omega_i^{sc} 与时期权重 \lambda_t^{sc}
(\hat{\delta}^{sdid},\, \hat{\mu},\, \hat{\alpha}_i,\, \hat{\beta}_t) = \arg\min \sum_i \sum_t (Y_{it} - \mu - \alpha_i - \beta_t - \delta D_{it})^2 \cdot \textcolor{blue}{\hat{\omega}_i^{sc}} \cdot \textcolor{red}{\hat{\lambda}_t^{sc}}
直觉:
- 像 SCM:单位权重让处理前的路径对齐 → 弱化对平行趋势的依赖
- 像 DiD:仍然保留 TWFE 结构 → 允许大面板渐近推断
提示
实现:Stata sdid、R synthdid;支持 bootstrap 或 jackknife 推断。
Stata 实战:Synthetic DiD(Lab §4)
use simdata_did1.dta, clear
g x2 = x^2
* 合成 DiD(自带单位 + 时期权重,bootstrap 推断)
sdid y id t D, covariates(x x2, projected) ///
vce(bootstrap) seed(123)
* 提取单位权重 omega(只存在于 t==1 且 D==0 的对照单位上)
g omega = .
qui sum D if t==1 & D==0
qui forv i = 1/`r(N)' {
scalar uw = e(omega)[`i', 1]
scalar ctr_id = e(omega)[`i', 2]
replace omega = uw if id == ctr_id
}SDiD 的权重诊断
为什么要看权重
- 权重集中:少数几个对照单位承担了全部合成——类似 SCM,反事实的可解释性高
- 权重分散:更接近 TWFE,平行趋势要求更严
- 论文应报告权重分布图:透明度比单一 ATT 估计更重要
四、交错处理下的 TWFE 陷阱
交错处理是常态
分批推进的政策
现实中很少“一刀切”,绝大多数政策是分批实施:
- 中国自贸区:2013(上海)→ 2015(闽粤津)→ 2017 / 2018 / 2019 / 2020
- 美国无过错离婚法:37 个州在 1969-1985 年陆续通过
- 企业数字化:内生选择,时点完全异质
TWFE 的直觉“扩展”
Y_{it} = \alpha_i + \lambda_t + \delta D_{it} + \varepsilon_{it}
看起来与 2×2 一样;但在交错处理下,\hat{\delta} 的含义已经面目全非。
Goodman-Bacon (JoE 2021) 分解
Bacon 分解定理
交错处理下,TWFE 系数等于所有可能的 2×2 DiD 估计量的加权平均:
\hat{\delta}^{TWFE} = \sum_{j \neq U} \underbrace{s_{jU} \hat{\beta}_{jU}^{2\times 2}}_{\text{处理 vs 从未}} + \sum_{k < \ell} s_{k\ell} \left[\mu_{k\ell} \underbrace{\hat{\beta}_{k\ell}^{2\times 2, k}}_{\text{早 vs 晚}} + (1 - \mu_{k\ell}) \underbrace{\hat{\beta}_{k\ell}^{2\times 2, \ell}}_{\textcolor{red}{\text{晚 vs 早(已处理)}}}\right]
- 对 K 个处理时点组 → 共 K^2 个 2×2 DiD
- 权重之和为 1,但可能为负
三组三期的几何直觉
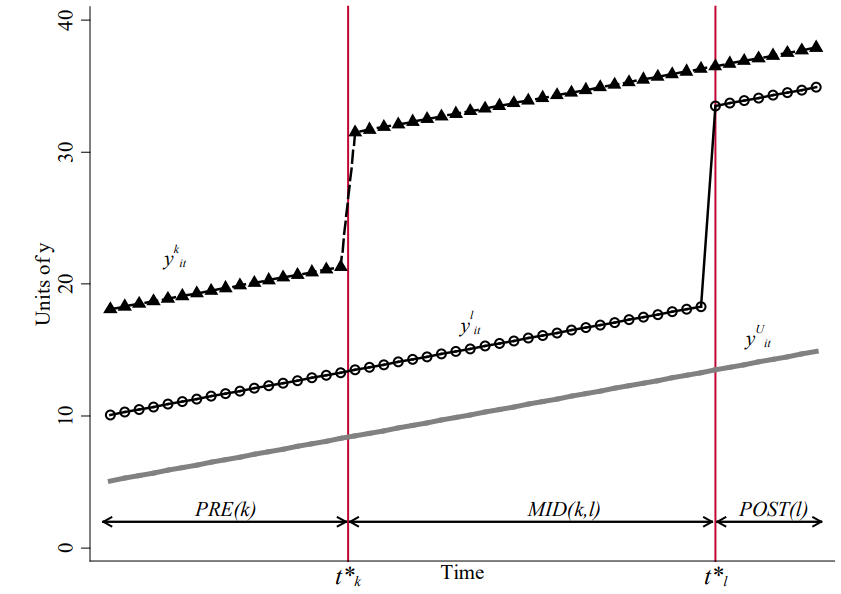
从未处理组 U、早处理组 k、晚处理组 \ell——TWFE 把它们两两组合做 2×2 DiD 再加权。
所有四种 2×2 DiD 组合
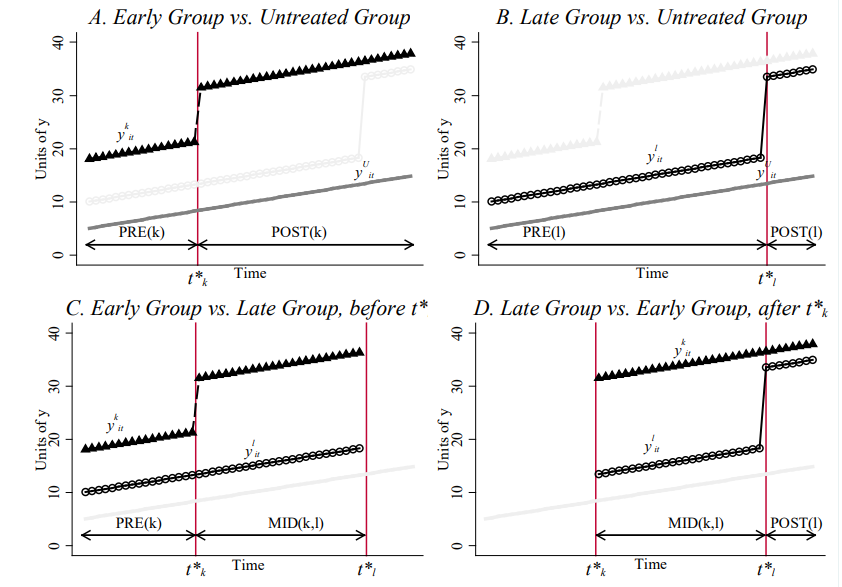
问题的关键
在“晚 vs 早”比较中,早处理组此时已处于处理后——其效应累积被错误地归为“控制组的趋势变化”。
Bacon 权重公式
权重的两个来源
s_{jU} = \frac{(n_j + n_U)^2 \hat{V}_{jU}^D}{\hat{V}^D},\ s_{k\ell}^k = \frac{[(n_k + n_\ell)(1 - \bar{D}_\ell)]^2 \hat{V}_{k\ell}^{D,k}}{\hat{V}^D},\ s_{k\ell}^\ell = \frac{[(n_k + n_\ell) \bar{D}_k]^2 \hat{V}_{k\ell}^{D,\ell}}{\hat{V}^D}
- 组规模平方:样本大的比较权重大
- 处理方差:两组规模相近 + 处理点接近样本中部 → 方差大 → 权重大
提示
直觉
TWFE 并不“公平地”加权所有处理效应。它放大规模相当、时点居中的比较;缩小边缘样本。
VWATT-VWCT-ΔATT 分解
Goodman-Bacon 的因果解释
\hat{\delta}^{TWFE} = \underbrace{VWATT}_{\text{方差加权 ATT}} - \underbrace{VWCT}_{\text{方差加权共同趋势}} + \underbrace{\Delta ATT}_{\textcolor{red}{\text{偏误项}}}
- VWCT = 0 若平行趋势成立
- \Delta ATT \neq 0 若处理效应随时间变化(效应累积、学习效应、政策加码)
负权重的出现
\Delta ATT = \sum_{k \neq U} \sum_{\ell > k} \sigma_{k\ell} \cdot [ATT_k^{post(\ell)} - ATT_k^{mid(k,\ell)}]
早处理组在晚处理组的“post”期继续累积效应时,它作为对照反而拉低了对“新处理”的估计——估计量可能给出错误符号。
经典案例:无过错离婚法
Stevenson & Wolfers (2006)
- 政策:无过错(unilateral)离婚法允许任一配偶结束婚姻,改变财产与议价权
- 数据:37 个美国州在 1969-1985 年分批通过
- 结果变量:女性自杀率
- Bacon (2021) 用
bacondecomp重新审视 → 发现 TWFE 的权重结构严重扭曲了估计
离婚法案例:事件研究与分解
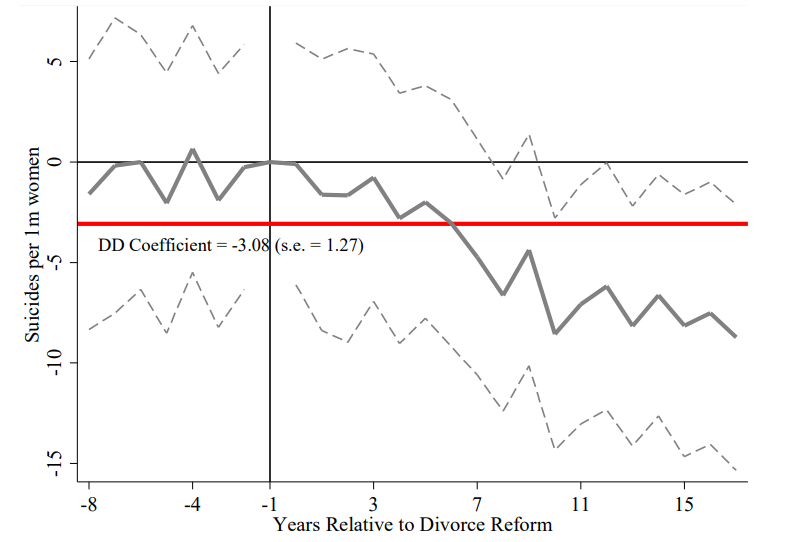
事件研究估计:post 期的平均效应 ≈ -4.92
TWFE 系数(未分解):-3.08
差距从何而来? 正是 Bacon 分解揭示的已处理对照组偏误。
Bacon 分解:权重汇总
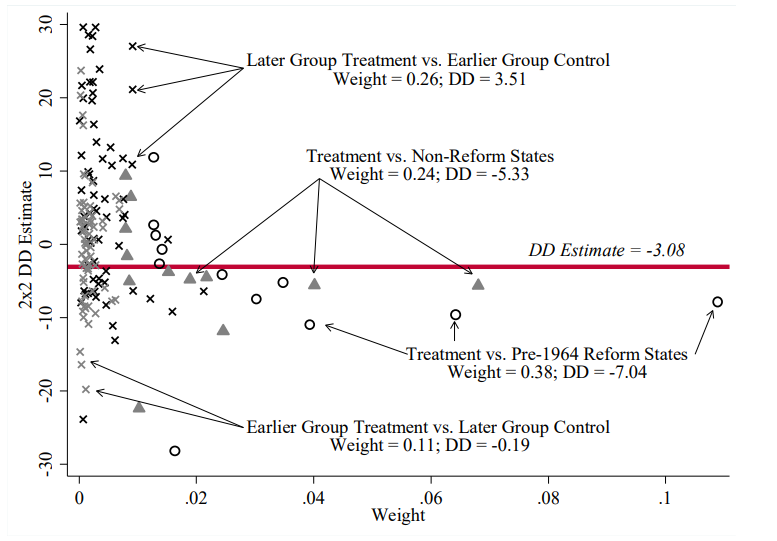
时点比较权重(问题区)
s_{k\ell}^k + s_{k\ell}^\ell = 0.26 + 0.11 = 0.37
处理-从未对照权重
s_{jU} = 0.38 + 0.24 = 0.62
清理后
- 排除“晚 vs 早”:ATT = -5.45
- 再排除“始终处理 vs 新处理”:ATT = -3.71
Stata 实战:Bacon 分解(Lab §5)
* ===== 交错处理 DGP(Borusyak et al. 2021 模板)=====
clear all
set seed 10
global T = 15
global I = 500
set obs `=$I * $T'
gen i = int((_n - 1)/$T) + 1
gen t = mod((_n - 1), $T) + 1
tsset i t
gen Ei = ceil(runiform() * 7) + $T - 6 if t == 1 // 首次处理年份 10..16
bys i (t): replace Ei = Ei[1]
gen K = t - Ei // 相对处理期
gen D = K >= 0 & Ei != .
gen tau = cond(D == 1, (t - 12.5), 0) // 动态效应
gen Y = i + 3*t + tau*D + rnormal()五、现代 DiD 估计量
共同原则:避免“已处理组做对照”
四个现代方法的修复路径
- 按组群-时期分别估计 ATT(g, t)
- 对照组限定在“从未处理”或“尚未处理” 的单位
- 按研究问题灵活聚合——总体 ATT / 事件时间 ATT / 组群 ATT
下面依次介绍四种主流方法:Wooldridge Mundlak、Sun-Abraham、Callaway-Sant’Anna、de Chaisemartin-D’Haultfoeuille、Borusyak-Jaravel-Spiess。
Wooldridge (2021) Mundlak 估计量
核心思想
“There is nothing inherently wrong with TWFE; the problem is that it imposes strong restrictions on effect heterogeneity.”
解决办法:把组群-时期虚拟交互项全部放入回归:
E(Y_{it} \mid \boldsymbol{G}) = \eta + \sum_{g=2}^T \lambda_g G_{ig} + \sum_{s=2}^T \theta_s \mathbf{1}(t = s) + \sum_{g=2}^T \sum_{s = g}^T \tau_{g,s} (G_{ig} \cdot \mathbf{1}(t = s))
识别假设
- 无预期:E[Y_t(g) - Y_t(\infty) \mid \boldsymbol{G}] = 0,\ t < g
- 平行趋势:E[Y_t(\infty) - Y_1(\infty) \mid \boldsymbol{G}] = E[Y_t(\infty) - Y_1(\infty)]
Sun & Abraham (JoE 2021)
交互加权估计量(Interaction-Weighted, IW)
Y_{it} = \sum_{g} \sum_{e \neq 0} \delta_{g,e} \cdot G_{ig} \cdot \mathbf{1}(t - g + 1 = e) + \lambda_i + \lambda_t + \varepsilon_{it}
- \hat{\delta}_{g, e} 一致估计 ATT(g, g + e - 1)
- 报告的事件研究系数:\hat{\theta}(e) = \sum_g \hat{w}_g \hat{\delta}_{g, e+1}
Callaway & Sant’Anna (JoE 2021)
组群-时期 ATT
ATT(g, t) = E[Y_t(g) - Y_t(\infty) \mid G_g = 1]
对照组两种选择
- “从未处理”(never-treated):C_i = 1
- “尚未处理”(not-yet-treated):D_t = 0 且 G_g = 0
对应的估计量:
\widehat{ATT}^{ny}(g, t) = \frac{\sum_i G_{ig}(Y_{it} - Y_{i,g-1})}{\sum_i G_{ig}} - \frac{\sum_i C_i(1 - G_{ig})(Y_{it} - Y_{i,g-1})}{\sum_i C_i(1 - G_{ig})}
de Chaisemartin & D’Haultfoeuille (AER 2020)
瞬时处理效应
\hat{\delta}^{dCdH} = \sum_{g=2}^T \hat{P}(G_g = 1 \mid \text{Treated})\cdot \widehat{ATT}(g, g)
只估计刚被处理那一瞬间的效应,按组群规模加权。
Borusyak, Jaravel & Spiess (ReStud 2024)
插补估计量
- 用未处理观测估计 \hat{\alpha}_i, \hat{\lambda}_t
- 对处理观测插补反事实:\hat{Y}_{it}(0) = \hat{\alpha}_i + \hat{\lambda}_t
- 单位-时期效应:\hat{\tau}_{it} = Y_{it} - \hat{Y}_{it}(0)
- 按需聚合(g、t、事件时间)
BJS 的卖点:在齐次方差下效率最优(BLUE);推断基于“随机化”——小样本可靠,自带预趋势的正式检验。
四种方法对比
| 维度 | CS | SA | dCdH | BJS |
|---|---|---|---|---|
| 框架 | 非参数 | 回归(IW) | 匹配式 | 插补 |
| 关注对象 | ATT(g, t) | \delta_{g, e} | 即期 ATT | 所有 (i, t) |
| 对照组 | 从未 / 尚未 | 最后处理 | 从未 + 尚未 | 所有未处理观测 |
| 协变量 | 需显式加权 | 直接入回归 | 需显式加权 | 直接入回归 |
| 小样本 | Bootstrap | 渐近 | 渐近 | 正式随机化 |
提示
实务建议
至少报告两种结果,并说明一致性。若方法间差距悬殊——往往是处理效应异质性被某一种方法的聚合方式放大了。
五种估计量在同一 DGP 上的对比
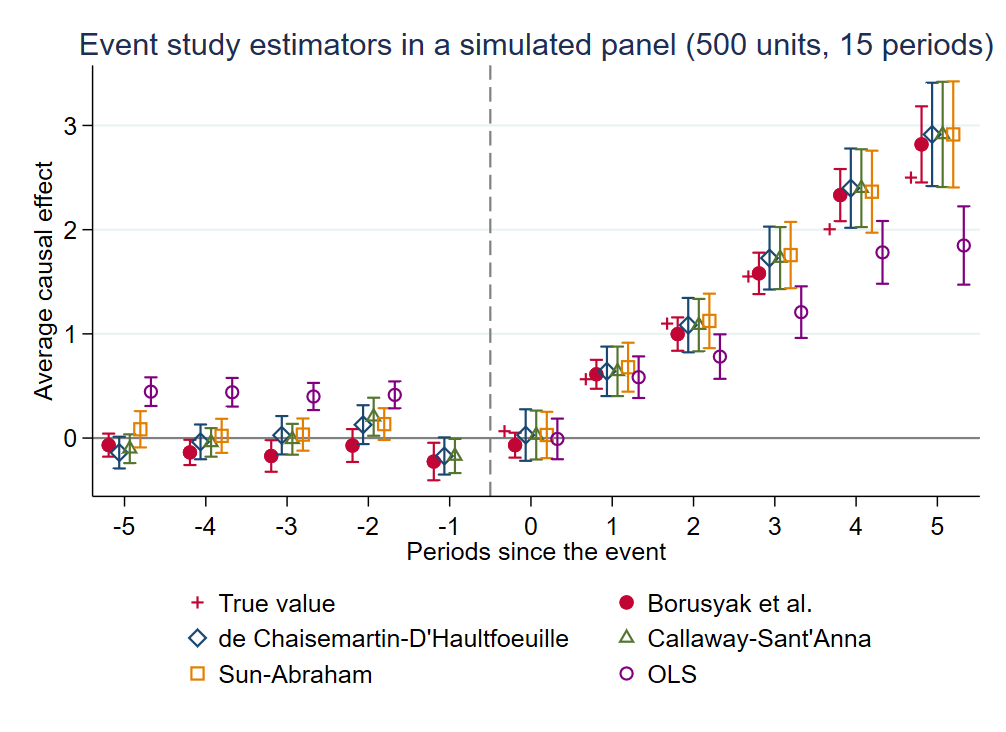
提示
500 单位 × 15 期,处理时点在 10–16 年间随机分配,真实动态效应 \tau = t - 12.5。OLS 事件研究在 post 期系统性偏低;四种现代估计量与真值基本重合。
Stata 实战:五估计量一图出(Lab §6)
* OLS(传统事件研究)
reghdfe Y F*event L*event, a(i t) cluster(i)
estimates store ols
* Sun-Abraham
eventstudyinteract Y L*event F*event, vce(cluster i) ///
absorb(i t) cohort(Ei) control_cohort(lastcohort)
matrix sa_b = e(b_iw)
matrix sa_v = e(V_iw)
* Callaway-Sant'Anna
csdid Y, ivar(i) time(t) gvar(gvar) notyet
estat event, estore(cs)
* de Chaisemartin & D'Haultfoeuille
did_multiplegt Y i t D, robust_dynamic dynamic(5) placebo(5) breps(100) cluster(i)
* Borusyak-Jaravel-Spiess
did_imputation Y i t Ei, allhorizons pretrend(5)
* 一键出图
event_plot btrue# bjs dcdh_b#dcdh_v cs sa_b#sa_v ols, ///
stub_lag(tau# tau# Effect_# T+# L#event L#event) ///
stub_lead(pre# pre# Placebo_# T-# F#event F#event) together六、历史重要:Imai-Kim-Wang (AJPS 2021)
动态经济变量的挑战
许多经济变量天然具有自相关
Y_{it} = \rho Y_{i, t-1} + X_{it}^\prime \alpha + \lambda_t + \mu_i + \varepsilon_{it}
- R&D、投资、资本存量、生产率、工资……都具有持续性
- 当政策 D_{it} 启动时,效应会“回响”到未来所有期
三种尺度的处理效应
- 即期效应:\delta
- 中期效应(F 期后):\delta \cdot (1 - \rho^F)/(1 - \rho)
- 长期效应:\delta / (1 - \rho)
Ashenfelter Dip
Ashenfelter (1978)
职业培训参与者在培训前收入就出现下降。这个“坑”是触发培训决定的冲击(失业、家庭变故)留下的痕迹。
直接比较培训前后会把这个 dip 误读为培训带来的显著正效应。
修正后的平行趋势
E[Y_{it}(0) - Y_{i,t-1}(0) \mid D_{it}, \{Y_{i,t-\ell}\}_{\ell=1}^L, \boldsymbol{X}_{it}] = E[Y_{it}(0) - Y_{i,t-1}(0) \mid \{Y_{i,t-\ell}\}_{\ell=1}^L, \boldsymbol{X}_{it}]
只有在控制了 L 期滞后 Y 之后,平行趋势才能站得住脚。
政策“不稳定”时的处理定义
\begin{array}{c|cccc|l} & t=1 & t=2 & t=3 & t=4 & \text{类型} \\ \hline i=1 & 0 & 1 & 1 & 1 & \text{稳定处理} \\ i=2 & 0 & 1 & 0 & 1 & \text{不稳定 I} \\ i=3 & 0 & 1 & 1 & 0 & \text{不稳定 II} \\ i=4 & 0 & 0 & 1 & 0 & \text{不稳定 III} \\ i=5 & 0 & 0 & 0 & 0 & \text{从未处理} \end{array}
三种处理方式
- 吸收态(absorbing):一旦处理就永远算处理
- 进入 / 退出分开估计:ATT(进入效应)vs. ART(退出效应)
- 按历史路径条件化:Imai-Kim-Wang 的核心思路
Imai-Kim-Wang 的 ATT(F, L) 与 ART(F, L)
L-period 历史条件下的效应
ATT(F, L) = E[Y^{01}_{it+F}(L) - Y^{00}_{it+F}(L) \mid D_{it} = 1, D_{i,t-1} = 0] ART(F, L) = E[Y^{10}_{it+F}(L) - Y^{11}_{it+F}(L) \mid D_{it} = 0, D_{i,t-1} = 1]
- F:政策变化后观察 F 期
- L:假设潜在结果仅依赖过去 L 期的处理历史
- 允许 \{D_{i, t-\ell}\}_{\ell = 2}^L 的任意历史
提示
F 与 L 的选择权衡
| 参数 | 大值的好处 | 大值的代价 |
|---|---|---|
| L | 更可信的历史条件 | 匹配样本缩小 |
| F | 长期效应 | 单位可能切换状态 |
面板匹配:ATT 估计量
匹配集合
\mathcal{M}_{it}^{ATT} = \{(m, t) \mid m \neq i,\ D_{mt} = 0,\ (D_{m, t-\ell})_{\ell=1}^L = (D_{i, t-\ell})_{\ell=1}^L\}
同样的历史路径、相同的当期处理变动的单位进入匹配集合。
估计量
\widehat{ATT(F, L)} = \frac{1}{\sum G_{it}} \sum_{i, t} G_{it} \left[Y^{01}_{it+F} - Y^0_{it-1} - \sum_{m \in \mathcal{M}_{it}} w_{it}^m (Y_{m, t+F} - Y_{m, t-1})\right]
- G_{it} = (D_{it} - D_{i, t-1}) \cdot \mathbb{1}\{|\mathcal{M}_{it}| \geq 1\}
- 权重 w 可用 Mahalanobis 距离 或 PSM(Rosenbaum-Rubin)
面板匹配:直观
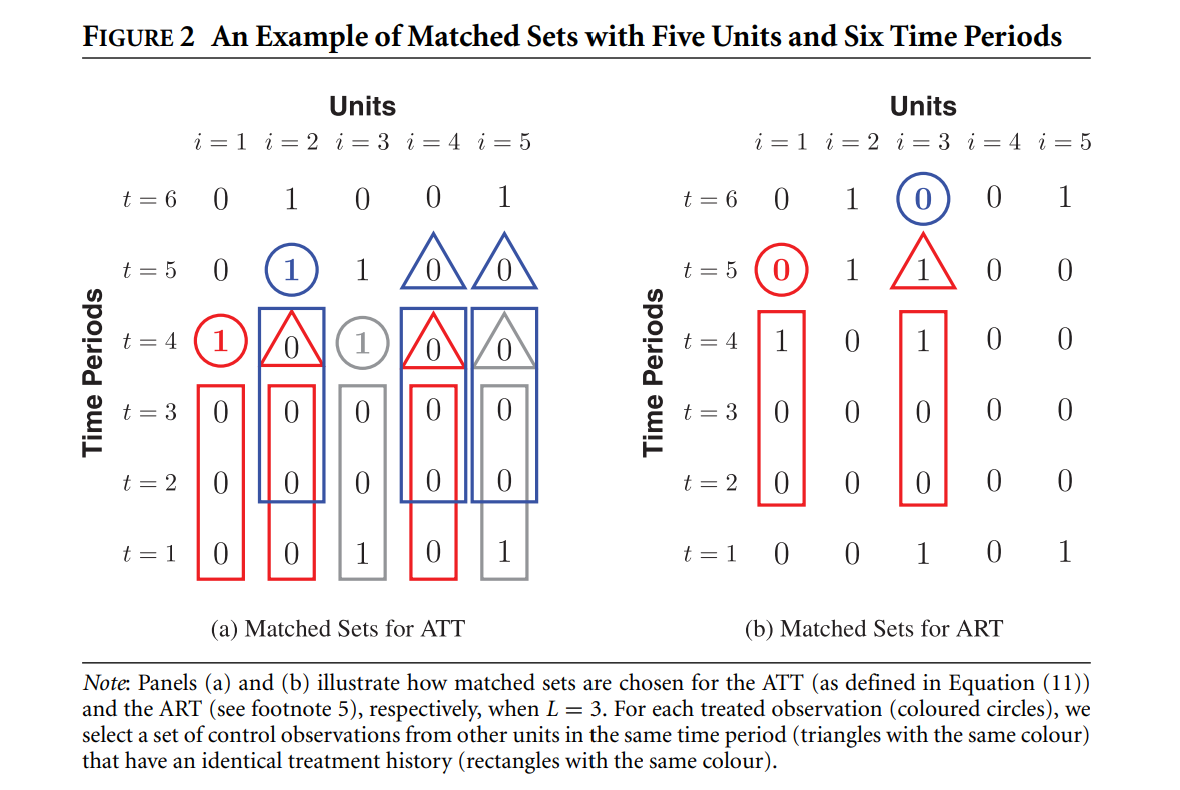
横轴是时间:每个处理单位寻找过去 L 期处理路径相同、当期刚切换的对照单位,然后比较 F 期后的结果。
生产率视角的动态 DiD(补充)
Chen (2023) 动态处理下的生产率估计
- 把结构模型(生产函数 + 生产率过程)与潜在结果框架嫁接
- 刻画处理如何改变生产率转移过程 (\bar{h}, h^+, h^-)
- 在条件平行趋势 \bar{h}_0 = h_0^+ 下识别 ATT_0
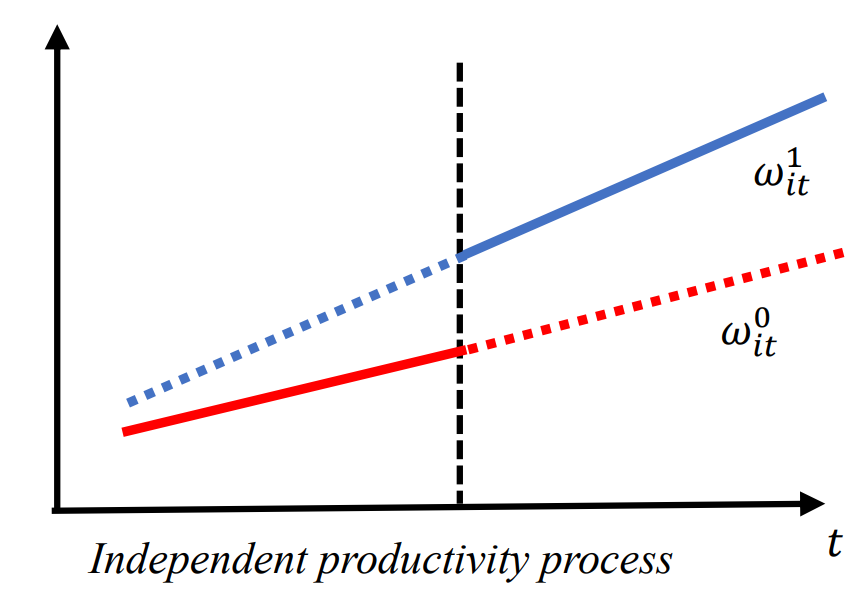
示例:绿色 vs. 污染技术的独立生产率过程

时点:m_{it} 是静态选择,(k_{it}, l_{it}, D_{it}) 是动态选择
七、实务指南
平行趋势不放心时怎么办
层层递进的应对
- 加入丰富的协变量:条件平行趋势
- 强制重叠条件:每个处理单位都存在 \boldsymbol{X} 接近的对照
- 检查无预期:处理前是否已有行为调整
- 更换框架:IV、RD、SCM、CiC(quantile DiD)
不该做的事
- 简单“加个时间趋势” → 往往吸收真实效应
- 数据驱动地“切样本” → 违反预注册
- 报告“通过了平行趋势检验” → 错误措辞,只能说“未拒绝”
DID 研究的标准清单

Roth, Sant’Anna, Bilinski & Poe (JoE 2023):一份写在论文审稿评论里的“必做清单”。
配套软件工具
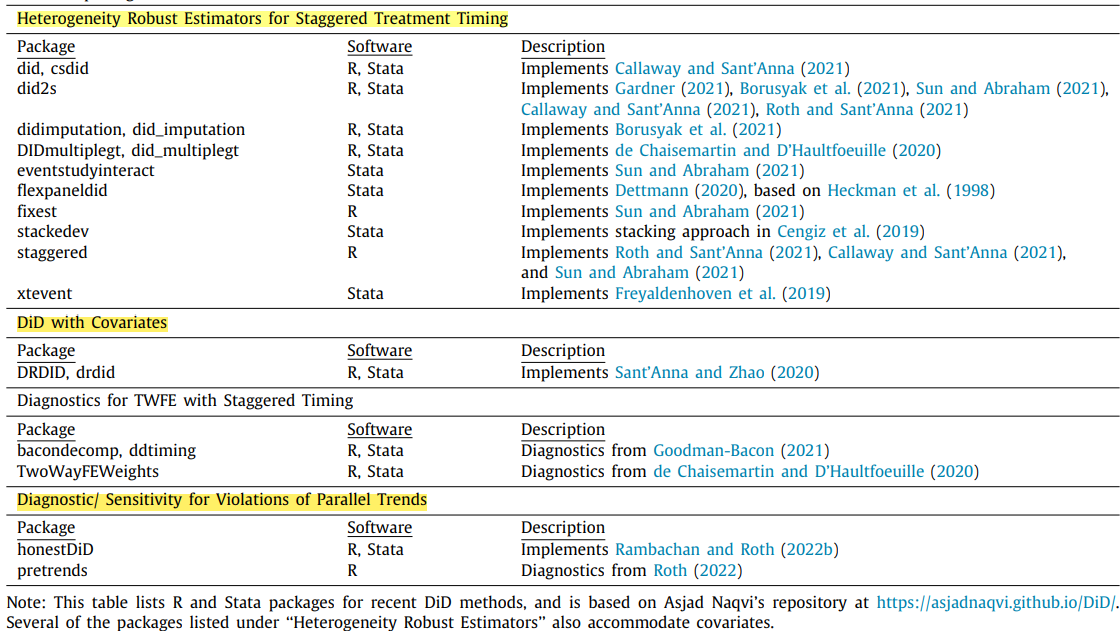
Stata:csdid、eventstudyinteract、did_multiplegt、did_imputation、sdid、bacondecomp、honestdid R:did、fixest(sunab()、i())、synthdid、DIDmultiplegt、didimputation、HonestDiD
本讲要点
本讲要点(一)
- 匹配类 DiD 把“可观测”拉平
- PSM-DID:降维到 P(\boldsymbol{Z}) 上匹配
- 半参数 DiD(Abadie 2005):权重驱动,天然适合子群
- 合成 DiD 把 SCM 与 DiD 融合
- 单位权重弱化平行趋势依赖
- 时期权重提升效率,保留大面板推断
sdid/synthdid正在成为默认方法
- 交错处理下 TWFE 会失灵
- Bacon 分解:TWFE = 所有 2×2 DiD 的加权平均
- 早处理组作为晚处理组的对照 → 负权重 + 错误符号
本讲要点(二)
- 四个现代估计量各有所长
- CS:非参数 + 明确组群-时期 ATT
- SA:仍在回归框架,协变量易加
- dCdH:关注即期效应,有完整安慰剂工具
- BJS:插补 + 效率最优,推断基于随机化
- 当历史重要——Imai-Kim-Wang 面板匹配
- 按 L 期历史路径条件化
- ATT(F, L) 与 ART(F, L) 分开估计
- 应对不稳定政策、动态反事实
- DiD 实战清单
- 一份论文至少报告:预趋势图、安慰剂、两种以上现代估计量、权重诊断、Honest DiD 敏感性
下节课预告
第 5 周:因果机器学习
- 预测 vs. 因果:ML 能做什么、不能做什么
- LASSO 与高维控制变量选择——Post-LASSO 的陷阱
- Double / Debiased ML(DML)——Neyman 正交化 + 交叉拟合
- 因果森林与异质处理效应(HTE)
- 实战:
doubleml/econml/grf
核心思想
当控制变量数量与样本量可比(甚至更大)时,传统线性回归会失效。ML 提供预测能力——但预测 ≠ 因果。DML 通过正交化让两者结合。
参考文献
- Abadie, A. (2005). Semiparametric difference-in-differences estimators. Review of Economic Studies, 72(1), 1–19.
- Abadie, A., & Imbens, G. W. (2006). Large sample properties of matching estimators for average treatment effects. Econometrica, 74(1), 235–267.
- Arkhangelsky, D., Athey, S., Hirshberg, D. A., Imbens, G. W., & Wager, S. (2021). Synthetic difference-in-differences. American Economic Review, 111(12), 4088–4118.
- Borusyak, K., Jaravel, X., & Spiess, J. (2024). Revisiting event study designs: Robust and efficient estimation. Review of Economic Studies, 91(6), 3253–3285.
- Callaway, B., & Sant’Anna, P. H. C. (2021). Difference-in-differences with multiple time periods. Journal of Econometrics, 225(2), 200–230.
- de Chaisemartin, C., & D’Haultfoeuille, X. (2020). Two-way fixed effects estimators with heterogeneous treatment effects. American Economic Review, 110(9), 2964–2996.
- Goodman-Bacon, A. (2021). Difference-in-differences with variation in treatment timing. Journal of Econometrics, 225(2), 254–277.
- Heckman, J. J., Ichimura, H., & Todd, P. E. (1998). Matching as an econometric evaluation estimator. Review of Economic Studies, 65(2), 261–294.
- Imai, K., Kim, I. S., & Wang, E. H. (2021). Matching methods for causal inference with time-series cross-sectional data. American Journal of Political Science, 67(3), 587–605.
- Roth, J., Sant’Anna, P. H. C., Bilinski, A., & Poe, J. (2023). What’s trending in difference-in-differences? A synthesis of the recent econometrics literature. Journal of Econometrics, 235(2), 2218–2244.
- Sun, L., & Abraham, S. (2021). Estimating dynamic treatment effects in event studies with heterogeneous treatment effects. Journal of Econometrics, 225(2), 175–199.
- Wooldridge, J. M. (2021). Two-way fixed effects, the two-way Mundlak regression, and difference-in-differences estimators. Working Paper.