经济与商务实证研究方法
第 3 周:面板数据与经典双重差分法
陈志远
中国人民大学商学院
2026-05-16
上节课回顾
核心要点
- 计算基础:VS Code + Python/Stata/R 的统一工作平台
- AI 编程工具:Copilot、Claude Code、Codex 各司其职
- Monte Carlo 模拟:用模拟验证估计量性质——今天的主武器
- 可重复研究工作流:构建 → 执行 → 迭代 + 审计日志
本节课目标
- 掌握面板数据结构与固定效应(FE)估计的基本机理
- 理解经典 2×2 双重差分法(DiD)的识别逻辑
- 通过 Monte Carlo 模拟“亲手”验证聚类标准误的重要性
- 搭建一份可直接用于自己论文的 DiD 稳健性清单
本讲路线图
四个串联的环节
- 面板数据与固定效应——为什么只有面板能“消灭”个体异质性?
- 经典 2×2 DiD——在两组两期下,FE 与 DiD 是同一枚硬币
- 聚类标准误的 Monte Carlo——忽视序列相关会让 t 检验“假阳性”暴增
- 实务清单——一份合格的 DiD 研究至少应报告哪些稳健性检验?
提示
下周预告:W4 会把 2×2 扩展到多期、多批次(staggered)——届时 TWFE 会悄悄失效,我们要用更加现代估计量。
一、面板数据与固定效应
什么是面板数据?
面板数据(Panel Data)
同一批单位(个体 / 企业 / 城市 / 国家)在多个时期被重复观测:
\{Y_{it}, X_{it}\}_{i=1,\dots,N;\ t=1,\dots,T_i}
- N 较大(横截面维度),T_i 较小(时间维度)
- 平衡面板:每个 i 都有 T 期观测
- 非平衡面板:T_i 因 i 而异(常见于企业进入退出)
为什么值得单独开一讲?
- 横截面回归只能“横着看”——无法分离个体效应与政策冲击
- 面板让我们“纵着也看”——同一单位的变化量可以识别处理效应
面板回归与遗漏变量
考虑基础回归: Y_{it} = X_{it}^\prime \beta + \theta_i + \varepsilon_{it}
混合 OLS 的致命伤
若 \theta_i 与 X_{it} 相关(“能力”“地理”“文化”等),混合 OLS 估计有偏:
\hat{\beta}_{POLS} = \beta + \frac{\operatorname{Cov}(X_{it},\, \theta_i)}{\operatorname{Var}(X_{it})}
固定效应的核心思想
如果我们能“去除” \theta_i,那么与它相关的遗漏变量偏误就消失了。这正是固定效应估计的核心思想。
固定效应:组内去均值(Within Transformation)
Within 变换
对每个个体 i 计算时间(组内)均值 \bar{Y}_i, \bar{X}_i,然后用偏差代替原值:
(Y_{it} - \bar{Y}_i) = (X_{it} - \bar{X}_i)^\prime \beta + (\varepsilon_{it} - \bar{\varepsilon}_i)
- 常数项 \theta_i 在去均值中被消除
- 等价于在回归中加入个体虚拟变量(LSDV)
一阶差分(First Difference, FD)
Y_{it} - Y_{i,t-1} = (X_{it} - X_{i,t-1})^\prime \beta + (\varepsilon_{it} - \varepsilon_{i,t-1})
两期数据下,FE 估计量与 FD 估计量完全等价(作业:自行验证)。
FE vs. POLS:不总是 FE 更好
分解样本变异
\operatorname{Var}(X_{it}) = \underbrace{\sum_i \sum_t (X_{it} - \bar{X}_i)^2}_{\text{组内变异}} + \underbrace{\sum_i T_i (\bar{X}_i - \bar{X})^2}_{\text{组间变异}}
FE 只使用组内变异——当 X_{it} 变化很小时,组内变异稀少,估计量方差大。
测量误差放大
若 X_{it} 包含测量误差 u_{it},差分后的信噪比恶化:
\hat{\beta}^{FE}_{bias} = \frac{\operatorname{Var}(X^*_{it} - \bar{X}^*_i)}{\operatorname{Var}(X^*_{it} - \bar{X}^*_i) + \operatorname{Var}(u_{it} - \bar{u}_i)}\beta
这就是衰减偏误(Attenuation Bias)
- Almond, Chay & Lee (QJE 2005) 以孪生子数据为例揭示了该问题。
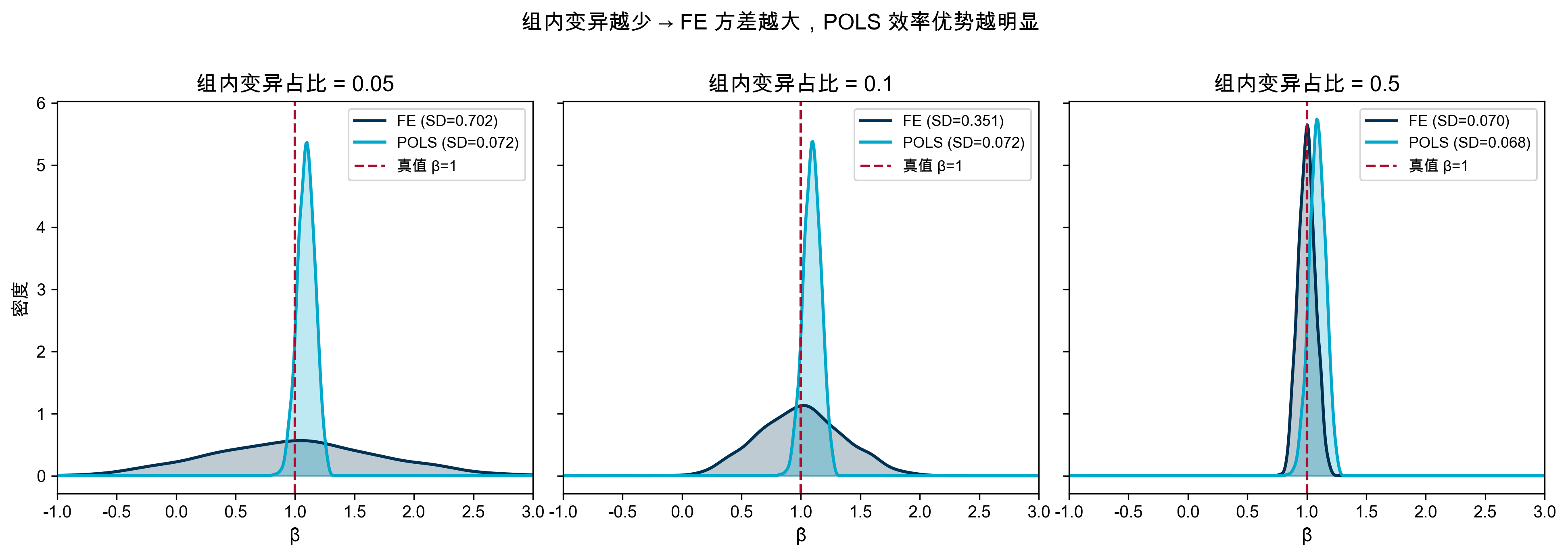
Monte Carlo:组内变异稀少时 FE vs. POLS
提示
当 \theta_i 与 X_{it} 无关(RE 假设成立)且组内变异稀少时:
- FE 无偏但方差极大——因为只依赖稀少的组内变异
- POLS 可能有偏,但利用了组间+组内的全部变异,方差小得多
随机效应 vs. 固定效应
| 维度 | 随机效应(RE) | 固定效应(FE) |
|---|---|---|
| 对 \theta_i 的假设 | E(\theta_i \mid X_i)=0(与 X 无关) | 不作任何假设 |
| 估计效率 | 在假设成立时更有效 | 总是一致(无偏) |
| 何时首选 | 样本 N 大且 \theta_i 与 X 独立 | 担心遗漏变量时 |
| 检验工具 | Hausman 检验 | — |
提示
实操建议
在政策评估研究中,默认使用 FE——几乎不可能说服审稿人“我的随机效应假设成立”。只有在数据天然满足 RE 假设(随机抽样、无系统性选择)时,才考虑 RE。
Hausman 检验:FE 还是 RE?
核心思想
比较两个估计量:RE(H_0 下一致且有效)与 FE(始终一致但效率较低)。
若二者系统性偏离 → H_0 不成立 → 选 FE。
H_0: E(\theta_i \mid X_{it}) = 0 \quad \text{(个体效应与解释变量无关)}
检验统计量:
H = (\hat{\beta}_{FE} - \hat{\beta}_{RE})' \left[\widehat{Var}(\hat{\beta}_{FE}) - \widehat{Var}(\hat{\beta}_{RE})\right]^{-1} (\hat{\beta}_{FE} - \hat{\beta}_{RE}) \;\sim\; \chi^2(k)
实操建议
- 拒绝 H_0 → 选 FE;不拒绝 → 理论上可选 RE
- 但在政策评估中,几乎无人敢声称 \theta_i \perp X——Hausman 检验更多是审稿人要求的形式流程
- Stata 命令:
hausman fe_model re_model, sigmamore
序列相关:面板的“隐形炸弹”
最天真的 OLS 假设
“不同时期的误差独立”——在面板里几乎总是错的。
E(u_{it} u_{is}) = 0,\ \forall\, t \neq s \quad \text{(疯狂的假设!)}
序列相关的来源
- 未观测的个体效应(即便加了 FE,仍有残余)
- 冲击的持续性:经济周期、政策余波、行业趋势
- 缓慢变动的状态变量:资本存量、人力资本、社会规范
后果:标准误被严重低估,t 值被放大,假阳性率飙升——这正是本讲后半部分 Monte Carlo 模拟要验证的核心现象。
二、经典 2×2 双重差分法
政策评估的第一直觉
问题:不能直接“比较政策前后”
2012 年某省实施环保新政,企业排放下降了。这是政策效果,还是:
- 经济下行带来的生产萎缩?
- 技术进步的全局趋势?
- 其他省份同期的政策溢出?
DiD 的核心思想
找一个未受政策影响的对照组,用对照组的前后变化作为“如果没有政策”的反事实(counterfactual)基准:
\hat{\tau}_{DiD} = \underbrace{(\bar{Y}_{T,\text{post}} - \bar{Y}_{T,\text{pre}})}_{\text{处理组变化}} - \underbrace{(\bar{Y}_{C,\text{post}} - \bar{Y}_{C,\text{pre}})}_{\text{控制组变化}}
经典案例:Card & Krueger (1994)
新泽西最低工资实验
背景:1992 年新泽西(NJ)把最低工资从 $4.25 提到 $5.05;宾夕法尼亚(PA)保持不变。
设计:调查 NJ 与 PA 东部 410 家快餐店,政策前后各一次就业人数数据。
结果:DiD 估计显示 NJ 就业未下降(甚至略升)——挑战“最低工资必减少就业”的教科书结论。
提示
为什么这篇论文成了经典
- 选址精巧:NJ 与 PA 东部经济、人口结构几乎同质
- 时点干净:最低工资调整的时间由立法程序决定,外生于餐厅决策
- 数据透明:电话调查 + 实地回访——任何人都能复制
注记
最低工资文献
David Neumark and William Wascher, “Minimum Wages and Employment: A Review of Evidence from the New Minimum Wage Research,” NBER Working Paper 12663 (2006), https://doi.org/10.3386/w12663.
Hau, Harald, Yi Huang, and Gewei Wang. “Firm response to competitive shocks: Evidence from China’s minimum wage policy.” The Review of Economic Studies 87.6 (2020): 2639-2671.
潜在结果框架下的 DiD
潜在结果符号
- Y_{it}(1):个体 i 在时期 t 若被处理的结果
- Y_{it}(0):个体 i 在时期 t 若未被处理的结果
- 观测到的结果 Y_{it} = D_{it} Y_{it}(1) + (1 - D_{it}) Y_{it}(0)
平均处理效应(ATT)
\tau_{ATT} = E[Y_{it}(1) - Y_{it}(0) \mid D_i = 1,\, t = \text{post}]
DiD 在平行趋势假设下识别 ATT。
平行趋势假设
平行趋势(Parallel Trends)
若无处理,处理组与控制组的结果变化趋势相同:
\underbrace{E[Y_{it}(0)\mid D=1, \text{post}] - E[Y_{it}(0)\mid D=1, \text{pre}]}_{\text{处理组反事实变化}}
=\underbrace{E[Y_{it}(0)\mid D=0, \text{post}] - E[Y_{it}(0)\mid D=0, \text{pre}]}_{\text{控制组实际变化}}
不可直接检验
我们只能检验处理之前的趋势是否平行(预趋势检验)——但这不能保证处理之后的反事实趋势仍然平行。预趋势检验是必要不充分的条件。
TWFE 回归:把 DiD 写成回归
双向固定效应回归(Two-Way Fixed Effects, TWFE)
Y_{it} = \alpha_i + \lambda_t + \tau D_{it} + \varepsilon_{it}
- \alpha_i:个体固定效应,吸收组间基线差异
- \lambda_t:时间固定效应,吸收共同时间趋势
- D_{it}:是否已被处理的指示变量
- \tau:平均处理效应
经典 2×2 设定下(一个处理组 + 一个控制组,处理前后各一期)
\hat{\tau}_{TWFE} = (\bar{Y}_{T,1} - \bar{Y}_{T,0}) - (\bar{Y}_{C,1} - \bar{Y}_{C,0}) = \hat{\tau}_{DiD}
TWFE 回归系数恰好等于 DiD 估计量——这是后面现代 DiD 讨论的出发点。
Python 模拟:经典 2×2 DiD
np.random.seed(42)
n_units, n_periods = 200, 10
treat_period = 5
unit_fe = np.random.normal(0, 2, n_units)
time_fe = np.linspace(0, 3, n_periods)
treated = np.arange(n_units) < 100 # 前 100 个单位为处理组
rows = []
for i in range(n_units):
for t in range(n_periods):
d = 1 if (treated[i] and t >= treat_period) else 0
y = unit_fe[i] + time_fe[t] + 2.5 * d + np.random.normal(0, 1)
rows.append({'unit': i, 'time': t, 'treated': treated[i], 'D': d, 'Y': y})
df = pd.DataFrame(rows)
means = df.groupby(['treated', 'time'])['Y'].mean().unstack(level=0)
did = (means[True].iloc[-1] - means[True].iloc[treat_period - 1]) \
- (means[False].iloc[-1] - means[False].iloc[treat_period - 1])
print(f"DiD 估计量 = {did:.3f}(真实效应 = 2.5)")DiD 估计量 = 2.272(真实效应 = 2.5)DiD 的可视化
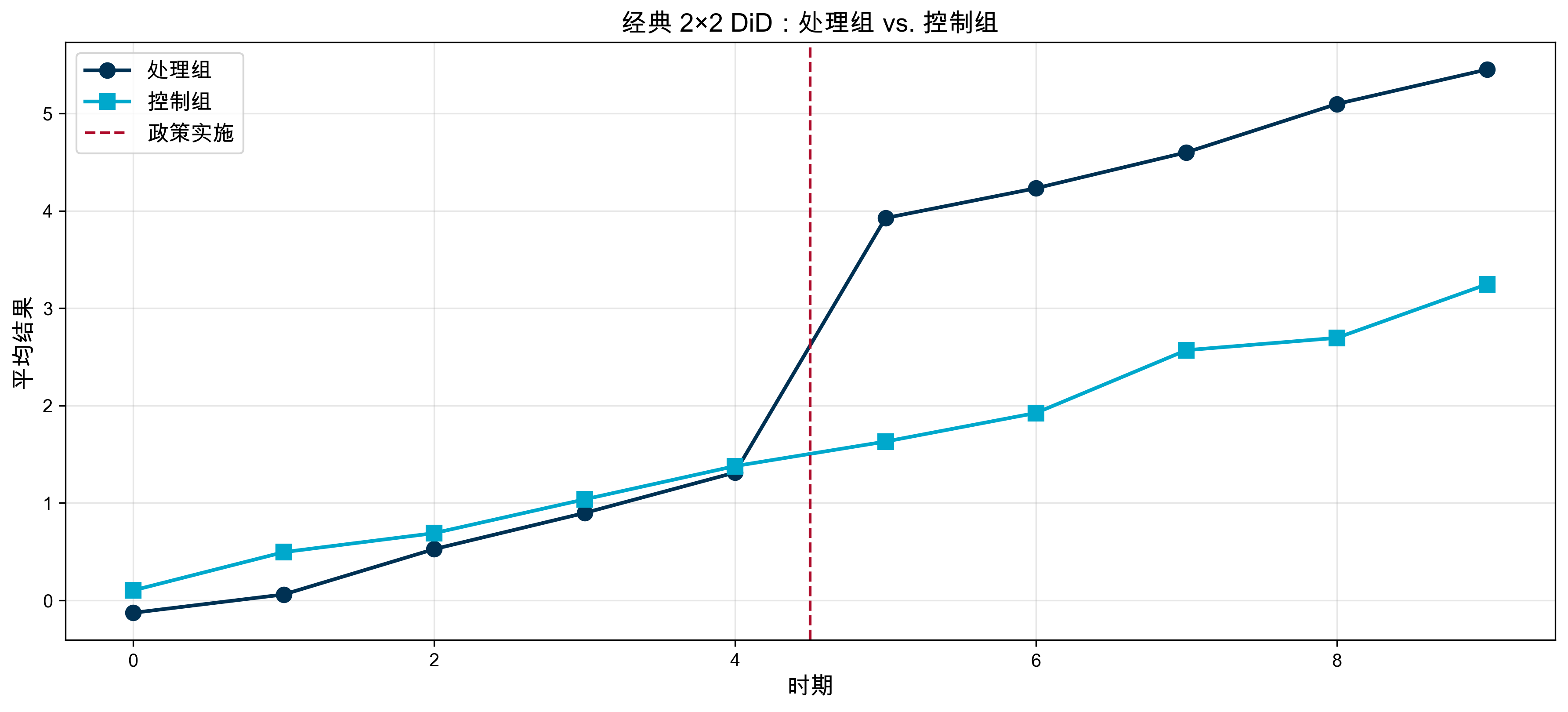
图形直觉:处理组在处理点后与控制组路径“分叉”,分叉幅度即 DiD 估计量。
事件研究:把 DiD 做“动态”
事件研究回归(Event Study)
Y_{it} = \alpha_i + \lambda_t + \sum_{k=-K,\ k \neq -1}^{L} \beta_k \cdot \mathbf{1}(t - g_i = k) + \varepsilon_{it}
- 相对处理时间 k:k = -1 作为基准期(系数被约束为 0)
- \beta_k 同时报告预趋势(k<0)与动态效应(k\geq 0)
两大用途
- 预趋势检验:k<0 的系数是否“齐平”于零?
- 动态效应:效应是立即出现还是缓慢累积?
重复横截面 vs. 真面板
重复横截面也能跑 DiD
只要我们观察到组层面的 (\text{group}, \text{time}) 结构,DiD 回归就成立:
Y_i = \alpha_0 + \tau \cdot (g_i \times t_i) + \delta t_i + \gamma g_i + \varepsilon_i
- 不需要同一个个体在前后都被观测
- 适用于跨期重复调查(CPS、CFPS 等)
提示
面板数据的“奢侈品”优势
- 可以做个体固定效应——吸收时不变异质性
- 可以做事件研究——观察单位的轨迹
- 可以做单位自身对比——降低随机误差
安慰剂检验与组别时间趋势
安慰剂检验(Placebo Test)
- 预期效应(Anticipatory Effect):假装政策提前 n 期实施,重新估计 \hat{\tau}
- 假政策效应:假装政策在个体-时间组合上随机实施,重新估计 \hat{\tau}
如果“假政策”也显示显著效应 → 平行趋势很可疑
组别特定时间趋势
加入 \text{group} \times \text{time trend} 控制组间差异化趋势:
Y_{it} = \alpha_i + \lambda_t + \tau D_{it} + \gamma_i \cdot t + \varepsilon_{it}
- 可作为稳健性: 但若处理组本身“趋势上行”,会吸收掉真实效应
- 不能滥用:趋势项往往与处理效应共线
示例:隐藏趋势如何让 placebo 报警
模拟设定: 300 个个体、8 期面板;一半在第 6 期“受处理”. 真实政策效应设为 0,但处理组有一条未观测的缓慢上升趋势. 考虑两种 placebo:
- 提前 2 期 placebo:假装政策在第 4 期就发生;
- 随机分配 placebo:保持样本规模不变,随机抽取“处理组”
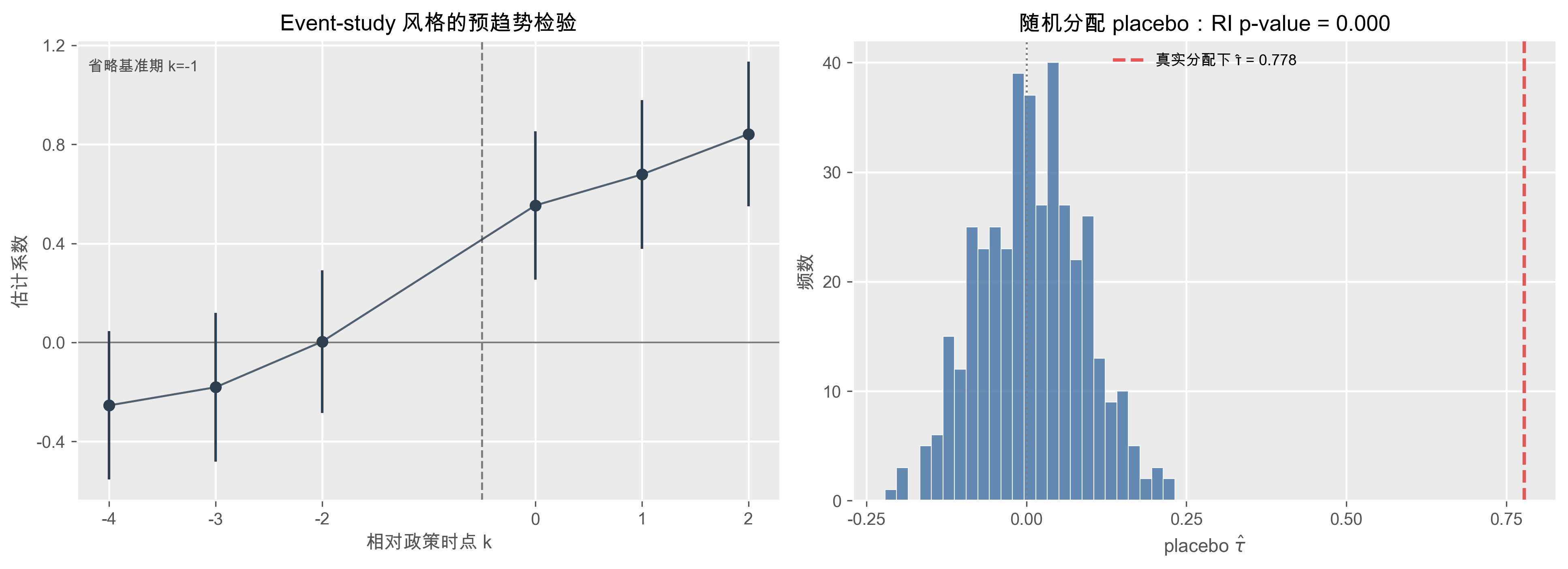
提示
- 左图k<0 的 lead 系数不显著异于零,满足平行趋势?
- 右图看“真实分配是否特殊”:若真实估计值落在随机 placebo 分布尾部,说明即使真实政策效应为 0,处理组的特殊趋势也足以制造“假阳性”
- 若再加上 group × time trend 后主效应明显缩小,就要认真怀疑原始 DiD 识别
期刊论文通常怎样展示 placebo 结果?
最常见的三种展示
- 提前 placebo / leads 图:把 k<0 的 lead 系数画成事件研究图,读者先看政策前系数是否接近 0
- 随机分配 placebo 分布图:画随机政策分配下的直方图/核密度图,把真实估计值用竖线标出来
- 稳健性表格:把“基准 DiD、提前 placebo、随机 placebo p 值、+ group trend”放在同一张表里
| 规格 | 估计值 | RI p-value | 解读 | |
|---|---|---|---|---|
| 0 | 基准 DiD | 0.778 | — | 真实政策效应明明为 0,但仍估到正效应 |
| 1 | 提前 2 期 placebo | 0.785 | — | 政策前已经出现“假效应” |
| 2 | 随机分配 placebo | — | 0.000 | 真实分配下的估计值落在随机分布尾部 |
| 3 | + 组别线性趋势 | 0.037 | — | 加上 trend 后,主效应明显回落 |
提示
- 事先平行趋势图 用来让审稿人一眼看到“政策前有没有动静”
- Monte Carlo 分布图 用来说明“不是随便换一组处理对象都能跑出同样结果”
- 表 用来汇总不同 placebo 与 trend-control 规格,展示结论是否稳健
平行趋势的科学表述
提示
一、双差分、事件研究等双向固定效应模型中的平行趋势假设
1. 概念说明
(1)反事实基础与不可直接检验性
平行趋势假设本质上是一种反事实假设,即假定处理组若未受到干预,其趋势应与对照组一致。然而,由于无法同时观测到处理组的“处理”和“未处理”两种状态,因此平行趋势假设无法被直接检验。我们只能通过事前趋势(pre-treatment trends)的相似性提供间接支持,但无法直接验证这种反事实假设。
(2)事前趋势与平行趋势的关系
事前趋势的相似性既不是平行趋势的必要条件(例如,即便处理前趋势不同,处理后的趋势仍可能满足平行趋势),也不是充分条件(即便处理前趋势一致,处理后的不可观测因素仍可能导致趋势的差异)。因此,事前趋势的检验只能提供提示性证据(suggestive evidence),不能表述为“通过了检验”。
2. 修改建议
(1)小标题避免使用“平行趋势检验”,建议使用“事前趋势检验”或“平行趋势假设评估”等。
(2)正文中避免使用“通过了平行趋势检验”等表述,建议使用“未拒绝事前趋势平行的假设”、“数据分析结果与平行趋势假设一致”或类似措辞。
Honest DiD:事先趋势检验的局限性
核心问题
即使事前系数“不显著”,也不能证明平行趋势成立——这可能只是检验力不足(low power)的结果。
Rambachan & Roth (ReStat, 2023) 提出两种放松平行趋势的思路:
思路 A:相对幅度(Relative Magnitudes)
- 假设处理后的平行趋势违反程度 \leq \bar{M} 倍于处理前最大违反
- \bar{M}=1:处理后的偏离不比处理前更严重
- \bar{M}=0:回到严格平行趋势
\Delta^{RM}(\bar{M}): \quad |\delta_{post}| \;\leq\; \bar{M}\,\cdot\,\max_{t<0}|\delta_t|
思路 B:平滑性约束(Smoothness)
- 假设趋势差异的斜率变化(二阶差分)受限于 M
- M=0:趋势差异严格线性外推
- M>0:允许一定程度的非线性
\Delta^{SD}(M): \quad |(\delta_{t+1}-\delta_t) - (\delta_t-\delta_{t-1})| \leq M
提示
关键输出
- 稳健置信区间:在给定 \bar{M} 或 M 下,保证 \geq 95\% 覆盖率
- 敏感性分析:画出结论随 \bar{M} / M 变化的轨迹
- 击穿值(Breakdown Value):结论不再成立时的最大 \bar{M} 或 M——越大越稳健
HonestDiD 实践:R & Stata 代码示例
R(HonestDiD 包)
# 第1步:TWFE 事件研究回归
library(fixest)
mod <- feols(dins ~ i(Dyear, ref = 2013) |
stfips + year,
cluster = ~stfips, data = df)
# 第2步:提取系数与方差矩阵
betahat <- coef(mod) # 事件研究系数
sigma <- vcov(mod) # 方差-协方差矩阵
# 第3步:相对幅度敏感性分析
library(HonestDiD)
sens_rm <- createSensitivityResults_relativeMagnitudes(
betahat = betahat, sigma = sigma,
numPrePeriods = 5,
numPostPeriods = 2,
Mbarvec = seq(0.5, 2, by = 0.5))
# 第4步:绘制敏感性图
createSensitivityPlot_relativeMagnitudes(
sens_rm, rescaleFactor = 0.01,
OLS_CI = c(betahat[6] - 1.96*sqrt(sigma[6,6]),
betahat[6] + 1.96*sqrt(sigma[6,6])))Stata(honestdid 包)
- R:
remotes::install_github("asheshrambachan/HonestDiD") - Stata:
ssc install honestdid或net install honestdid, from("https://raw.githubusercontent.com/mcaceresb/stata-honestdid/main")
解读击穿值:如果相对幅度的击穿值 \bar{M} \approx 2,意味着只要处理后的平行趋势违反不超过处理前最大违反的 2 倍,DID 估计的符号就不会翻转——这是相当稳健的结果。
如何解读 HonestDiD 敏感性图?
典型的 HonestDiD 输出是一张敏感性图(sensitivity plot)
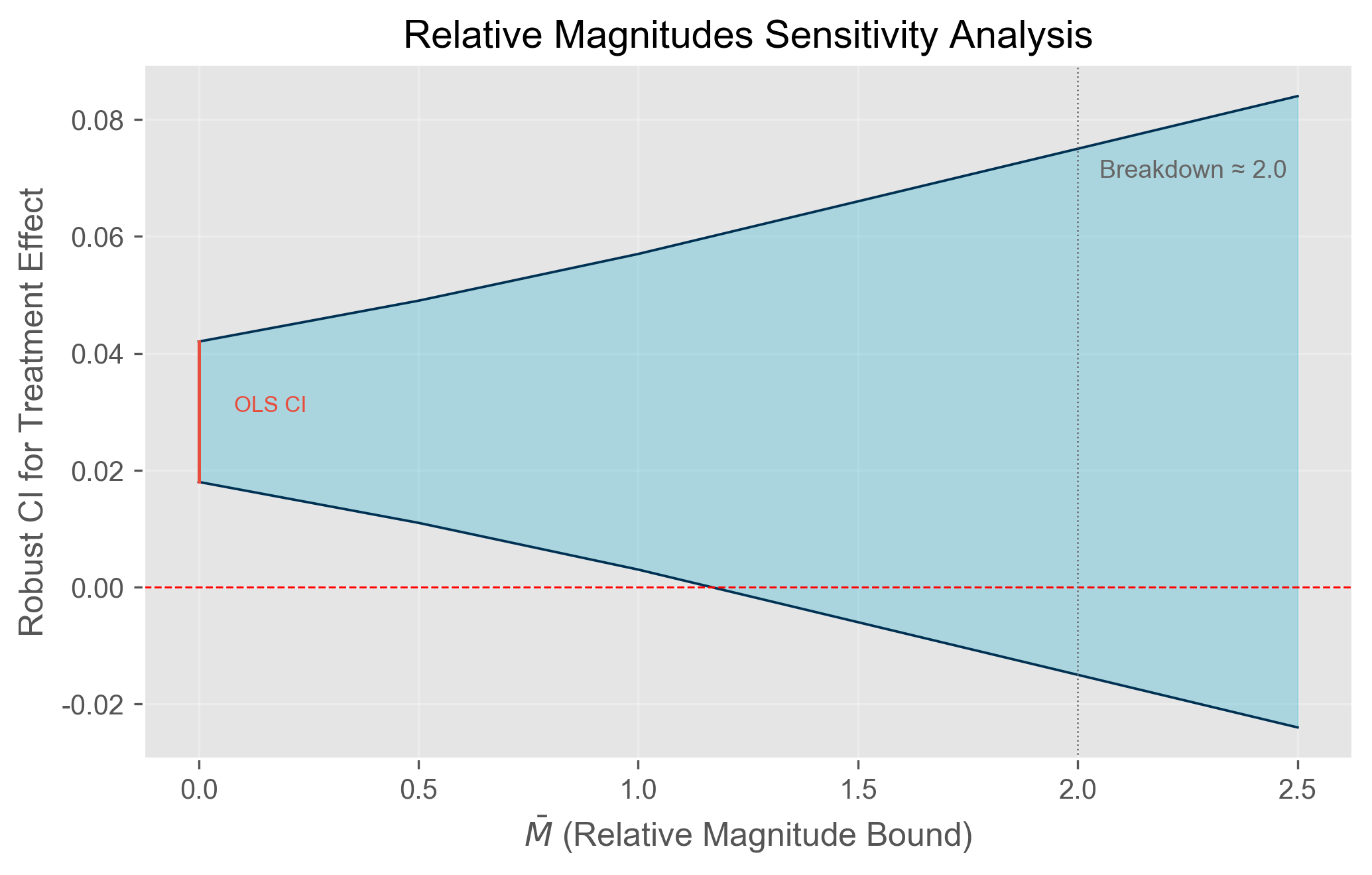
读图三步法:
① 看 \bar{M}=0(最左端)
- 等价于严格平行趋势
- 此时 CI 即传统 OLS 区间
② 看 CI 何时跨零线
- 红色虚线 = 零效应
- CI 下界碰到零线的 \bar{M} 即击穿值
- 本例 \bar{M}\approx 2.0
③ 判断稳健程度
| 击穿值 | 解读 |
|---|---|
| < 0.5 | 脆弱:结论依赖严格平行趋势 |
| 0.5–1 | 一般:允许中等违反 |
| 1–2 | 较强:处理后偏离≤处理前最大偏离的1–2倍 |
| > 2 | 很强:结论极难被推翻 |
提示
审稿人视角:在论文中报告 HonestDiD 敏感性图 + 击穿值,已逐渐成为 top field journals 的 DID 稳健性标准配置(参见 Roth et al., JoE 2023 综述)。
DiD 的统计推断问题
统计推断:获得正确的标准误
- 实际应用中,我们通常拥有个体层面数据(个人、企业……),而政策是在更高层级实施的(城市、省份)
- 似乎我们拥有了“比我们需要的更多”的数据
考虑个体层面模型:
Y_{i}=\alpha\tau_{t_{i}}(g_i)+Z_{i}'\delta+X'_{g_{i}t_{i}}\beta+\theta_{g_{i}}+\gamma_{t_{i}}+u_{i}
将数据按组-年聚合:
\bar{Y}_{gt}=\alpha\bar{\tau}_{gt}+Z'_{gt}\delta+X_{gt}'\beta+\theta_{g}+\gamma_{t}+\bar{u}_{gt}
两个回归都能给出一致的处理效应估计,但标准误不同——应该用哪个?
聚类标准误与序列相关
个体模型的误差项可以分解为:
u_{i}=\textcolor{red}{\eta_{g_{i}t_{i}}}+\epsilon_{i}
- 如果 \eta_{g_{i}t_{i}} 存在,u_i 的 i.i.d 假设被违反
- 标准方案:按“组×年”聚类,允许组内任意相关
Bertrand, Duflo & Mullainathan (QJE, 2004):若 \eta_{gt} 存在序列相关,仅按“组×年”聚类仍然有问题!
解决方案:
| 情景 | 推荐方法 |
|---|---|
| 组数较多 | 按 block bootstrap |
| 组数中等 | 方差-协方差矩阵的渐近近似 |
| 组数较少 | 将数据折叠为“前”、“后”两期,考虑有效样本量 |
实操指南:Cameron & Miller (2015, JHR)
Monte Carlo:聚类标准误如何选?
Monte Carlo 模拟的三大价值
- 建立直觉:亲眼看到估计量在重复抽样中的分布
- 检验推断:算出“名义 5%”和“实际拒绝率”的差距
- 比较方法:同一 DGP 下,不同方法孰优孰劣一目了然
Bertrand, Duflo & Mullainathan (QJE 2004) 的提醒
他们构造全美州级就业面板,人为赋一个“不存在”的政策给随机选中的州,发现:
- 不聚类的 TWFE 在 5% 显著性水平上拒绝原假设的概率高达 45%
- 聚类到州后,拒绝率回到 5% 附近
结论:忽视序列相关,会让 DiD 论文的 t 值严重失真。
MC 实验设计
数据生成过程(DGP)
- 500 个单位 × 10 期面板
- 误差项 \varepsilon_{it} 在单位内AR(1) 序列相关:\varepsilon_{it} = 0.8 \varepsilon_{i,t-1} + u_{it}
- 随机选 100 个单位在 t=5 起接受“伪政策”——真实效应为 0
- 跑 1000 次重复,每次记录 \hat{\tau} 和三种标准误下的 p 值
提示
为什么这样设计能“捕捉”问题?
真实效应 = 0,按名义 5% 水平只应有 5% 的实验拒绝 H_0。任何超过 5% 的拒绝率,都是推断失真。
Python 实现(节选)
def simulate_panel(n_units=500, n_periods=10, rho=0.8, treat_effect=0.0, seed=0):
rng = np.random.default_rng(seed)
unit_fe = rng.normal(0, 1, n_units)
time_fe = rng.normal(0, 1, n_periods)
# AR(1) 误差
eps = np.zeros((n_units, n_periods))
eps[:, 0] = rng.normal(0, 1, n_units)
for t in range(1, n_periods):
eps[:, t] = rho * eps[:, t-1] + rng.normal(0, 1, n_units)
treated = rng.choice(n_units, size=n_units // 5, replace=False)
is_treated = np.zeros(n_units, dtype=bool); is_treated[treated] = True
D = np.zeros((n_units, n_periods))
D[is_treated, 5:] = 1
Y = unit_fe[:, None] + time_fe[None, :] + treat_effect * D + eps
return Y, D, is_treated三种标准误的比较
from scipy import stats
def twfe_three_se(seed):
"""用 Within 变换计算 TWFE 估计 + 三种 SE(iid / HC1 / 按单位聚类)"""
Y, D, _ = simulate_panel(seed=seed)
n, T = Y.shape
# 双向去均值
Y_dm = Y - Y.mean(axis=1, keepdims=True) - Y.mean(axis=0) + Y.mean()
D_dm = D - D.mean(axis=1, keepdims=True) - D.mean(axis=0) + D.mean()
y = Y_dm.flatten(); x = D_dm.flatten()
# OLS on double-demeaned
b = (x * y).sum() / (x * x).sum()
r = y - b * x
df_adj = n * T - n - T # TWFE 自由度
# iid SE
sigma2_iid = (r * r).sum() / df_adj
se_iid = np.sqrt(sigma2_iid / (x * x).sum())
# HC1
se_hc = np.sqrt(((x * r) ** 2).sum() / (x * x).sum() ** 2 * (n * T) / df_adj)
# Cluster on unit
xr = (x * r).reshape(n, T).sum(axis=1)
se_cl = np.sqrt((xr ** 2).sum() / (x * x).sum() ** 2 * n / (n - 1))
# 两尾 t 检验 p 值
p_iid = 2 * (1 - stats.t.cdf(abs(b / se_iid), df=df_adj))
p_hc = 2 * (1 - stats.t.cdf(abs(b / se_hc), df=df_adj))
p_cl = 2 * (1 - stats.t.cdf(abs(b / se_cl), df=n - 1))
return p_iid, p_hc, p_cl
pvals = np.array([twfe_three_se(s) for s in range(300)])
reject = (pvals < 0.05).mean(axis=0)
print(f"拒绝率 — iid: {reject[0]:.1%} HC1: {reject[1]:.1%} cluster: {reject[2]:.1%}")拒绝率 — iid: 27.7% HC1: 27.3% cluster: 5.7%核心结论
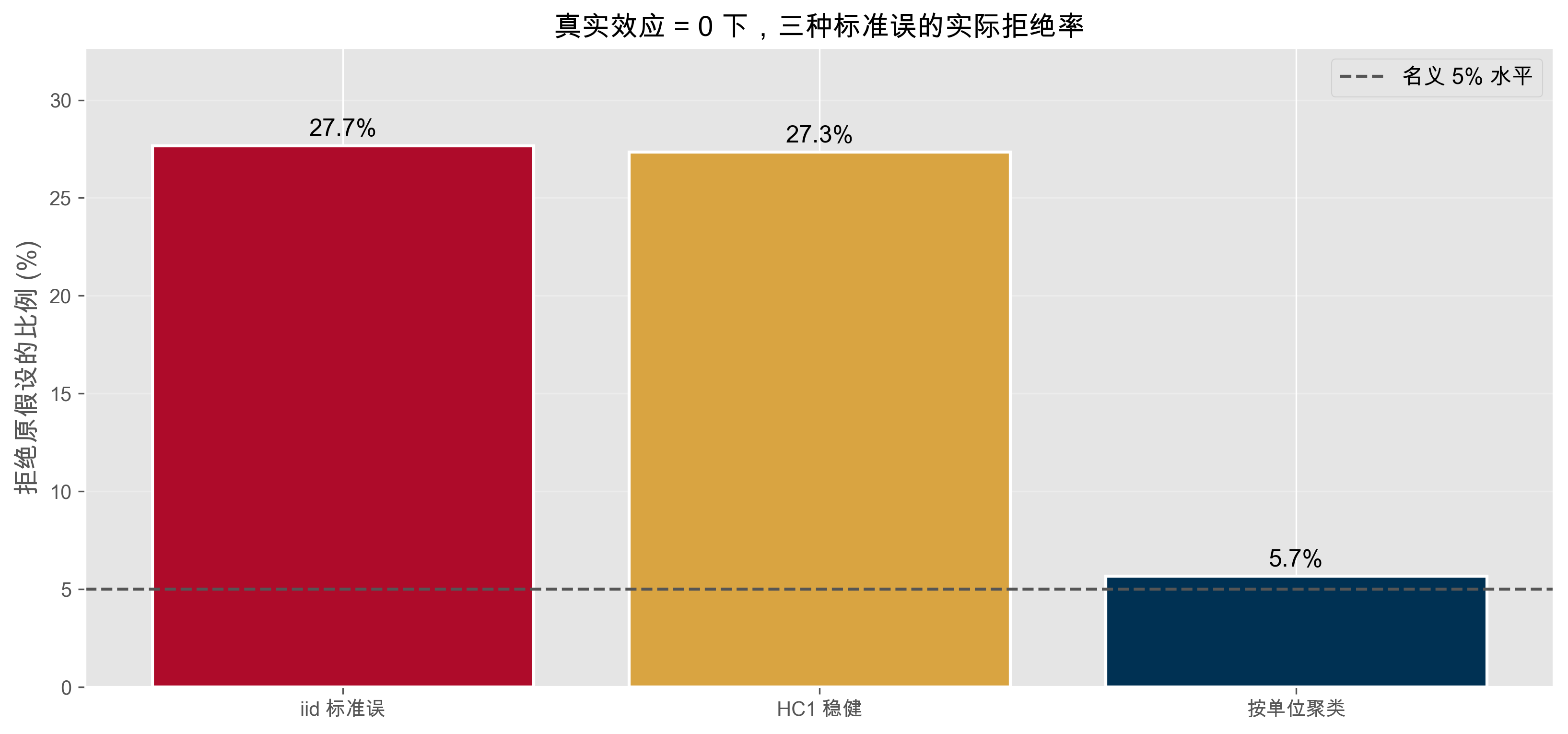
iid 与 HC1 都严重过度拒绝;按单位聚类后拒绝率才回到 5% 附近。
聚类实践规则
Cameron & Miller (JHR 2015) 的黄金三条
- 在政策分配的最细层级上聚类——政策在省级实施就聚到省,在企业级实施就聚到企业
- 聚类数 G \geq 50 时,聚类稳健标准误大致可靠(渐近理论适用)
- G < 50 时,使用 Wild Cluster Bootstrap(Cameron-Gelbach-Miller 2008)或 Randomization Inference
两维聚类(Two-Way Clustering)
Cameron, Gelbach & Miller (2011) 公式
同一观测可能同时属于两个“维度”的群组(如:企业属于城市和行业)。
\hat{V}(\hat{\beta}) = \hat{V}^G(\hat{\beta}) + \hat{V}^H(\hat{\beta}) - \hat{V}^{G \cap H}(\hat{\beta})
- 分别按 G、H、G \cap H 聚类三次,加减即可
- Stata:
vce(cluster province industry) - R:
cluster = ~ province + industry
提示
何时用两维
- 冲击沿时间传染(行业波动)且沿空间传染(地区外溢)时
- 需要检查对具体聚类维度选择的敏感性时
动手实验室:L3_Clustering_MonteCarlo
配套实验室
2026Spring/Labs/L3_Clustering_MonteCarlo.ipynb
- Stata
- 复现 BDM(2004) 的 45% 过度拒绝结论
- 对比:iid / 稳健 / 单聚类 / 两维聚类 / Wild Bootstrap
- 改变 AR(1) 系数 \rho \in \{0, 0.4, 0.8\} 观察退化速度
提示
建议用法
- 课后自己跑 1 次体会“亲眼看到 45%”的震撼
- 有意识地使用 MC “体检”你的推断方法
四、DiD 研究的稳健性清单
一份合格 DiD 论文的七项自检
写稿前先自问
- 识别假设清楚写出了吗?(平行趋势 + 无预期)
- 预趋势检验做了吗?事件研究图呈现了吗?
- 安慰剂政策(提前/延后 n 期)做了吗?
- 聚类层级与处理变量分配层级一致吗?
- 聚类数 G 是否足够大?不够时用了 Wild Bootstrap 吗?
- 组别异质性 / 时间异质性讨论了吗?
- 替代对照组 / 排除潜在污染样本的稳健性检验做了吗?
重要
七项未必全做,但被审稿人问到时要有答案
空着等审稿人追问,不如提前在论文附录里“主动回答”。
预趋势失败怎么办?
常见的错误应对
- “加个时间趋势项”——往往吸收掉真实效应
- “换一个控制组”——可能是“选样本迎合结论”
- “截掉早期样本”——可能违反数据预注册原则
正确的应对
- 坦诚报告:在正文中展示预趋势图,不遮掩
- 寻找时间异质来源:是哪一类处理单位的预趋势异常?
- 更换识别策略:退到 IV、合成控制、断点等
- 改用分位数 DiD / CiC:如果问题是函数形式,不是趋势
最低工资案例的“现代”重审
Dube, Lester & Reich (ReStat 2010)
用毗邻郡配对作为对照(更严格的局部比较),重新估计最低工资对就业的影响:
- 结论与 Card-Krueger 一致:就业效应接近零
- 说明对照组选择对 DiD 结论的影响有多大
- 启示:DiD 不是“黑盒”,对照组选择本身是识别策略的一部分
提示
经验法则
- 最近邻比较通常优于“全国其他州”——减少异质性
- 多种对照组都给相似结论,是最有力的稳健性证据
本讲要点
本讲要点(一)
- 面板数据解锁了“组内变异”
- 同一单位的时间变化量识别处理效应
- 固定效应扣除 \theta_i,消灭时不变的遗漏变量
- 经典 2×2 DiD 的精髓
- 用对照组前后变化构造“反事实”
- 识别假设:平行趋势 + 无预期
- 事件研究图同时呈现预趋势与动态效应
- 平行趋势不可直接检验
- 预趋势检验是必要不充分条件
- 滥用趋势控制可能吸收真实效应
本讲要点(二)
- 聚类标准误是 DiD 的“必修课”
- 面板误差几乎总有序列相关,忽视就过度拒绝
- BDM(2004):不聚类时 45% 假阳性
- 聚类到政策分配层级,G < 50 时用 Wild Bootstrap
- DiD 研究的七项稳健性清单
- 写论文时对照自检;审稿时抢先回答
- 预趋势、安慰剂、替代对照、聚类敏感——全部在附录
下节课预告
第 4 周:交错处理、现代 DiD 与合成控制
- 动态处理效应:为什么 Ashenfelter dip 会“搅乱”平行趋势?
- Goodman-Bacon 分解:TWFE 在交错处理下为何出现负权重?
- 现代修复:Callaway-Sant’Anna、Sun-Abraham、Borusyak et al.
- 合成控制法:只有一个处理单位时的“加权反事实”
核心思想
经典 DiD 在 2×2 下是“干净的”;但现实里政策分批推进——届时 TWFE 可能给出错误符号的估计量。我们需要新的工具去看清楚发生了什么。
参考文献
- Abadie, A., Athey, S., Imbens, G. W., & Wooldridge, J. M. (2023). When should you adjust standard errors for clustering? Quarterly Journal of Economics, 138(1), 1–35.
- Almond, D., Chay, K. Y., & Lee, D. S. (2005). The costs of low birth weight. Quarterly Journal of Economics, 120(3), 1031–1083.
- Bertrand, M., Duflo, E., & Mullainathan, S. (2004). How much should we trust differences-in-differences estimates? Quarterly Journal of Economics, 119(1), 249–275.
- Cameron, A. C., Gelbach, J. B., & Miller, D. L. (2008). Bootstrap-based improvements for inference with clustered errors. Review of Economics and Statistics, 90(3), 414–427.
- Cameron, A. C., Gelbach, J. B., & Miller, D. L. (2011). Robust inference with multiway clustering. Journal of Business & Economic Statistics, 29(2), 238–249.
- Cameron, A. C., & Miller, D. L. (2015). A practitioner’s guide to cluster-robust inference. Journal of Human Resources, 50(2), 317–372.
- Card, D., & Krueger, A. B. (1994). Minimum wages and employment: A case study of the fast-food industry in New Jersey and Pennsylvania. American Economic Review, 84(4), 772–793.
- Dube, A., Lester, T. W., & Reich, M. (2010). Minimum wage effects across state borders. Review of Economics and Statistics, 92(4), 945–964.
- Wooldridge, J. M. (2010). Econometric Analysis of Cross Section and Panel Data (2nd ed.), Ch. 10–11. MIT Press.