变量 类型 缺失率 是否关键
outcome float 0.00 是
treatment int 0.00 是
age int 0.02 是
prior_sales float 0.11 是
region category 0.00 是
text_note string 0.07 否机器学习与因果推断
第十二讲:前沿专题——因果推断与 AI,大语言模型的应用
陈志远
中国人民大学商学院
2026-06-09
学期回顾
因果推断与机器学习
- 潜在结果分析框架:经典因果推断的理论基础
- DAG:识别假设的可视化工具
- 机器学习基本工具:回归、决策树、随机森林、交叉验证
- 因果机器学习–异质性处理效应:因果森林,双重机器学习
最终的问题
- 学会了估计工具之后,如何把 AI 纳入完整研究流程?
- 哪些工作适合交给大语言模型,哪些绝不能外包?
- 如何用 vibe coding 提速,又不牺牲识别、验证与复现?
AI 协作研究
核心转折
AI 不是识别策略的替代品,而是研究 workflow 的放大器。
从估计工具到研究 workflow
AI 在因果研究中的位置
AI 最适合做的事
- 问题分解:把模糊研究问题拆成被估量(estimand)、样本和假设
- 代码脚手架:快速生成数据审计、建模、作图原型
- 文本结构化:把非结构化材料转成表格、标签和摘要
- 复现辅助:整理分析日志、稳健性清单和 write-up 草稿
AI 不能替代的事
- 识别假设是否可信
- 控制变量是否控制了中介变量而引入处理后偏差(Post-treatment bias)
- 数据边界、制度背景与样本构造
- 最终结论与学术责任
AI 能做什么,不能替代什么
| 环节 | AI 可以高效协助 | 研究者必须把关 |
|---|---|---|
| 问题定义 | 生成候选 estimand 与变量清单 | 判定研究问题是否有因果含义 |
| 识别设计 | 列出假设与 DAG 草图 | 判断假设是否在制度上成立 |
| 数据处理 | 生成探索性数据分析(Explorative Data Analysis, EDA)、清洗与特征工程脚手架 | 核对口径、样本选择与泄漏 |
| 估计推断 | 组织 DML、CATE、稳健性代码模板 | 审核模型选择与解释边界 |
| 写作表达 | 生成图表说明、报告框架与审稿清单 | 对结论负责并保证可复现 |
Vibe coding 的严谨版本
不是“随便写点提示词”
在研究场景里,vibe coding 指的是:
- 用自然语言描述任务
- 让 AI 生成第一版分析脚手架
- 用断言、测试和日志不断收紧结果
- 把输出沉淀成可复现工作流
高水平 vibe coding 的四个约束
- 结构化输入:变量字典、样本限制、识别目标
- 局部验证:每一步都能单独运行和检查
- 明确回滚:AI 生成内容可替换、可重写、可审计
- 人类裁决:所有识别与解释最终由研究者签字
例子:把研究问题拆成 estimand
原始问题
“平台给商家发券,到底能不能提高长期留存概率?”
| 元素 | 结构化表达 |
|---|---|
| 处理变量 | 是否收到定向优惠券 |
| 结果变量 | 30 天后是否继续活跃 |
| 目标参数 | ATE 或 ATT |
| 主要混杂 | 商家历史销量、地区、类目、平台评级 |
| 识别风险 | 平台可能把券发给更有潜力的商家 |
例子:AI 先给草图,人来做识别裁决
典型错误
AI 很容易把“发券后的点击率”“发券后的曝光量”也加入控制变量。
这些变量发生在处理之后,属于 post-treatment variables。
正确做法
- 让 AI 先列出候选控制变量
- 研究者逐个判断:变量是否发生在处理之前
- 把“可控制”“不可控制”“待讨论”分开记录
AI 辅助的因果分析工作流
从研究问题到可复现实验
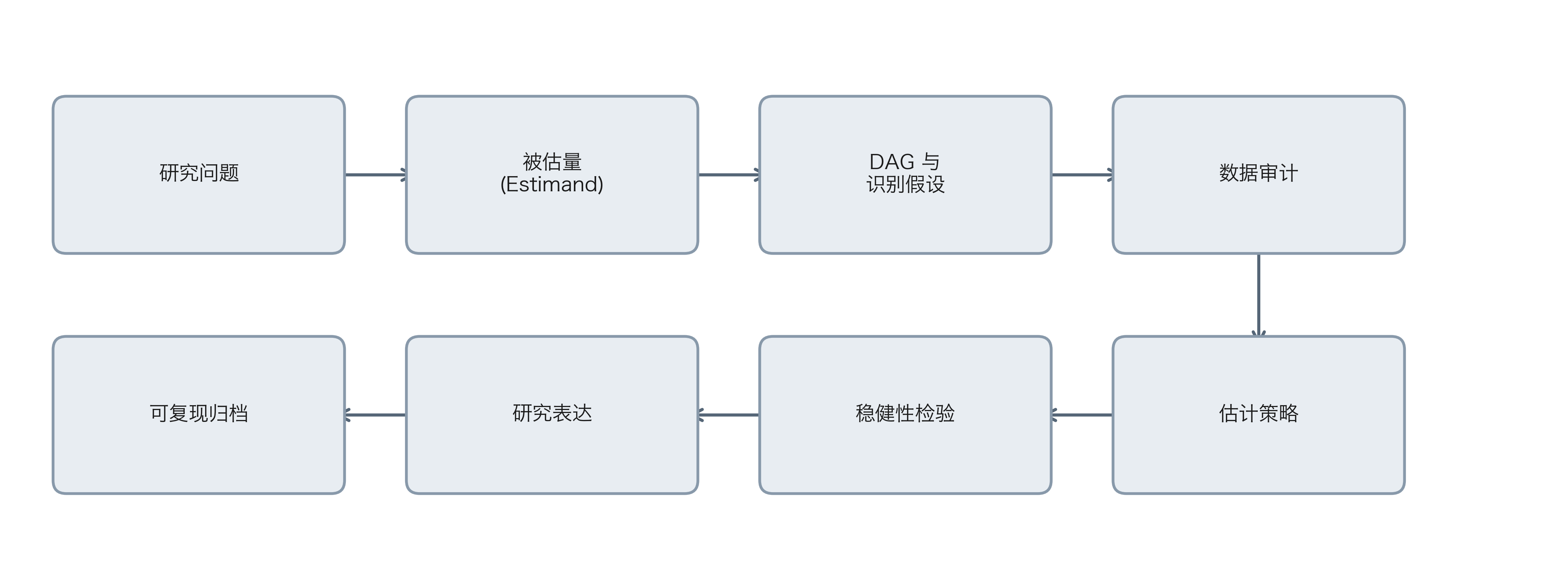
提示模板:先定义问题,再让 AI 干活
提示词最小充分上下文
- 数据结构:每列变量的定义、时间点与单位
- 研究目标:ATE、ATT、CATE 还是 policy learning
- 样本限制:时间窗、剔除规则、缺失处理
- 验证要求:输出代码、检查项、风险提示、日志
数据审计:让 AI 先读架构(schema),人来定样本
数据审计不是机械清洗
- 先看变量:类型、缺失、异常值、时间顺序
- 再看样本:是否存在选择偏误、口径变化、重复观测
- 最后看识别:哪些变量可以安全控制,哪些不能
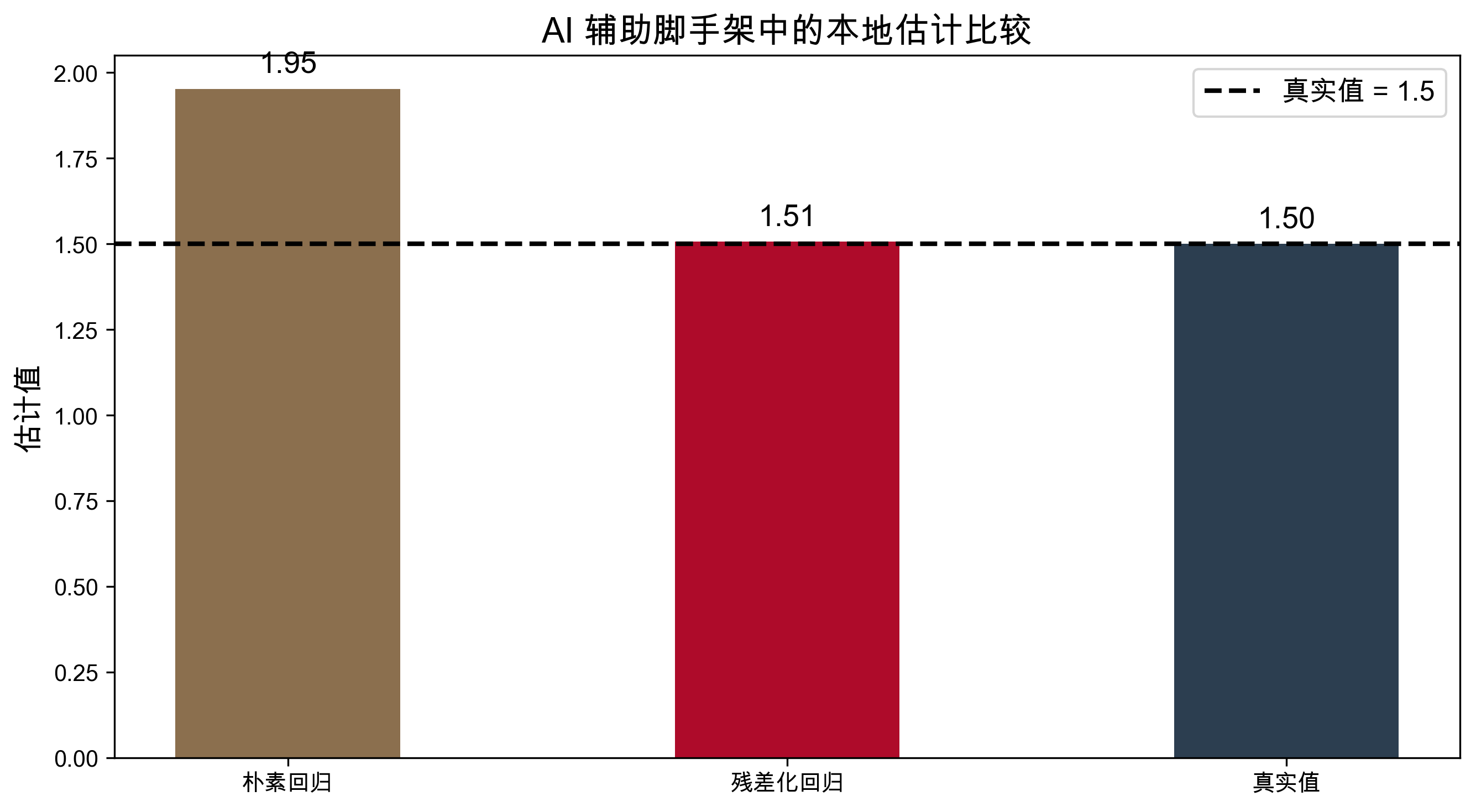
本地演示:高维混杂下的快速分析脚手架
解读
- 简单回归把混杂当成处理效应
- 残差化回归更接近第十一讲的 DML 思想
- AI 的价值不在替代估计工具,而在更快搭好并审查这条分析链
估计结果可视化
写作与复现:AI 最适合产出哪些中间品?
| 中间品 | AI 可以生成 | 人类要检查 |
|---|---|---|
| 分析计划 | 研究流程、变量字典、检查清单 | 是否遗漏关键假设 |
| 代码脚手架 | 导包、建模模板、作图模板 | 是否存在样本泄漏、错误控制 |
| 报告草稿 | 图表说明、结果摘要、局限性模板 | 是否过度外推、是否把相关当因果 |
| 审稿清单 | 反问式 checklist | 是否覆盖识别、稳健性、外部效度 |
大语言模型的具体应用场景
场景一:文献矩阵与研究设计
高价值用法
把 5 篇论文摘要整理成“研究问题—处理—结果—识别—数据—局限性”矩阵。
这样能快速看到哪些论文是随机实验、哪些是工具变量、哪些是DML。
| 论文 | 处理 | 结果 | 估计对象 | 主要风险 |
|---|---|---|---|---|
| 平台补贴研究 | 补贴曝光 | 留存 | ATE | 自选择 |
| 培训项目评估 | 培训参与 | 工资 | ATT | 样本流失 |
| 信贷政策研究 | 政策覆盖 | 营收增长 | LATE | 外溢效应 |
场景二:文本变量构造
LLM 最擅长的不是“下因果结论”
而是把文本、访谈、政策文件、客服记录整理成结构化变量。
典型任务
- 给政策文本打标签:监管、补贴、处罚、信息披露
- 从访谈纪要提取处理时点、参与主体、执行强度
- 把开放式问题整理成可回归的分类变量
Python 演示:结构化输出先验证再入库
关键原则
- 先要求 AI 输出 JSON 或表格
- 再验证字段是否完整、标签是否在白名单内
- 最后才允许进入估计环节
场景三:大数据探索与 SQL 草案
正确姿势
让 AI 起草查询,再在本地数据库执行。
不要把大数据直接扔给 LLM,也不要让它在没有架构(schema)的情况下自由发挥。
推荐 workflow
- 给 AI 变量表、样本口径和目标指标
- 让 AI 先写 SQL 或 pandas 草案
- 本地运行并核对聚合逻辑
- 把最终查询纳入版本控制
场景四:调试、审稿与结果解释
| 任务 | AI 的高价值输出 | 研究者的终审重点 |
|---|---|---|
| Debug | 定位异常值、语法错误、维度不匹配 | 是否修坏了识别逻辑 |
| 审稿模拟 | 列出威胁识别的反对意见 | 哪些质疑需要新实验或新稳健性 |
| 结果解释 | 按模板说明 estimand、CI、边界条件 | 是否偷换结论、是否过度宣传 |
失败案例:为什么不能把识别交给 AI
最危险的三种幻觉
- 把预测准确率误当因果识别
- 把 post-treatment variable 当作控制变量
- 把数据相关性包装成制度机制
提示
纪律
- AI 给的是候选答案,不是最终结论
- 每一个 AI 建议都要回答四个问题:它替代了什么劳动?可能犯什么错?如何验证?失败后如何回退?
AI 时代的研究能力升级
验证循环
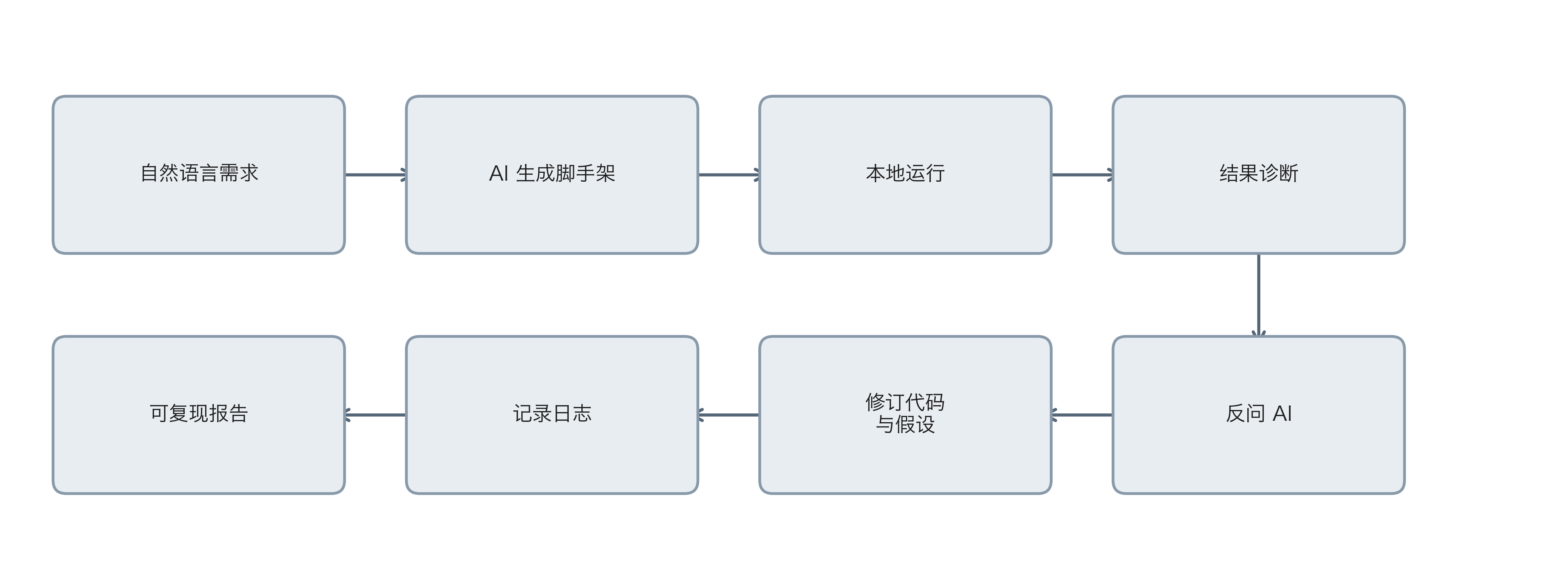
人机分工矩阵
| 层级 | AI 更强 | 研究者更强 |
|---|---|---|
| 信息处理 | 摘要、归类、补全模板 | 提出问题、判断重点 |
| 代码原型 | 搭脚手架、重构、补文档 | 审核逻辑、设计测试 |
| 识别设计 | 罗列可能方案 | 判断制度背景与可信度 |
| 研究表达 | 生成初稿、图注、问答稿 | 负责叙事、边界与学术声誉 |
研究能力栈
AI 时代的研究者
不只是会写回归代码,还要同时具备:
- 识别能力:知道什么可以识别,什么不能
- 工程能力:会把分析流程拆成可执行模块
- 验证/评审能力:能审查 AI 输出并快速回退
- 表达能力:把证据、假设与局限说清楚
从“会跑数据”到“会驾驭 workflow”
- 能让 AI 写第一版
- 能发现第一版哪里错
- 能把正确版本沉淀成团队与同行资产
- 快速迭代,不断升级
推荐工具
提示
本地分析工具
pandas:数据清洗与审计scikit-learn:交叉验证、基线模型、特征工程econml/DoubleML:因果估计Quarto:把分析、图表、解释合成一份可复现讲义
提示
AI 协作工具
- LLM 聊天界面:问题分解与提示草拟
- 代码代理:脚手架、重构、单元检查
- Git:记录版本、回滚、对比变更
- 审稿清单:保证输出始终能被人类复核
本讲要点(一)
- AI 是 workflow 放大器
- 它提升的是问题分解、脚手架生成、文本结构化与写作协作
- 识别永远不能外包
- 因果识别来自制度、时间顺序和研究设计,不来自提示词
- vibe coding 必须有约束
- 结构化输入、局部验证、明确回滚、人类终审缺一不可
本讲要点(二)
- 高价值 AI 场景
- 文献矩阵、文本变量构造、SQL 草案、结果解释、审稿模拟
- 每一步都要留下证据
- 代码、日志、图表、稳健性结果都应纳入可复现流程
- AI 时代真正稀缺的是判断力
- 能把 AI 输出转化为可靠研究资产的人,才具备研究竞争力
课程收官:项目答辩与研究展示
- 如何用清晰的识别逻辑讲好你的研究故事
- 如何展示数据、代码、稳健性与 AI 协作日志
- 如何把“会做分析”呈现成“会做研究”
提示
最后的核心能力
真正的优势不是让 AI 替你做研究,而是让 AI 帮你更快地提出问题、验证问题,并把答案组织成可信证据。
从 workflow 到终极追问
科学研究的本质是什么?
研究不是“生产文本”,而是“生产可检验的新解释”
- 用明确问题把世界切开
- 用证据区分看起来合理与经得起检验
- 用可复现流程让别人能够反驳、修正、继承
所以真正稀缺的不是生成速度,而是:
- 你提出了什么值得问的问题
- 你愿意接受什么证据作为回答
- 你如何设计让自己也可能被推翻的检验
人类的思考是独特的吗?
如果把“思考”理解为模式组合,AI 当然会越来越强。
但研究并不只是在已有语料上做重组。
人类仍有三个难以外包的维度
- 选择问题:什么值得研究,本身带有价值判断
- 承担责任:结论进入社会后,谁为误判负责
- 赋予意义:把事实、制度与人的处境连接起来
如果 AI 超过人类,对于人类意味着什么?
这不只是效率问题,而是认知秩序(Epistemic Order)的变化。
当 AI 能更快提出假说、跑实验、写论文时,瓶颈会从“生产知识”转向“筛选、解释与治理知识”。
对研究者的含义
- 研究不再稀缺,可信度会更稀缺
- 论文不再稀缺,判断哪些值得信会更稀缺
- 自动化不再是终点,如何治理自动化才是终极问题
最后的追问
注记
也许未来最重要的能力,不是比 AI 更快,而是比 AI 更知道什么值得慢下来。
- 在海量候选答案里,坚持追问真正的问题
- 在高效自动化面前,保留怀疑、节制与责任
- 在“模型比人更强”之后,重新定义人的角色:提问者、裁决者、承担者
参考文献
工作流与复现
- [GitHub] Assaf Elovic. GPT Researcher. https://github.com/assafelovic/gpt-researcher
- 自动化深度研究代理,强调 planner + execution agents、来源追踪、报告聚合与 observability,适合展示“AI 如何把 research 任务组织成可重复流程”。
- [GitHub] Hugging Face. smolagents. https://github.com/huggingface/smolagents
- 以 code agents 为核心的轻量代理框架,突出“agents that think in code”、工具调用、sandbox 执行和 agentic workflow benchmark,适合说明 vibe coding 与代码代理的工程化实现。
- [GitHub] Microsoft Research / community. AutoGen. https://github.com/microsoft/autogen
- 多代理编排框架,文档展示了 MCP、multi-agent orchestration 与 no-code studio 等模式,适合说明研究工作流如何分解为多个专门角色协作。
- [Web] The Turing Way Community. Guide for Reproducible Research. https://book.the-turing-way.org/reproducible-research/reproducible-research.html
- 公开的可复现研究指南,系统强调 version control、testing、computational environment 与 data/code 复跑,是 automated research workflow 中“可验证、可复现”原则的最好支撑材料之一。
自动化社会科学与 AI 科学家
- [GitHub] Kehang Zhu et al. Automated Social Science: Language Models as Scientist and Subjects. https://github.com/KeHang-Zhu/lm-automated-social-science/tree/main
- 该项目把 LLM 同时当作“科学家”和“受试主体”,从自然语言场景出发自动构建 SCM、模拟互动并输出可分析结果,适合说明 AI 如何进入社会科学实验与机制建模。
- [Web] Social Catalyst Lab. Project APE: Autonomous Policy Evaluation. https://ape.socialcatalystlab.org/
- APE 公开展示 AI 端到端生成政策评估论文、自动锦标赛比较与人工反馈回路,特别适合课堂讨论“自动化研究系统如何公开暴露失败、并用评审机制逼近可靠性”。
- [GitHub] Sakana AI. The AI Scientist. https://github.com/SakanaAI/AI-Scientist
- 这是一个强调自动提出想法、运行实验、生成论文并进行模型审稿的系统,也明确提示会执行模型生成代码并要求容器化与责任披露,适合讨论“自动科学家”的能力边界与风险治理。
- [GitHub] EvoScientist Team. EvoScientist. https://github.com/EvoScientist/EvoScientist
- EvoScientist 把 research workflow 组织成多代理、持久记忆和 verify loop,并明确提出 human-on-the-loop 范式,适合补充说明“未来研究者更像编排者与裁决者,而非唯一执行者”。