from sklearn.linear_model import LinearRegression, LassoCV
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_predict
# ===== 模拟数据:部分线性模型 =====
n = 2000
p = 10
X = np.random.normal(0, 1, (n, p))
# 非线性混杂函数 g₀(X):影响结果 Y
g0 = X[:, 0]**2 + 2 * np.sin(X[:, 1]) + 0.5 * X[:, 2] * X[:, 3]
# 处理方程 m₀(X):影响处理分配 D
m0 = 0.8 * X[:, 0] + 0.5 * X[:, 1] - 0.3 * X[:, 2]
# 二值处理变量(受 X 混杂)
D = (m0 + np.random.normal(0, 1, n) > 0).astype(float)
# 真实处理效应
theta_0 = 2.0
# 观测结果
Y = theta_0 * D + g0 + np.random.normal(0, 1, n)
# ===== 预计算 OLS =====
DX = np.column_stack([D.reshape(-1, 1), X])
ols = LinearRegression().fit(DX, Y)
theta_ols = ols.coef_[0]
# OLS 回归:以线性方式控制 X
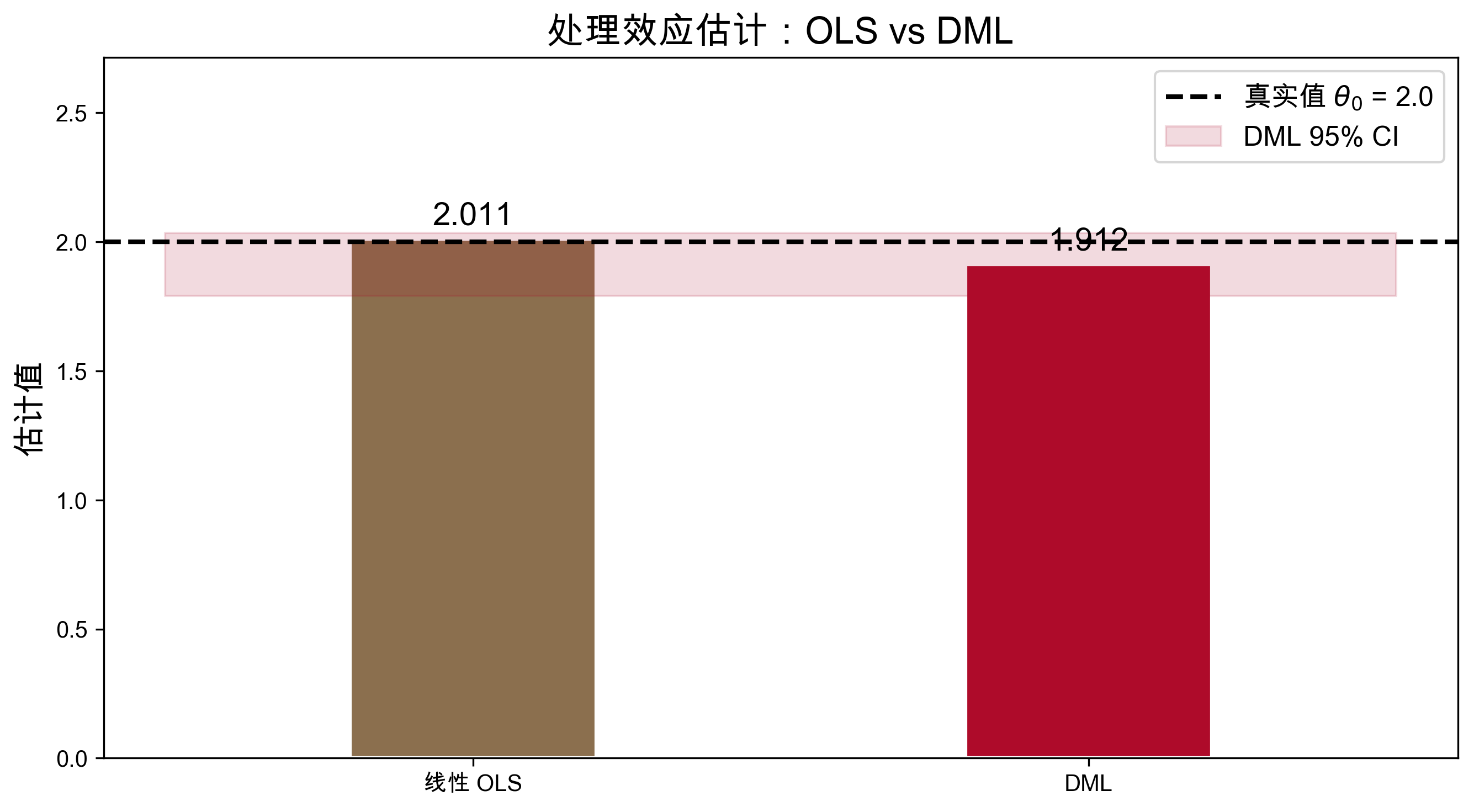
print(f"真实处理效应: theta_0 = {theta_0:.3f}")
print(f"OLS(线性控制): hat_theta = {theta_ols:.3f}")
print(f"偏差: {theta_ols - theta_0:+.3f}")
print()
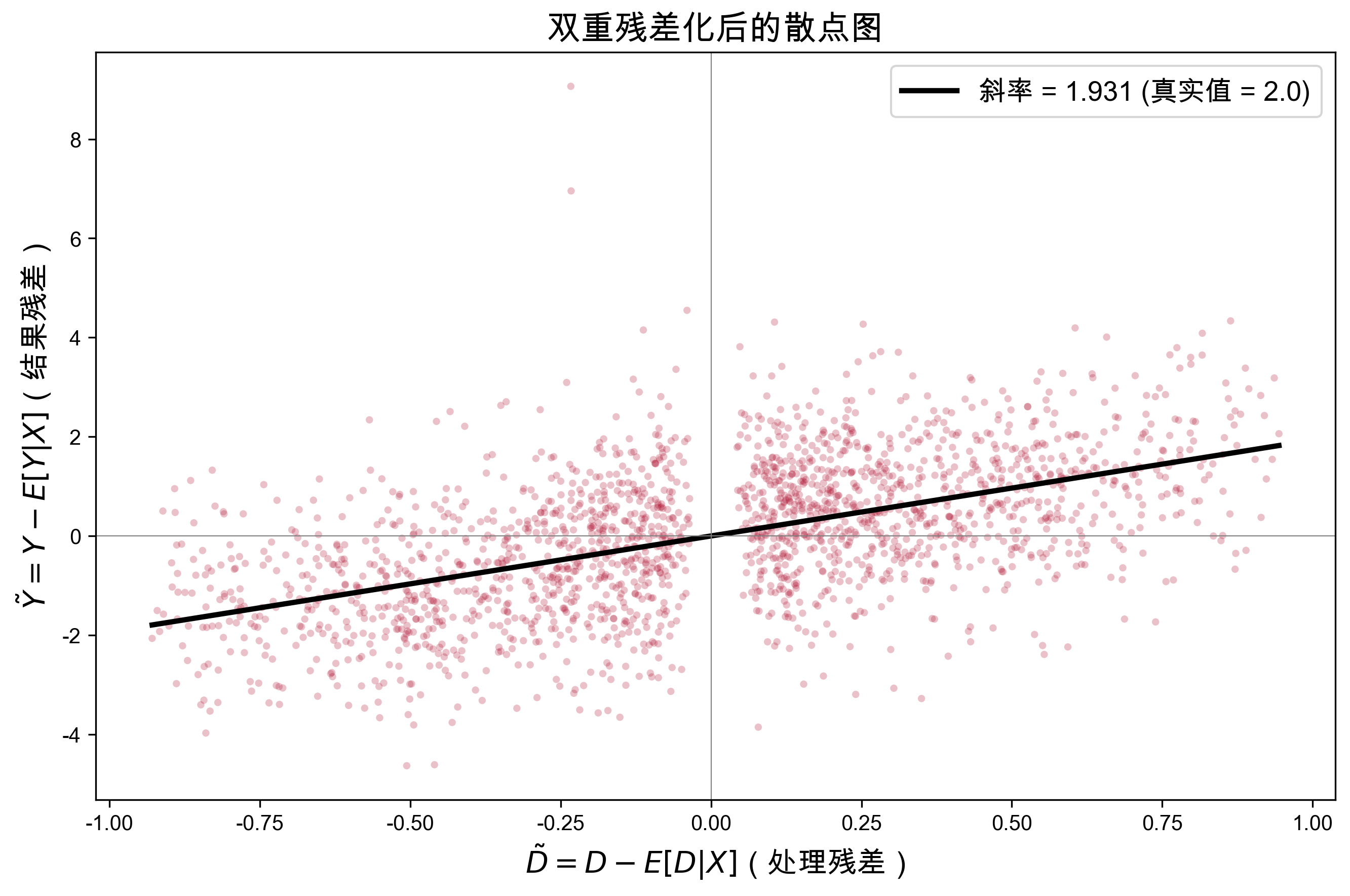
print("OLS 存在设定偏误:")
print(" g_0(X) 包含 X^2 和 sin(X) 等非线性项,")
print(" 线性控制无法完全消除混杂")真实处理效应: theta_0 = 2.000
OLS(线性控制): hat_theta = 2.011
偏差: +0.011
OLS 存在设定偏误:
g_0(X) 包含 X^2 和 sin(X) 等非线性项,
线性控制无法完全消除混杂