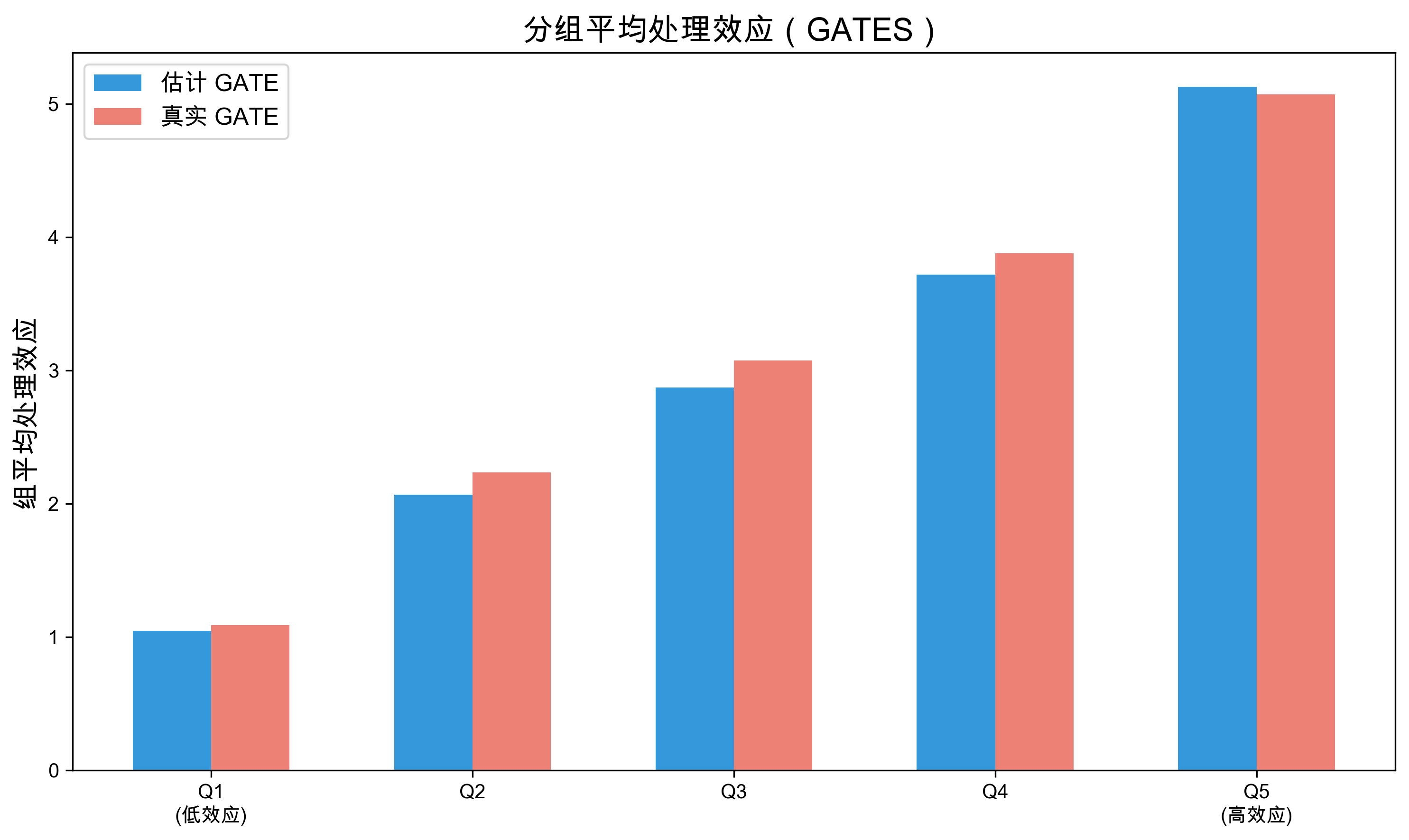
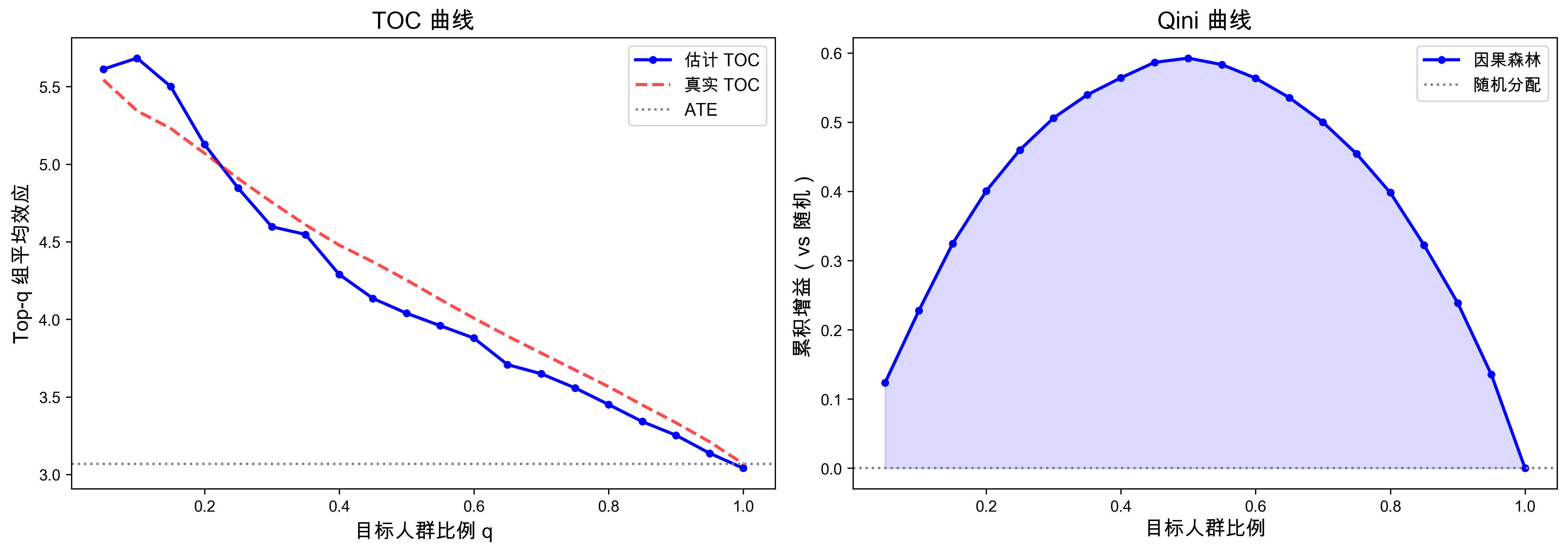
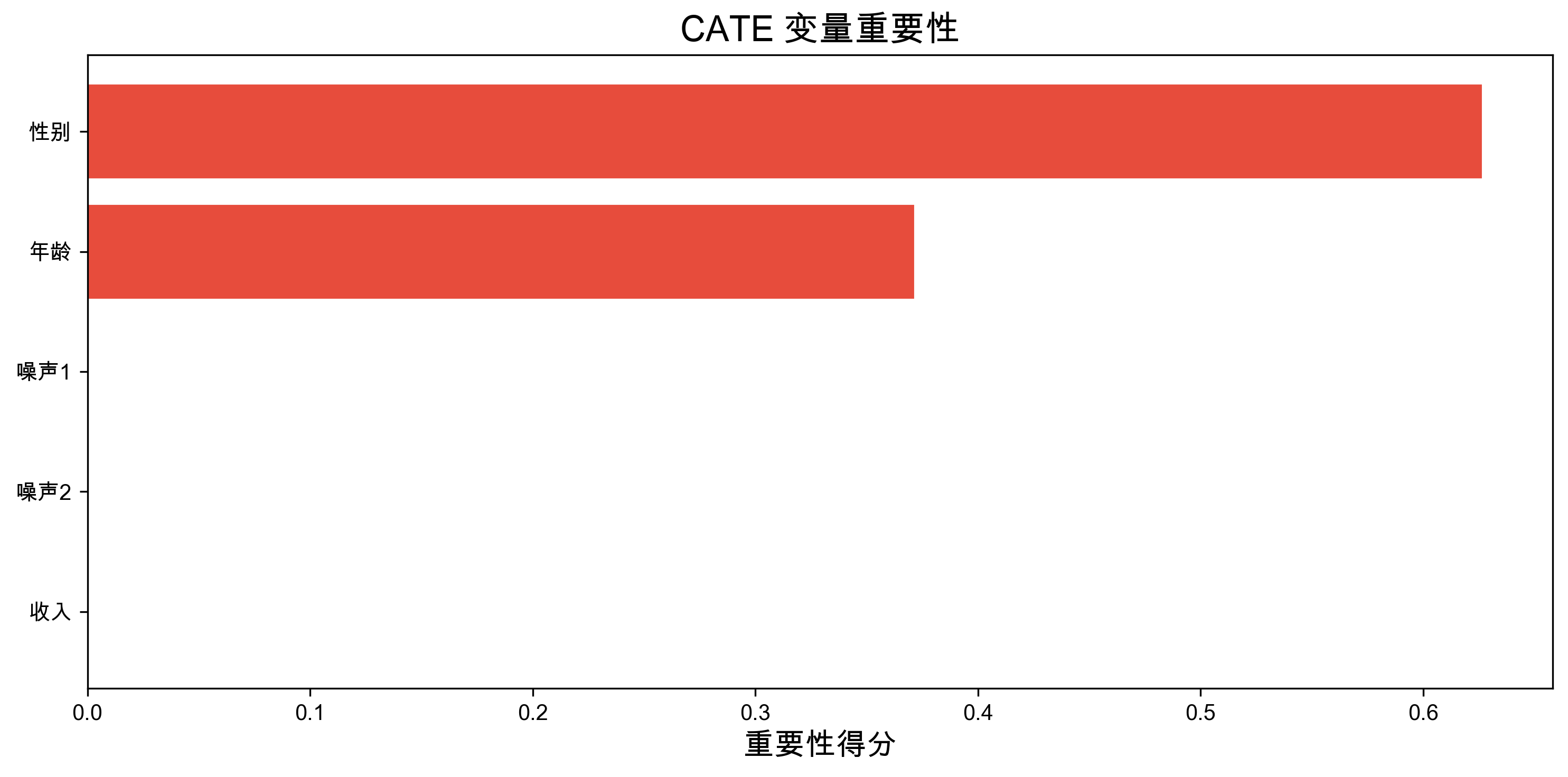
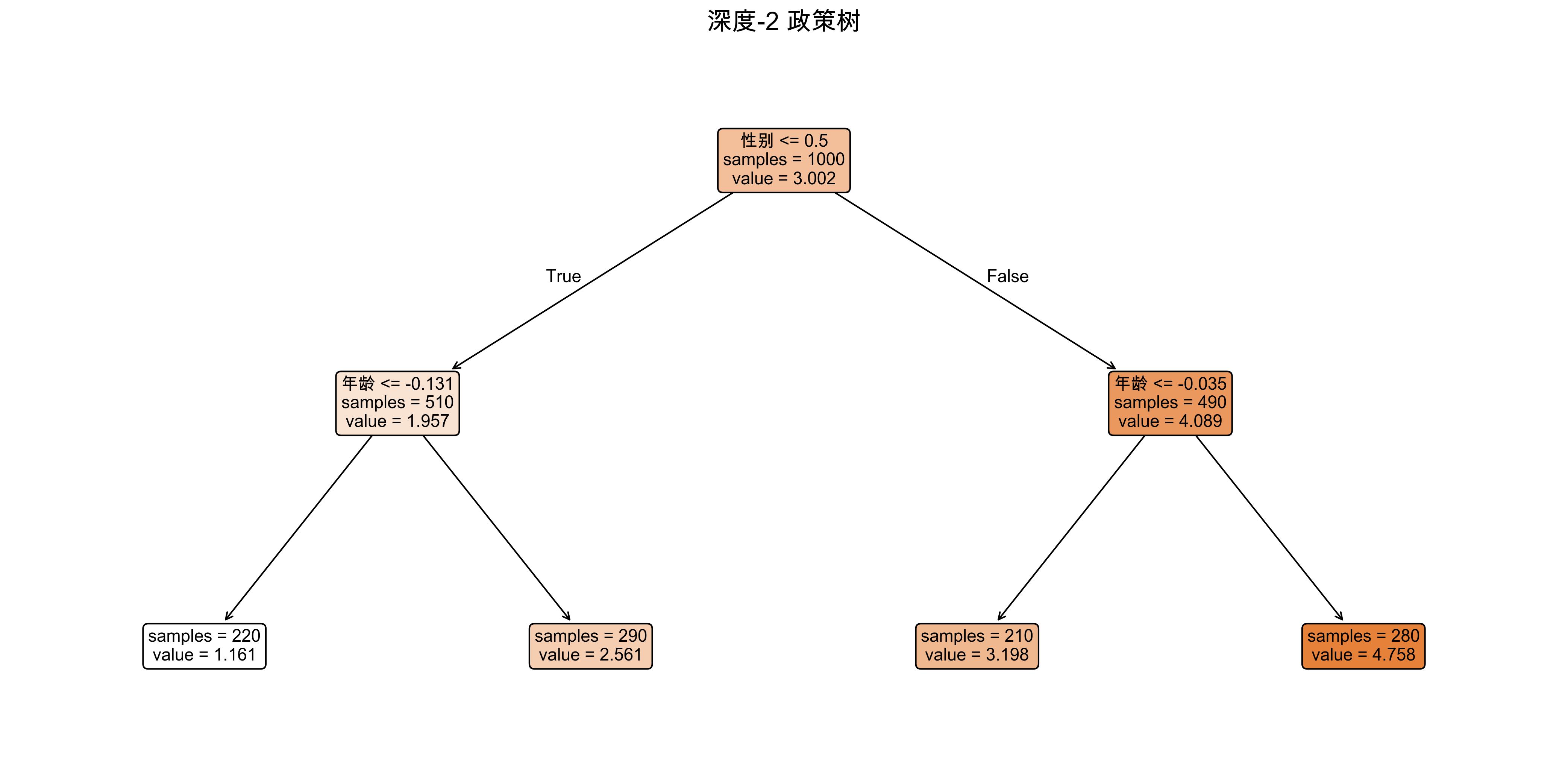
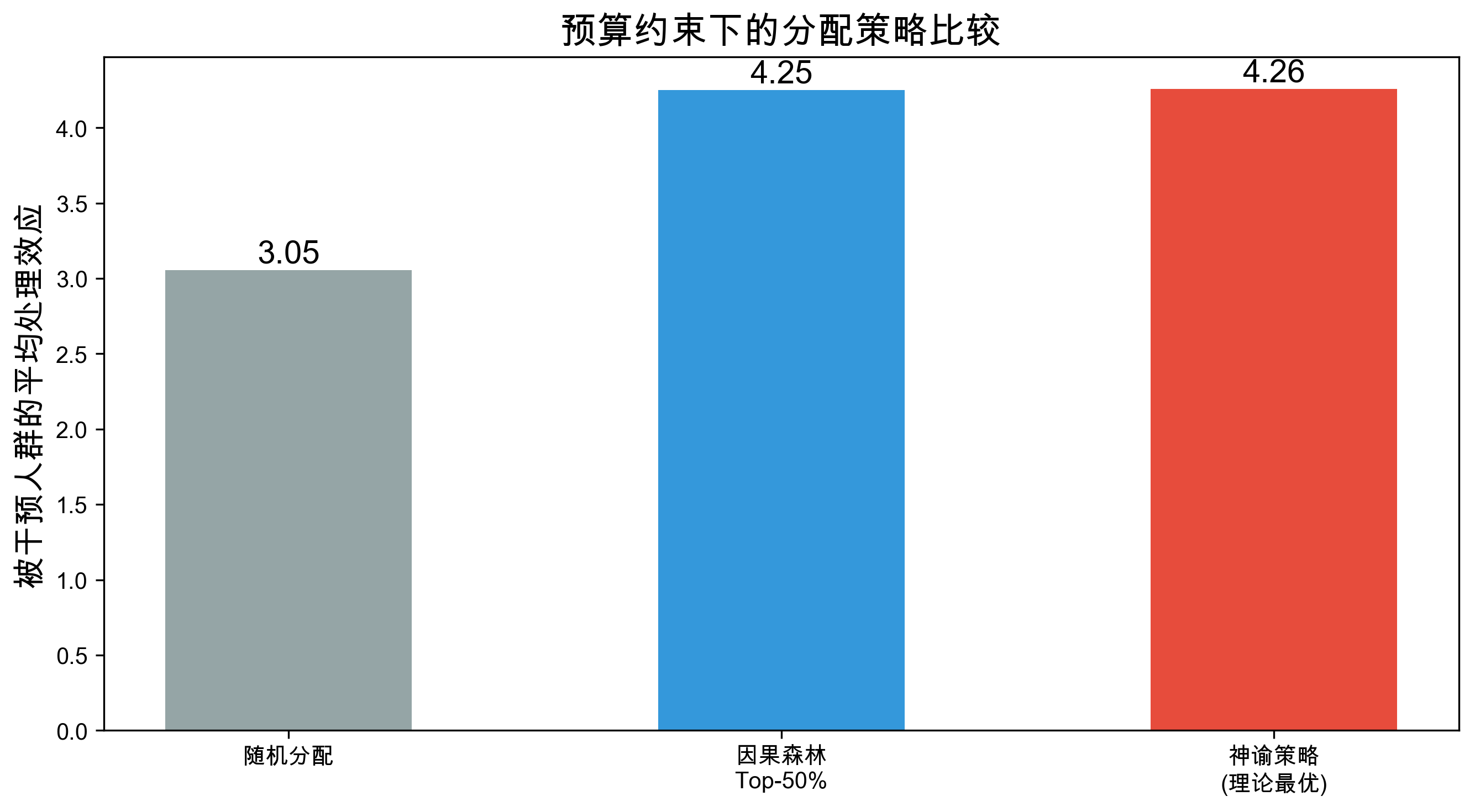
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
sorted_idx = np.argsort(-tau_hat)
# 左图:TOC 曲线
fracs = np.linspace(0.05, 1.0, 20)
toc_est, toc_true = [], []
for q in fracs:
k = int(q * n_te)
idx = sorted_idx[:k]
toc_est.append(Y_te[idx][T_te[idx]==1].mean() - Y_te[idx][T_te[idx]==0].mean())
toc_true.append(np.mean(tau_true_te[idx]))
axes[0].plot(fracs, toc_est, 'b-o', ms=4, lw=2, label='估计 TOC')
axes[0].plot(fracs, toc_true, 'r--', lw=2, alpha=0.7, label='真实 TOC')
axes[0].axhline(np.mean(tau_true_te), color='gray', ls=':', label='ATE')
axes[0].set_xlabel('目标人群比例 q', fontsize=13)
axes[0].set_ylabel('Top-q 组平均效应', fontsize=13)
axes[0].set_title('TOC 曲线', fontsize=15, fontweight='bold')
axes[0].legend(fontsize=11)
# 右图:Qini 曲线
ate = np.mean(tau_true_te)
qini_vals = [q * (t - ate) for q, t in zip(fracs, toc_true)]
axes[1].plot(fracs, qini_vals, 'b-o', ms=4, lw=2, label='因果森林')
axes[1].axhline(0, color='gray', ls=':', label='随机分配')
axes[1].fill_between(fracs, 0, qini_vals, alpha=0.15, color='blue')
axes[1].set_xlabel('目标人群比例', fontsize=13)
axes[1].set_ylabel('累积增益(vs 随机)', fontsize=13)
axes[1].set_title('Qini 曲线', fontsize=15, fontweight='bold')
axes[1].legend(fontsize=11)
plt.tight_layout(); plt.show()