import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
n = 2000
# 个体特征
X = np.random.normal(size=(n, 5))
# 处理分配(含混杂:X₃ 影响处理概率)
propensity = 1 / (1 + np.exp(-0.5 * X[:, 3]))
T = np.random.binomial(1, propensity)
# 真实 CATE:τ(x) = 1 + 2·X₀(线性异质性)
tau_true = 1 + 2 * X[:, 0]
# 观测结果
Y = tau_true * T + X[:, 1] + 0.5 * X[:, 3] + np.random.normal(size=n)机器学习与因果推断
第九讲:广义随机森林——异质性处理效应
陈志远
中国人民大学商学院
2026-05-19
上节课回顾
机器学习基础 II
- 正则化回归:Ridge(L_2)均匀收缩系数,LASSO(L_1)自动变量选择
- 梯度提升:顺序训练弱学习器拟合残差,XGBoost 是工业级实现
- 模型选择:AIC/BIC 信息准则 vs 交叉验证直接估计样本外误差
- 从预测到因果:ML 在因果推断中的三大角色——高维控制、异质性效应、去偏估计
本节课目标
- 理解异质性处理效应(HTE)的概念与政策意义
- 掌握从随机森林到因果森林的核心思想转变
- 了解广义随机森林(GRF)的算法框架与置信区间
- 通过 Python 实战体验 CATE 估计
为什么关注异质性处理效应
平均效应背后的异质性
案例:在线教育干预
某大学测试新的 AI 辅导系统对学生成绩的影响。随机对照实验结果:
- 平均处理效应 ATE = +5 分(统计显著)
- 结论:全校推广?
仔细看看不同群体
| 学生类型 | 处理效应 |
|---|---|
| 基础薄弱的学生 | +15 分 |
| 中等水平的学生 | +3 分 |
| 成绩优秀的学生 | −2 分 |
ATE 掩盖了巨大的异质性!精准政策需要知道 谁受益、谁不受益
条件平均处理效应(Conditional Average Treatment Effect, CATE)
CATE 的定义
\tau(x) = E[Y(1) - Y(0) \mid X = x]
给定个体特征 X = x,处理效应的条件期望。
CATE 是一个函数,不是一个数字——它描述了效应如何随个体特征变化。
三个层次的处理效应
- ATE:所有人的平均 → E[\tau(X)],一个数
- CATE:特定人群的效应 → \tau(x),一个函数
- ITE:单个个体 → Y_i(1) - Y_i(0),永远无法同时观测
CATE 的政策价值
三个真实政策场景
- 精准医疗:哪些患者对某种新药反应最好?
- 金融营销:优惠券应该发给谁才能最大化利润?
- 教育政策:补贴应该优先投向哪类学校?
核心问题
\text{最优政策} = \begin{cases} \text{干预} & \text{如果 } \tau(x) > c \text{(成本阈值)} \\ \text{不干预} & \text{如果 } \tau(x) \leq c \end{cases}
→ 要做出最优决策,我们需要 估计 \tau(x)
朴素方法:S-Learner 与 T-Learner
| 方法 | 核心思路 | 估计公式 | 优势 | 局限 |
|---|---|---|---|---|
| S-Learner (Single-Learner) | 用单个模型统一拟合处理组与对照组,将处理变量T 作为普通特征 | 用任意回归 / ML 模型(如随机森林、XGBoost)拟合: \hat{\mu}(X, T)= \hat{E}[Y \mid X, T],然后 \hat{\tau}(x) = \hat{\mu}(x,1) - \hat{\mu}(x,0) | 实现简单,处理连续/多值处理变量 | T 信号弱时被模型忽略 |
| T-Learner (Two-Learner) | 分别给处理/控制组建模 | \hat{\tau}(x) = \hat{\mu}_1(x) - \hat{\mu}_0(x) | 不容易低估效应,更关注干预差异 | 两个模型独立训练,不支持连续处理变量 |
| X-Learner (Cross-Learner) | 交叉残差 + 倾向得分加权 | 加权平均组内结果与交叉预测结果 | 适用于不平衡处理组 | 步骤复杂,依赖倾向得分 |
Meta-Learners 的共同问题
这些方法通常 不提供有效的置信区间——我们只有点估计,不知道估计有多可靠。
需要一种方法既能灵活估计 \tau(x),又能提供 统计推断。
我们需要什么样的方法
理想的 CATE 估计方法应当满足:
- 非参数灵活性——不预设 \tau(x) 的函数形式
- 自适应性——自动发现哪些特征驱动异质性
- 有效推断——提供渐近有效的置信区间
- 高维适应——在特征较多时仍然表现良好
答案:广义随机森林(GRF)
Athey, Tibshirani & Wager(2019)提出的 GRF 框架,基于 随机森林 + 局部矩条件,同时满足以上四个要求。
从随机森林到因果树
随机森林的核心思想回顾
随机森林 = 自适应最近邻
随机森林本质上是一种 数据驱动的相似度度量:
- 每棵树通过递归分裂将样本空间划分为若干叶节点
- 落入同一叶节点的样本被视为“相似”
- 森林权重 K(x, X_i):样本 X_i 与目标点 x 在所有树中 同叶比例
关键公式
K(x, X_i) = \frac{1}{B}\sum_{b=1}^{B} \frac{\mathbf{1}\{X_i \in L_b(x)\}}{|L_b(x)|}
- L_b(x) 是第 b 棵树中 x 所在的叶节点
- |L_b(x)| 是该叶节点的样本数
从预测到因果:换一种“目标”
| 预测树(回归树) | 因果树 | |
|---|---|---|
| 目标 | 预测 Y | 估计 \tau(x) = E[Y(1)-Y(0) \mid X=x] |
| 分裂准则 | 最大化 Y 的组间方差 | 最大化 处理效应 的组间差异 |
| 叶节点值 | \bar{Y} | \bar{Y}_{\text{treated}} - \bar{Y}_{\text{control}} |
| 评判标准 | 预测精度(MSE) | 效应估计的准确性 |
核心转变
预测树问Y 在哪里不同?,因果树问\tau(x) 在哪里不同?
因果树的分裂准则
最大化处理效应的异质性
在每个节点,寻找最优分裂使子节点间的处理效应差异最大:
\max_{S_1, S_2} \hat{\tau}(S_1)^2 \cdot |S_1| + \hat{\tau}(S_2)^2 \cdot |S_2|
其中 \hat{\tau}(S_k) = \bar{Y}_{S_k}^{\text{treated}} - \bar{Y}_{S_k}^{\text{control}} 是子节点 k 内的处理效应估计。
直觉
- 好的分裂:一组“受益很多”,另一组“受益很少”(甚至有害)
- 差的分裂:两组的处理效应差不多
诚实估计(Honest Estimation)
过拟合风险
如果用 同一批数据 既选择分裂点又估计叶节点效应,估计会有偏——因为分裂规则已经“窥探”了效应的方向。
解决方案:诚实分裂
将训练数据一分为二:
- 分裂样本(Splitting sample):决定树的结构(如何分裂)
- 估计样本(Estimation sample):估计叶节点中的处理效应
两步分离,确保估计的无偏性。
从单棵树到因果森林
单棵因果树的问题:
- 高方差——换一批数据,树的结构可能完全不同
- 分裂边界生硬——效应估计在叶节点间不平滑
解决方案:因果森林
- 训练 B 棵因果树(每棵使用 子采样 + 随机特征选择)
- 聚合所有树的预测
\hat{\tau}(x) = \sum_{i=1}^{n} K(x, X_i) \cdot \hat{\tau}_i
→ 方差大幅降低,估计更平滑
但普通因果森林还缺少两个关键能力:处理混杂因素(Confounding Factors) 和 提供置信区间
广义随机森林
GRF 的核心框架
广义随机森林的“广义”
GRF 将因果森林嵌入一个统一的估计框架——局部矩条件:
E[\psi_{\theta(x)}(O_i) \mid X_i = x] = 0
不同的 \psi 定义不同的因果参数:
- CATE 估计:\psi = (Y_i - \theta \cdot T_i) \cdot T_i(简化形式)
- 分位数处理效应:对应分位数矩条件
- 局部平均处理效应:对应 IV 矩条件
关键思想
GRF = “用森林学习相似度,用矩条件估计参数”
Robinson 变换:去除混杂
残差化思想
当存在混杂变量 W 时,直接分析 Y 和 T 的关系会有偏。Robinson(1988)变换的思路:
Y - E[Y \mid X, W] = \tau(X) \cdot (T - E[T \mid X, W]) + \varepsilon
三步过程
- 用 ML 模型估计 \hat{m}(X,W) = \hat{E}[Y \mid X, W],计算 \tilde{Y} = Y - \hat{m}
- 用 ML 模型估计 \hat{e}(X,W) = \hat{E}[T \mid X, W],计算 \tilde{T} = T - \hat{e}
- 用残差回归:\tilde{Y} = \tau(X) \cdot \tilde{T} + \varepsilon
Robinson变换本质上就是 Frisch-Waugh-Lovell 定理的非参数版本!
森林权重与局部估计
残差化之后,GRF 用局部加权回归估计 \tau(x):
\hat{\tau}(x) = \arg\min_{\theta} \sum_{i=1}^{n} K(x, X_i) \cdot (\tilde{Y}_i - \theta \cdot \tilde{T}_i)^2
森林权重 K(x, X_i) 的直觉
- 如果 X_i 和 x 在很多树中落入同一叶节点 → 权重高 → “很相似”
- 如果 X_i 和 x 很少同叶 → 权重低 → “不太相似”
森林自动学习了“谁和谁相似”——这个相似度度量是数据驱动的!
置信区间与统计推断
GRF 的渐近正态性
在温和的正则条件下,GRF 估计量是渐近正态的:
\frac{\hat{\tau}(x) - \tau(x)}{\hat{\sigma}(x)} \xrightarrow{d} N(0, 1)
其中 \hat{\sigma}(x) 可以通过 自助法 或 无穷小刀切法(Infinitesimal Jackknife)估计。
实际意义
- 可以构造逐点 95% 置信区间:\hat{\tau}(x) \pm 1.96 \cdot \hat{\sigma}(x)
- 可以检验 H_0: \tau(x) = 0(特定人群是否有显著效应)
- 这是 GRF 相对于普通 Meta-Learners 的最大优势
GRF 算法步骤总结
GRF 的完整估计流程:
残差化:用交叉拟合(Cross-fitting)估计 \hat{m} 和 \hat{e},计算残差 \tilde{Y}、\tilde{T}
构建因果森林:在残差上训练 B 棵子采样诚实因果树
计算森林权重:对于目标点 x,计算 K(x, X_i)
局部估计:用加权最小二乘求解 \hat{\tau}(x)
推断:通过 Jackknife 估计 \hat{\sigma}(x),构造置信区间
一句话总结GRF
GRF = 残差化(去混杂)+ 因果森林(学相似度)+ 局部回归(估 CATE)+ Jackknife(给 CI)
方法全景
| 方法 | 核心思想 | 置信区间 | 适用场景 |
|---|---|---|---|
| S/T-Learner | 直接建模 \mu_0, \mu_1 | ✗ | 快速探索 |
| X-Learner | 交叉残差 + 倾向得分 | ✗ | 处理/控制组不平衡 |
| 因果森林(GRF) | 森林权重 + 局部矩条件 | ✓ | 需要推断的场景 |
| DML + 森林 | 全局残差化 + 森林 | ✓ | 高维混杂 |
| DR-Learner | 双重稳健得分 + 森林 | ✓ | 离散处理 + 稳健性 |
选择建议
- 需要置信区间 → GRF 或 DML 森林
- 不需要推断,只要点估计 → Meta-Learners 更简单
- 高维混杂变量 → CausalForestDML(EconML)
Python 实战
步骤一:生成模拟数据
关键设计:X_0 决定处理效应异质性,X_3 是混杂变量
步骤二:拟合因果森林
from econml.dml import CausalForestDML
from sklearn.linear_model import LassoCV
# 构建 CausalForestDML 估计器
est = CausalForestDML(
model_y=LassoCV(), # Y 的一阶段模型
model_t=LassoCV(), # T 的一阶段模型
n_estimators=500, # 森林中树的数量
min_samples_leaf=10, # 叶节点最小样本数
random_state=42
)
# 拟合模型:X 用于发现异质性,W 用于控制混杂
est.fit(Y, T, X=X, W=X)
# 查看 ATE
print(f"估计的 ATE: {est.ate(X):.3f}")
print(f"真实的 ATE: {np.mean(tau_true):.3f}")估计的 ATE: 0.890
真实的 ATE: 0.982步骤三:估计 CATE 与置信区间
# 创建测试点:X₀ 从 -2 到 2,其他特征固定为 0
X_test = np.zeros((100, 5))
X_test[:, 0] = np.linspace(-2, 2, 100)
# CATE 点估计
tau_hat = est.effect(X_test)
# 95% 置信区间
lb, ub = est.effect_interval(X_test, alpha=0.05)
# 真实 CATE
tau_real = 1 + 2 * X_test[:, 0]
print(f"X₀ = -1 时:估计 τ = {tau_hat[25]:.2f}, 真实 τ = {tau_real[25]:.2f}")
print(f"X₀ = 0 时:估计 τ = {tau_hat[50]:.2f}, 真实 τ = {tau_real[50]:.2f}")
print(f"X₀ = 1 时:估计 τ = {tau_hat[75]:.2f}, 真实 τ = {tau_real[75]:.2f}")X₀ = -1 时:估计 τ = -0.91, 真实 τ = -0.98
X₀ = 0 时:估计 τ = 0.78, 真实 τ = 1.04
X₀ = 1 时:估计 τ = 2.74, 真实 τ = 3.06步骤四:可视化异质性效应
plt.figure(figsize=(10, 6))
plt.plot(X_test[:, 0], tau_real, 'b--', lw=2, label='真实 CATE')
plt.plot(X_test[:, 0], tau_hat, 'r-', lw=2, label='GRF 估计')
plt.fill_between(X_test[:, 0], lb, ub,
alpha=0.2, color='red', label='95% 置信区间')
plt.axhline(y=0, color='gray', ls=':', alpha=0.5)
plt.xlabel('$X_0$(驱动异质性的特征)')
plt.ylabel('CATE $\\tau(x)$')
plt.title('因果森林估计 vs 真实处理效应')
plt.legend(loc='upper left')
plt.grid(True, alpha=0.3)
plt.show()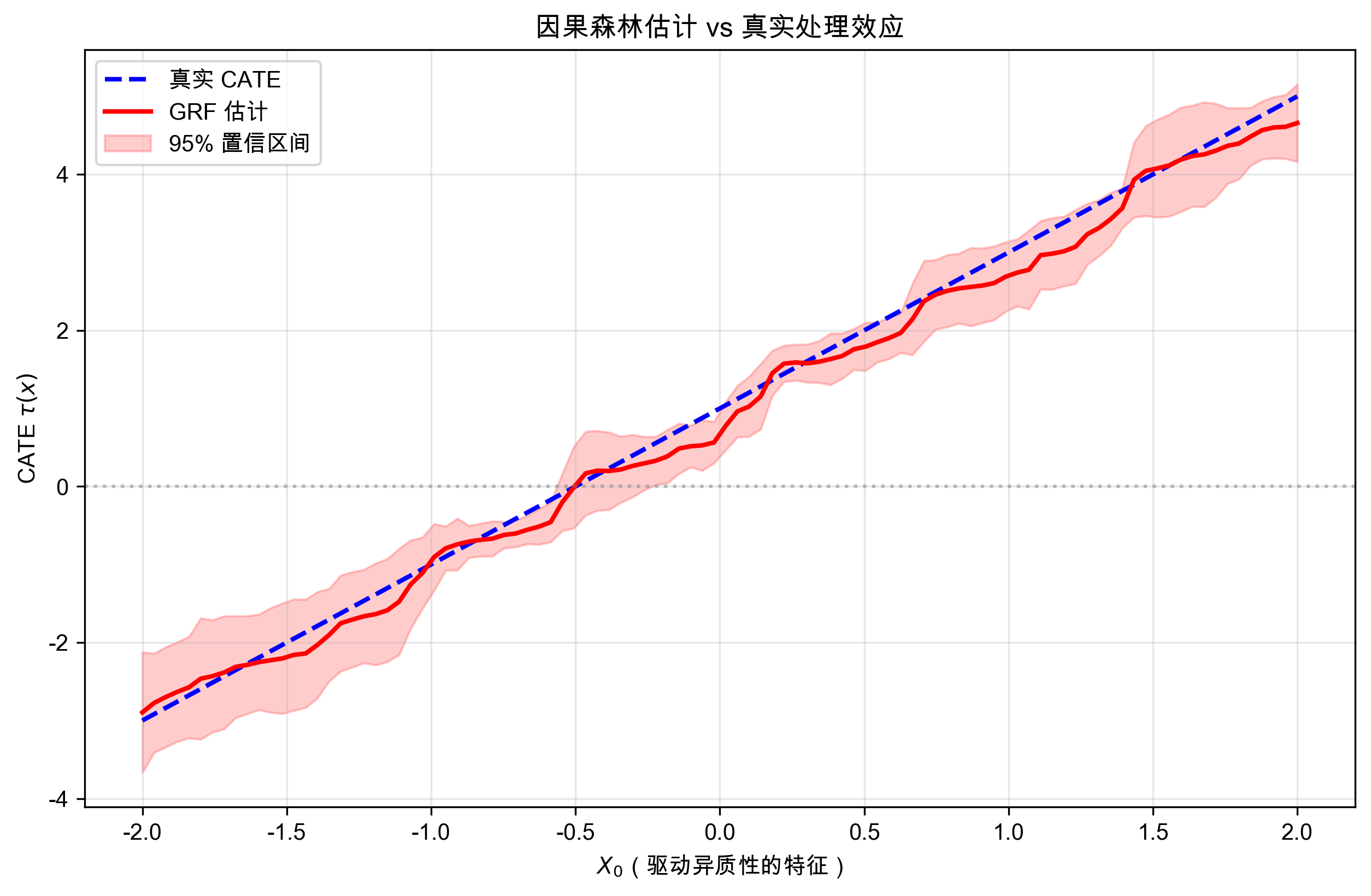
GRF 成功识别出线性异质性模式,置信区间覆盖真实值
应用案例
就业培训项目的异质性效应
美国 JTPA 就业培训实验
背景:美国政府于 1987–1989 年开展大规模随机对照实验,超过 20,000 名成年人被随机分配到就业培训或对照组。
ATE 结果:培训组在 30 个月后平均收入增加约 $1,800/年——效果显著但幅度适中。
问题:如果预算有限,能否找出 最受益的人群,精准投放培训资源?
异质性发现与政策启示
用因果森林分析 JTPA 数据,发现显著的异质性:
| 群体特征 | 估计 CATE | 95% CI |
|---|---|---|
| 年轻工人(<25 岁) | +$3,200/年 | [$1,800, $4,600] |
| 女性、有子女 | +$2,900/年 | [$1,500, $4,300] |
| 低学历(高中以下) | +$2,500/年 | [$1,200, $3,800] |
| 年长、有工作经验 | +$400/年 | [−$200, $1,000] |
政策启示
不是所有人都需要培训。GRF 帮助识别“高回报”群体,使有限的公共资源产生最大社会效益。这就是 数据驱动的精准政策。
本讲要点(一)
- 异质性处理效应(HTE)
- ATE 掩盖个体差异,CATE \tau(x) 刻画效应随特征的变化
- 精准政策需要估计“谁受益最多”
- 从随机森林到因果树
- 预测树最大化 Y 的可预测性,因果树最大化处理效应的异质性
- 诚实估计:分裂与估计使用不同样本,避免过拟合
本讲要点(二)
- 广义随机森林(GRF)
- Robinson 变换去除混杂(残差化),因果森林学习自适应相似度
- 局部加权回归估计 CATE,渐近正态性保证有效置信区间
- 实践要点
- Python 中用
econml.dml.CausalForestDML实现 - 关注置信区间而非仅仅点估计,用可视化展示异质性
- Python 中用
推荐工具
提示
Python
econml:CausalForestDML(推荐),DMLOrthoForestcausalml:Meta-Learners(S/T/X-Learner)scikit-learn:RandomForestRegressor(预测基准)
提示
R
grf:causal_forest(推荐,原始实现)policytree:基于 GRF 的最优政策树tidymodels:通用建模框架
下节课预告
第十讲:因果森林——异质性分析与政策学习
- 异质性检验:最佳线形预测器(Best Linear Predictor,BLP)方法
- 效应评估:RATE、AUTOC 与 Qini 曲线
- 变量重要性:哪些特征驱动了异质性
- 政策树:从估计到决策
核心思想
估计 CATE 只是第一步——更重要的是如何 评估 异质性是否真实存在,以及如何将估计结果转化为 最优决策规则。
参考文献
Athey, S., Tibshirani, J., & Wager, S. (2019). Generalized Random Forests. Annals of Statistics, 47(2), 1148–1178.
Wager, S., & Athey, S. (2018). Estimation and Inference of Heterogeneous Treatment Effects Using Random Forests. Journal of the American Statistical Association, 113(523), 1228–1242.
Athey, S., & Imbens, G. W. (2016). Recursive Partitioning for Heterogeneous Causal Effects. Proceedings of the National Academy of Sciences, 113(27), 7353–7360.
Künzel, S. R., Sekhon, J. S., Bickel, P. J., & Yu, B. (2019). Metalearners for Estimating Heterogeneous Treatment Effects Using Machine Learning. Proceedings of the National Academy of Sciences, 116(10), 4156–4165.
Robinson, P. M. (1988). Root-N-Consistent Semiparametric Regression. Econometrica, 56(4), 931–954.
Bloom, H. S., Orr, L. L., Bell, S. H., Cave, G., Doolittle, F., Lin, W., & Bos, J. M. (1997). The Benefits and Costs of JTPA Title II-A Programs. Journal of Human Resources, 32(3), 549–576.
Oprescu, M., Syrgkanis, V., & Wu, Z. S. (2019). Orthogonal Random Forest for Causal Inference. Proceedings of the 36th International Conference on Machine Learning, 4932–4941.