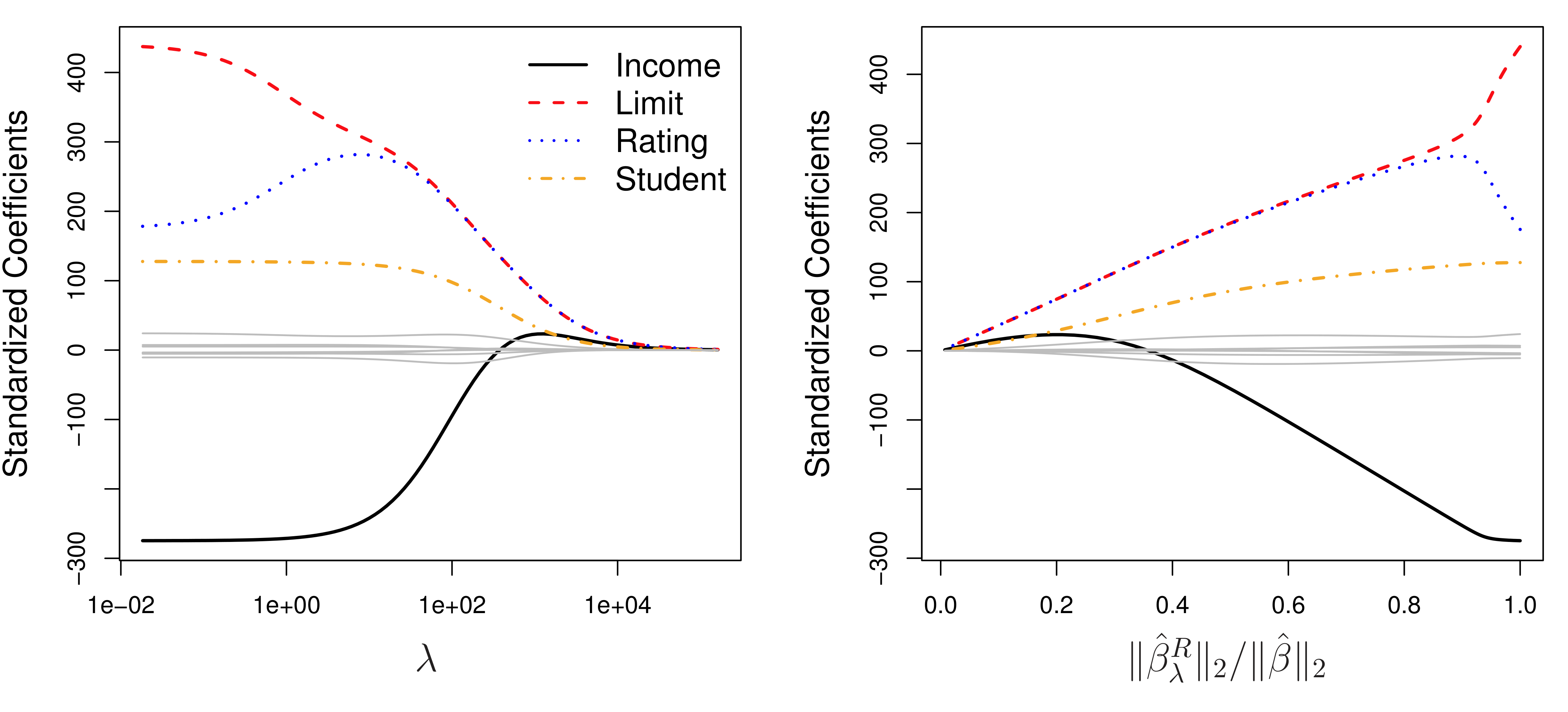
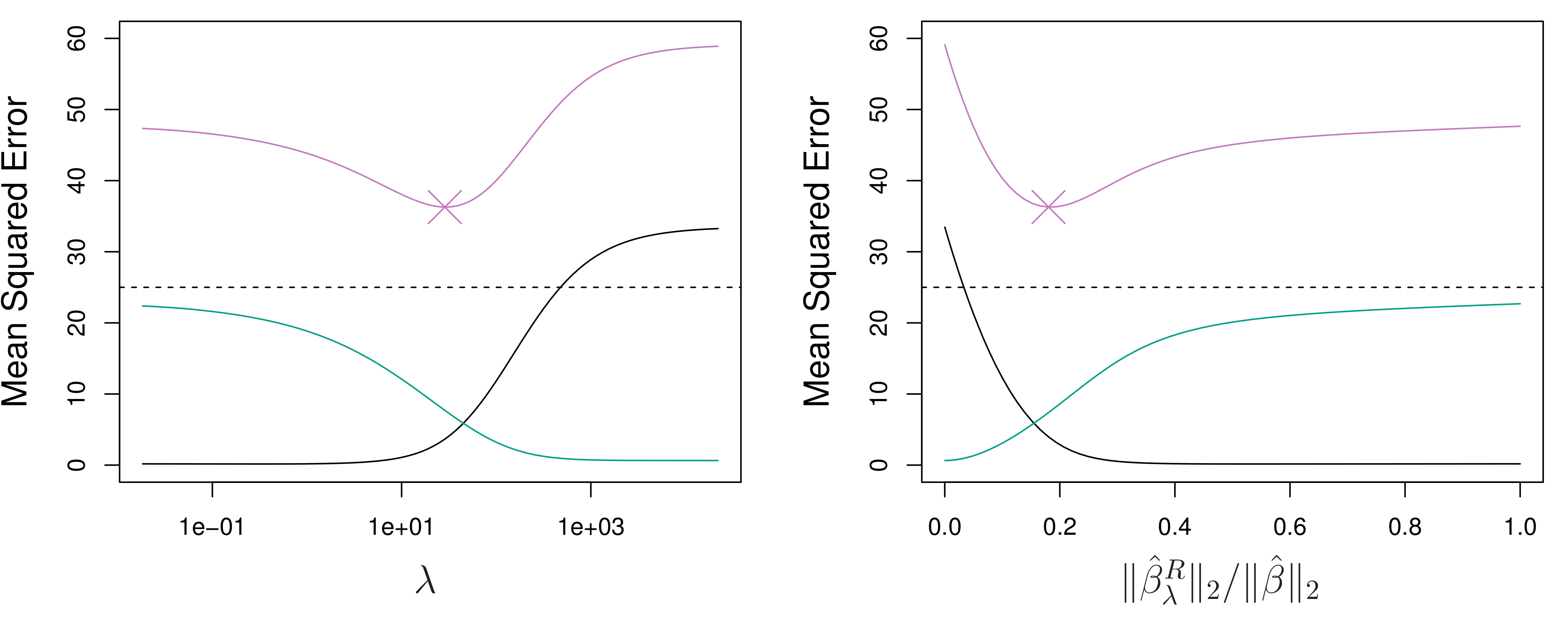
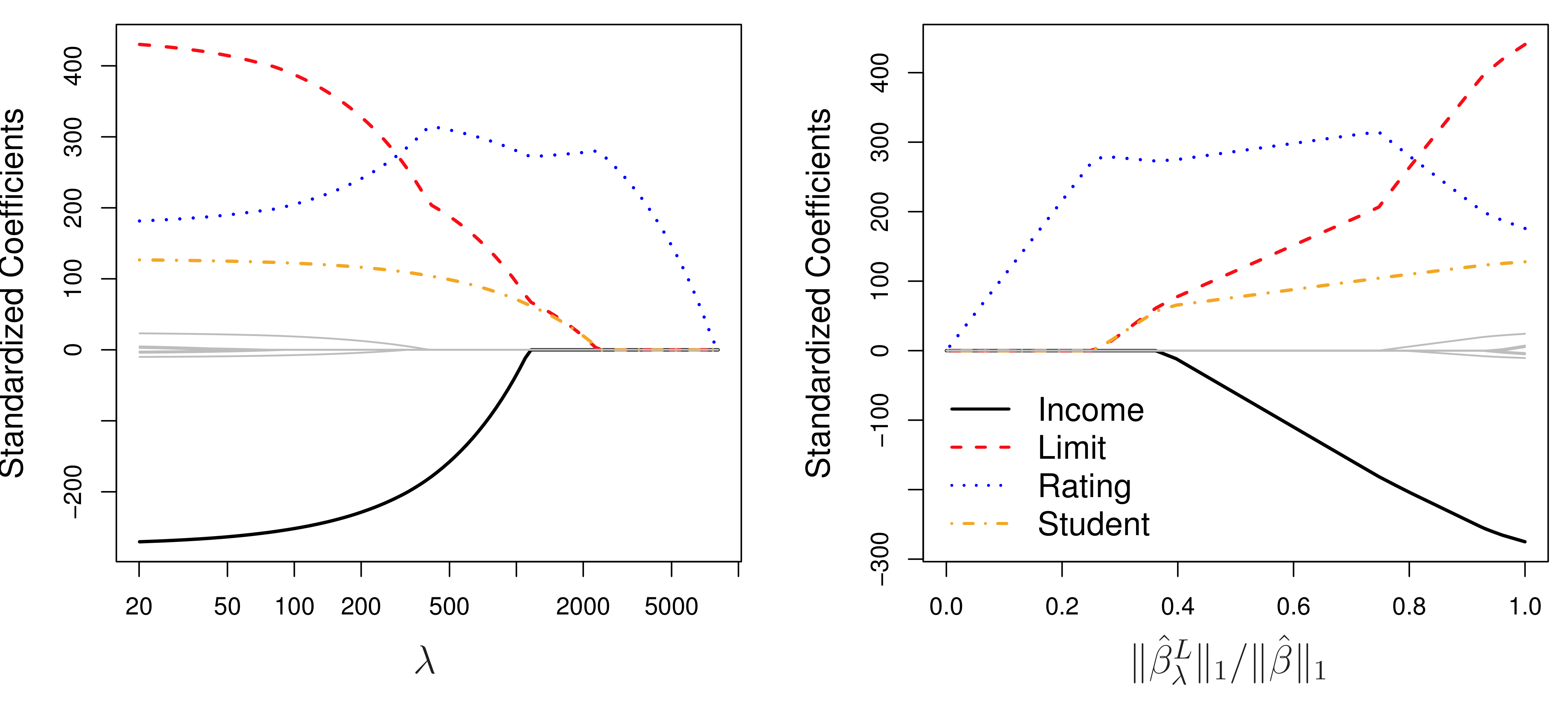
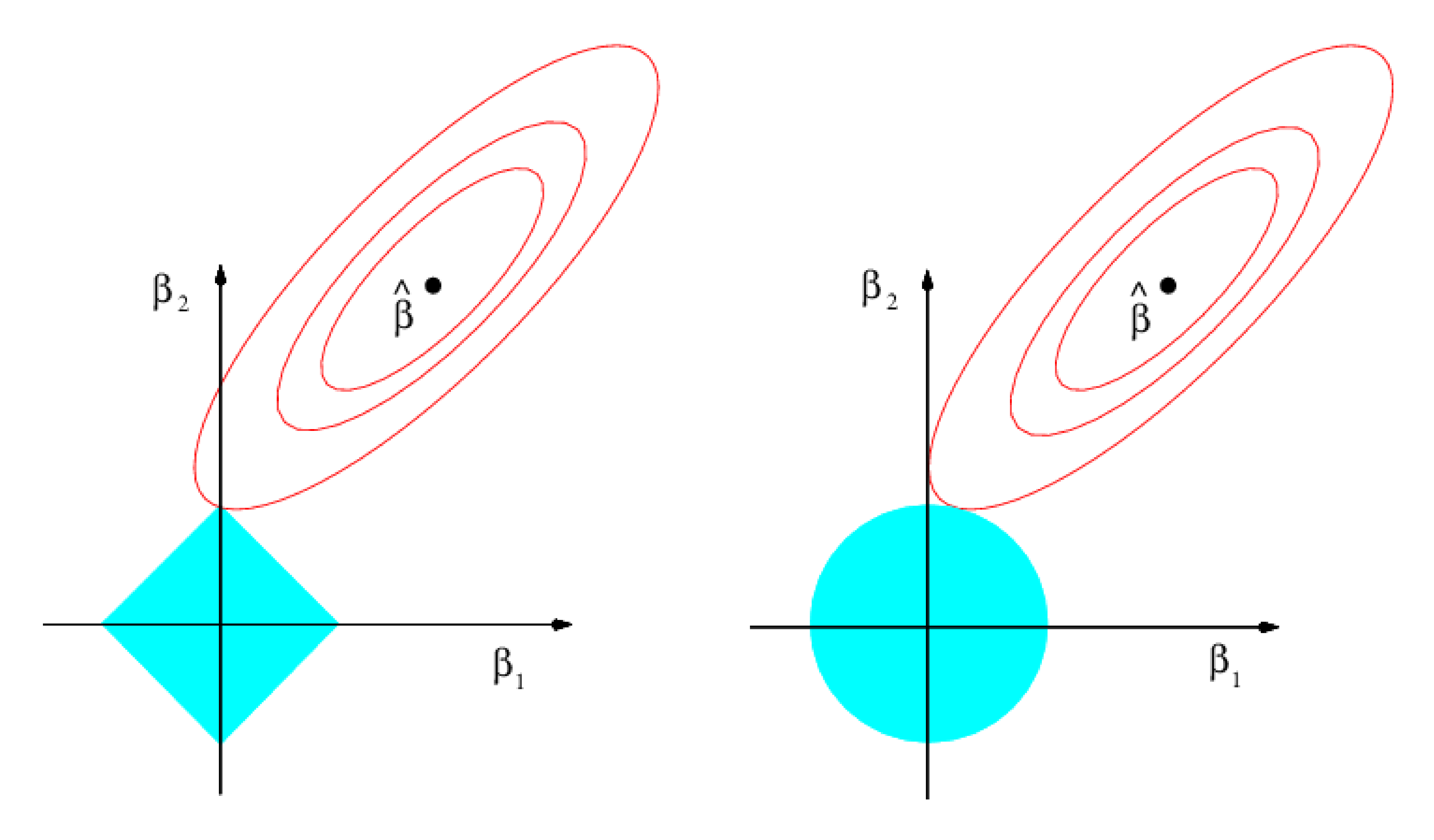
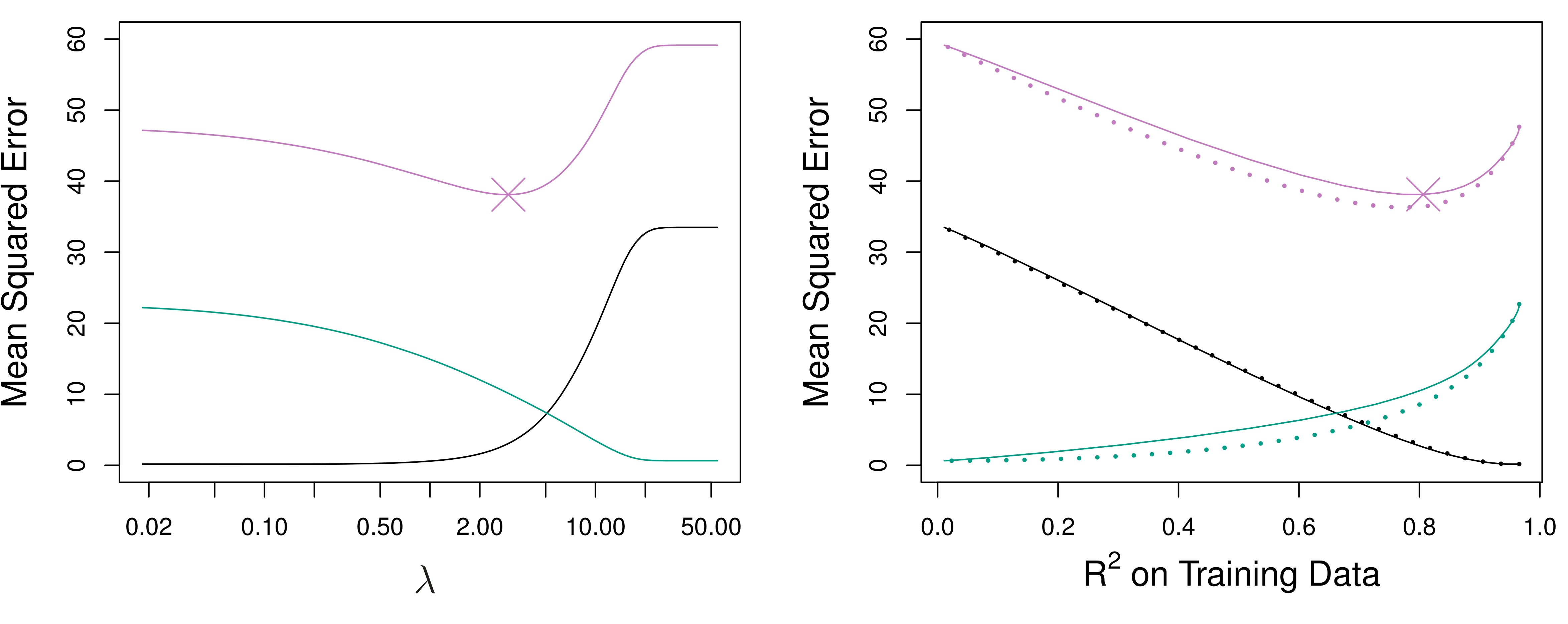
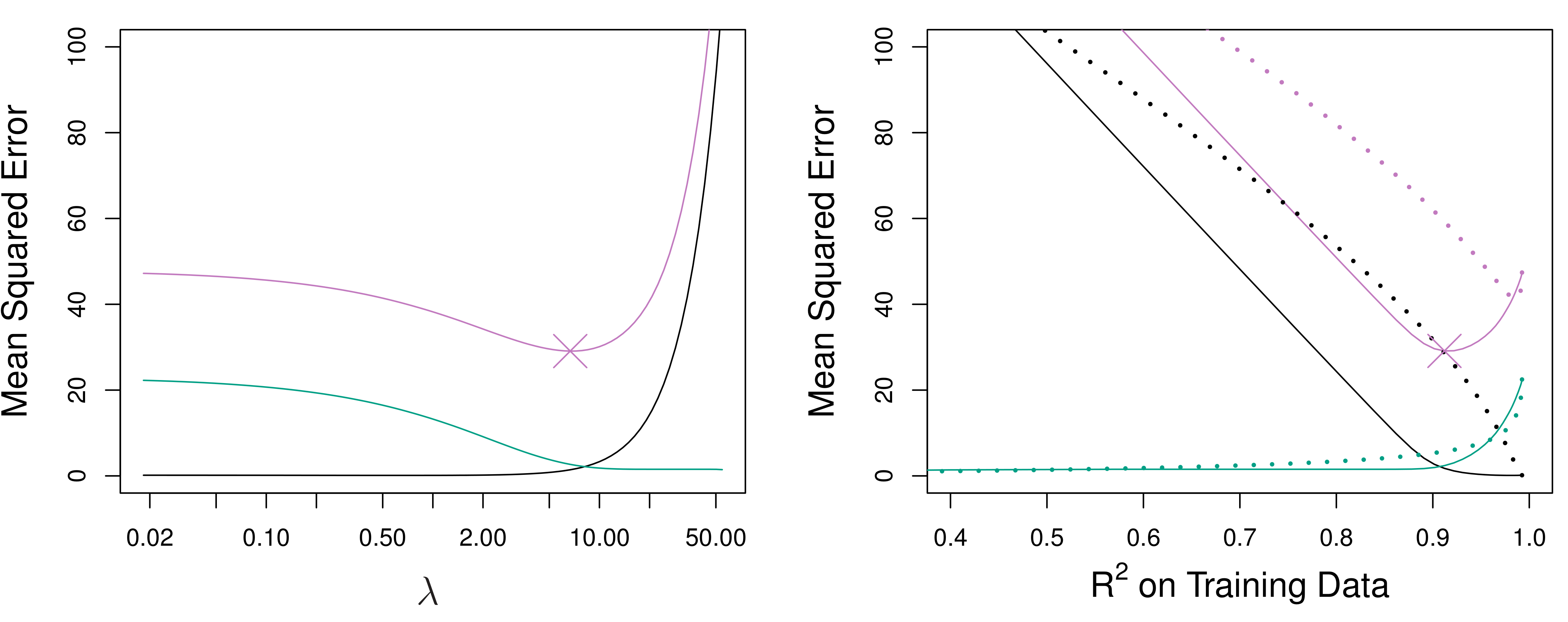
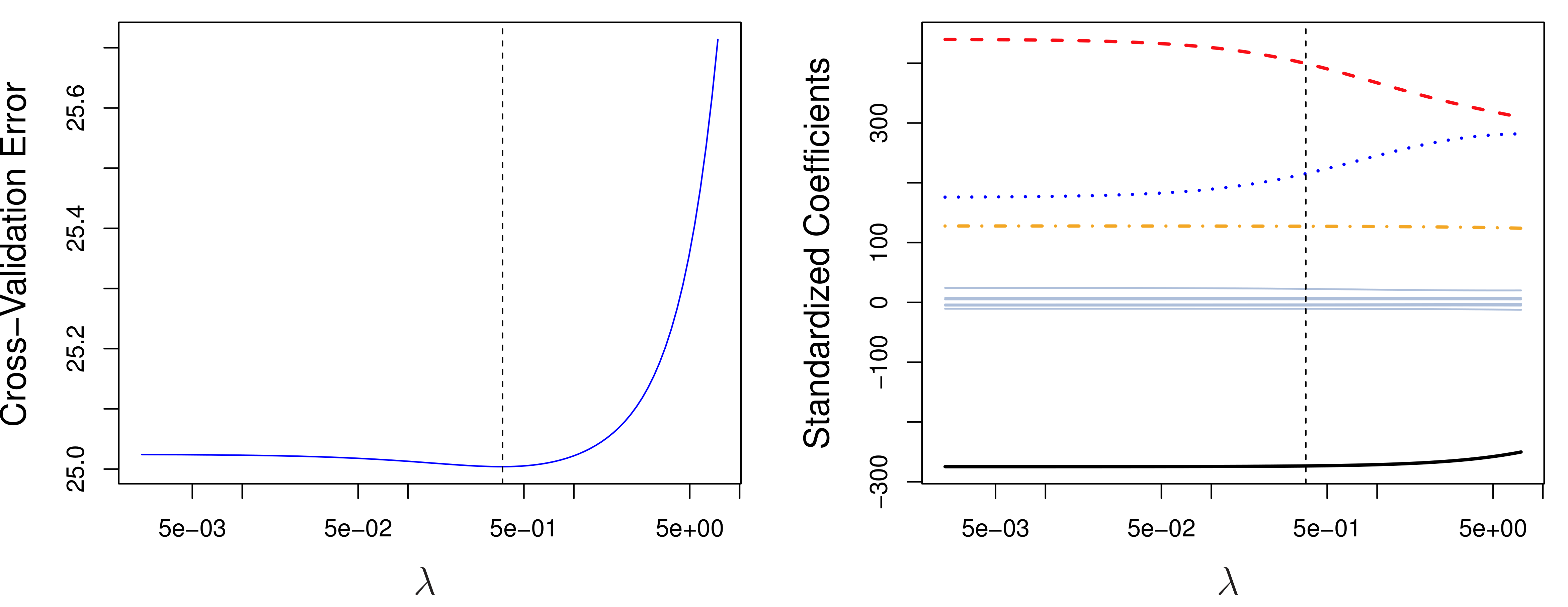
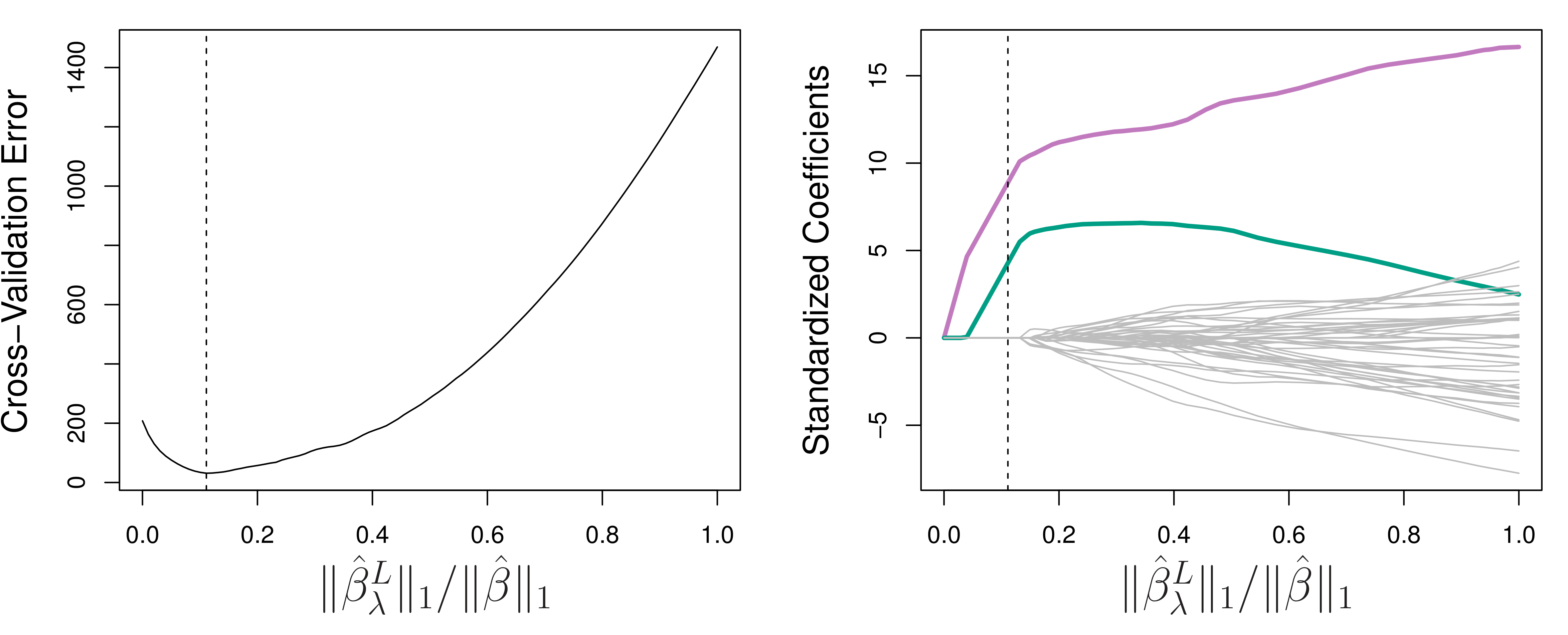
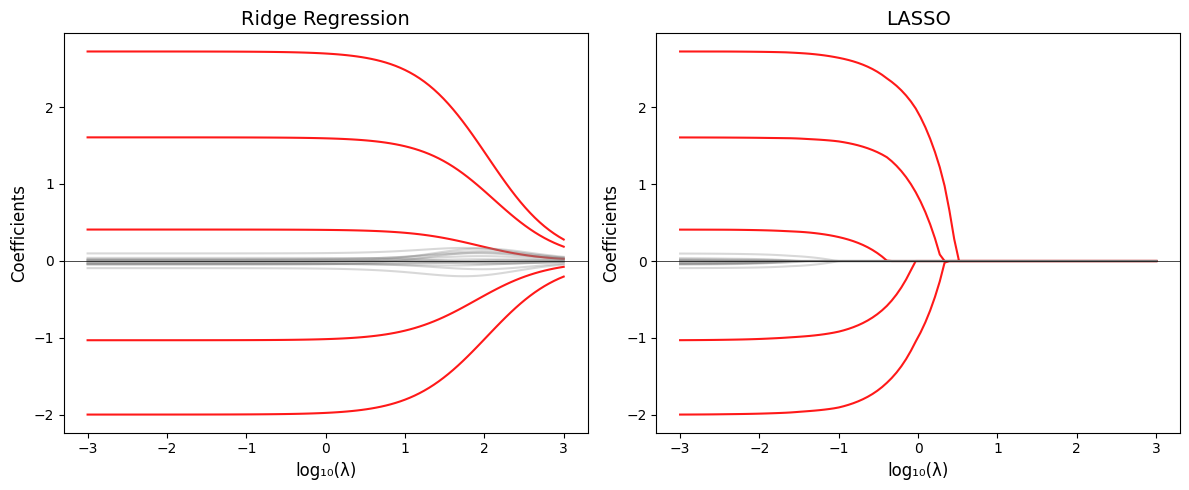
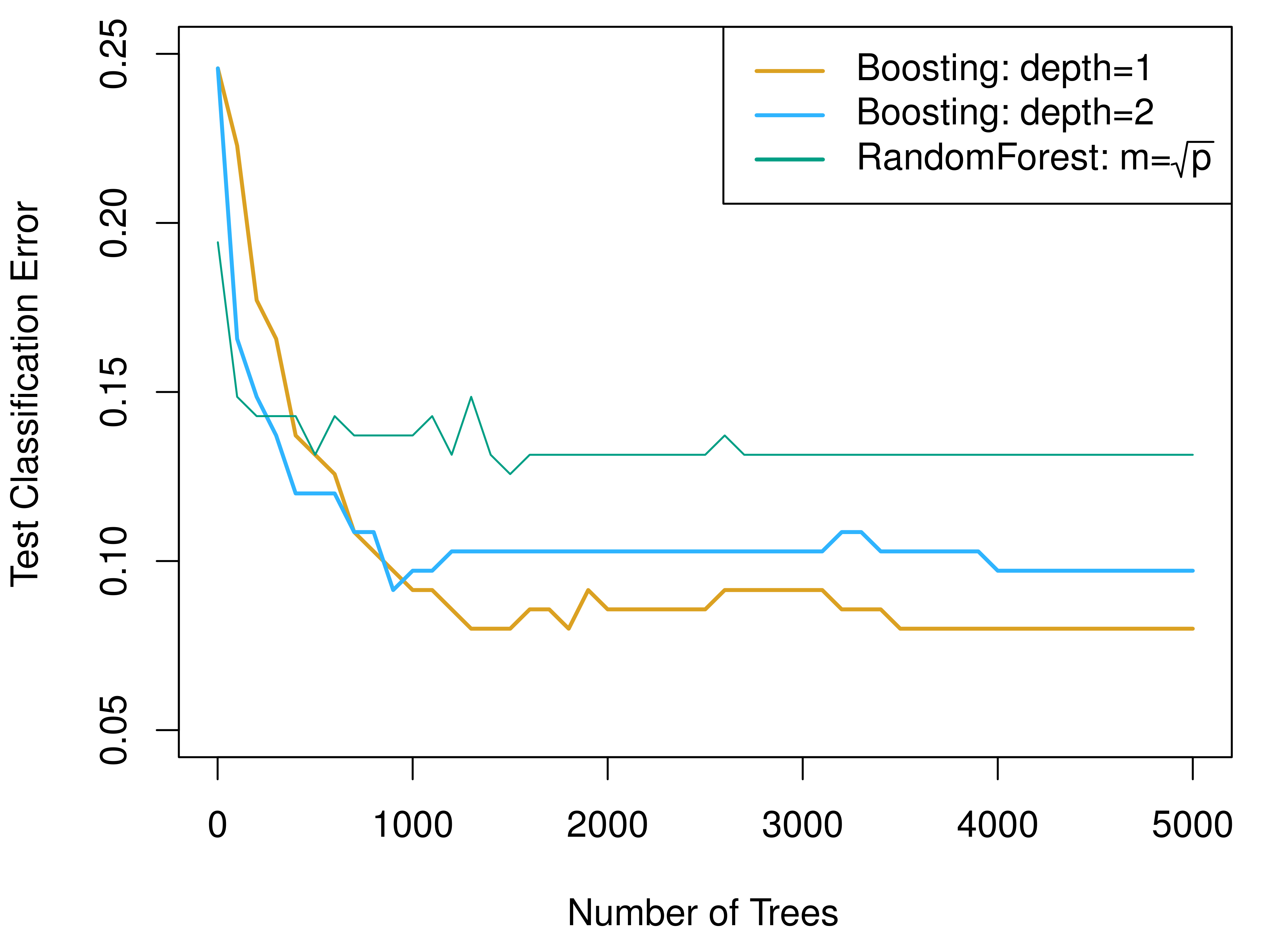
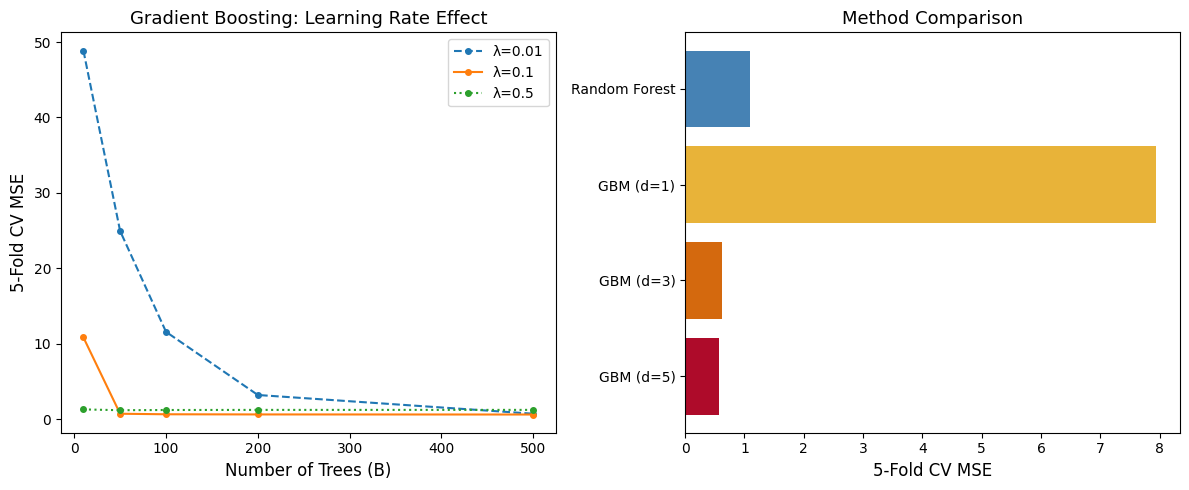
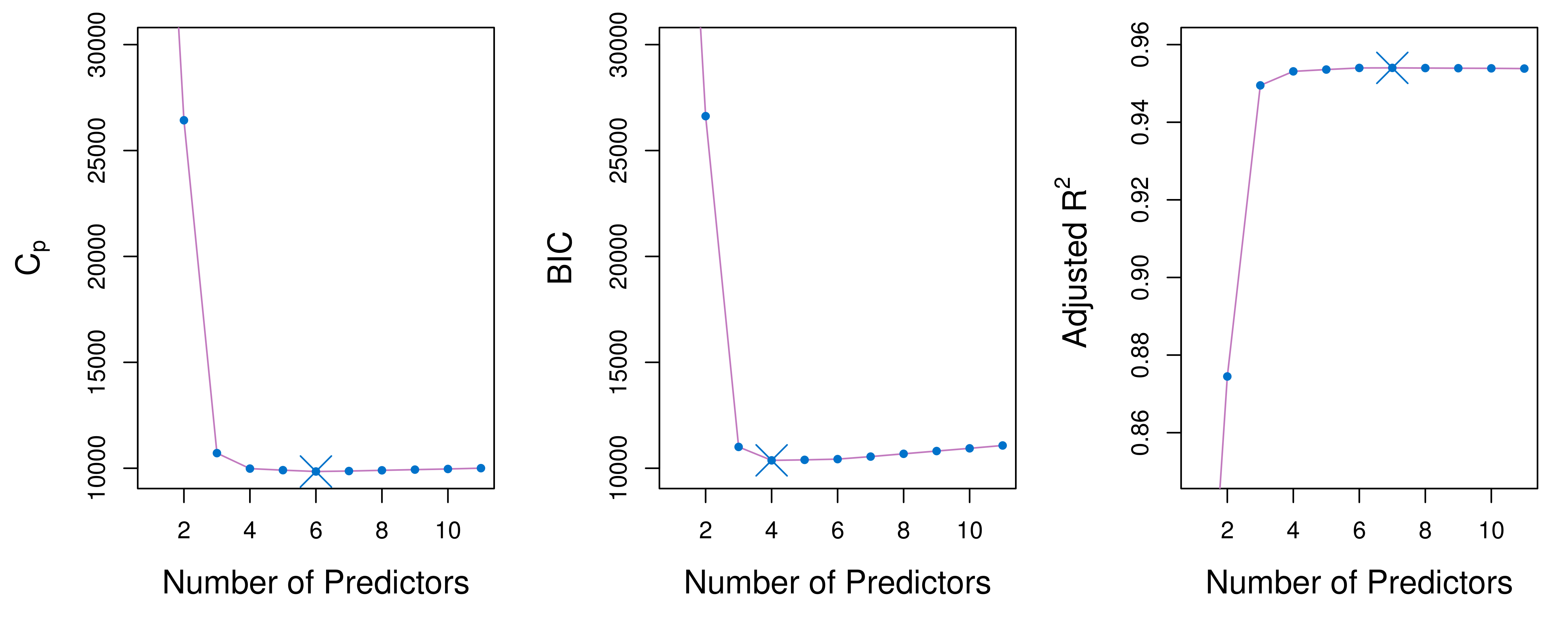
from sklearn.ensemble import GradientBoostingRegressor, RandomForestRegressor
from sklearn.model_selection import cross_val_score
import numpy as np
import matplotlib.pyplot as plt
np.random.seed(42)
n = 500
X = np.random.uniform(0, 10, (n, 5))
y = (np.sin(X[:, 0]) + 0.5 * X[:, 1] +
0.3 * X[:, 0] * X[:, 1] + np.random.normal(0, 0.5, n))
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Left: Boosting with different learning rates
n_trees_range = [10, 50, 100, 200, 500]
for lr, style in [(0.01, '--'), (0.1, '-'), (0.5, ':')]:
scores = []
for n_trees in n_trees_range:
gb = GradientBoostingRegressor(n_estimators=n_trees,
learning_rate=lr, max_depth=3,
random_state=42)
cv = -cross_val_score(gb, X, y, cv=5,
scoring='neg_mean_squared_error').mean()
scores.append(cv)
axes[0].plot(n_trees_range, scores, style, marker='o',
markersize=4, label=f'λ={lr}')
axes[0].set_xlabel('Number of Trees (B)', fontsize=12)
axes[0].set_ylabel('5-Fold CV MSE', fontsize=12)
axes[0].set_title('Gradient Boosting: Learning Rate Effect', fontsize=13)
axes[0].legend(fontsize=10)
# Right: GBM vs RF comparison
methods = {'Random Forest': RandomForestRegressor(n_estimators=200,
max_depth=5,
random_state=42),
'GBM (d=1)': GradientBoostingRegressor(n_estimators=200,
learning_rate=0.1,
max_depth=1,
random_state=42),
'GBM (d=3)': GradientBoostingRegressor(n_estimators=200,
learning_rate=0.1,
max_depth=3,
random_state=42),
'GBM (d=5)': GradientBoostingRegressor(n_estimators=200,
learning_rate=0.1,
max_depth=5,
random_state=42)}
names, mse_vals = [], []
for name, model in methods.items():
cv = -cross_val_score(model, X, y, cv=5,
scoring='neg_mean_squared_error').mean()
names.append(name)
mse_vals.append(cv)
colors = ['steelblue', '#e8b339', '#d4690e', '#AE0B2A']
axes[1].barh(names, mse_vals, color=colors)
axes[1].set_xlabel('5-Fold CV MSE', fontsize=12)
axes[1].set_title('Method Comparison', fontsize=13)
axes[1].invert_yaxis()
plt.tight_layout()
plt.show()