---
title: "机器学习与因果推断 - 第七讲:机器学习基础 I"
subtitle: "回归树、随机森林与交叉验证:完整讲义"
author: "陈志远"
institute: "中国人民大学商学院"
date: "2026-05-05"
format:
html:
theme: cosmo
css: lecture-notes.css
html-math-method: mathml
toc: true
toc-depth: 3
number-sections: true
code-fold: false
code-tools: true
highlight-style: github
self-contained: true
embed-resources: true
page-layout: article
execute:
echo: true
warning: false
message: false
eval: true
cache: false
fig-width: 10
fig-height: 6
dpi: 150
lang: zh
jupyter: python3
---
```{python}
#| echo: false
#| output: false
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib
# Set up matplotlib for Chinese display
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 150
# Set random seed for reproducibility
np.random.seed(42)
```
# 引言 {#sec-intro}
本讲标志着课程从**因果推断**进入**机器学习**的新阶段。前六讲我们系统学习了各类因果识别策略——从 DAG 因果图到匹配、工具变量、面板数据与双重差分法。这些方法的核心目标是回答“X 是否导致了 Y”这一因果问题。
从本讲开始,我们转向一个不同但互补的问题:**如何最好地预测 Y?** 机器学习提供了一套强大的预测工具,这些工具不仅在商业应用中广泛使用,而且近年来越来越多地被引入经济学和社会科学的因果推断中——这正是本课程后续“因果机器学习”部分的核心内容。
本讲对应教材 ISL (James et al., 2021) Chapters 2, 5, 8 的内容,同时参考 Athey & Imbens (2019) 和 Mullainathan & Spiess (2017) 的经济学视角。
## 上节课回顾 {#sec-review}
在上一讲中,我们学习了**面板数据与双重差分法**。面板数据通过利用个体 $\times$ 时间的二维结构,控制不随时间变化的混淆变量;双重差分法则在平行趋势假设下,通过比较处理组和对照组在政策前后的变化差异来识别因果效应。我们还学习了合成控制法——一种数据驱动构建反事实的方法,特别适用于单一处理单位的场景。
这些方法的共同特点是:研究者需要**事先指定模型形式**(如 $Y_{it} = \alpha_i + \lambda_t + \delta D_{it} + \varepsilon_{it}$),并从经济理论出发选择控制变量。机器学习则提供了一种不同的范式——让数据自己“说话”,从而发现复杂的非线性模式和交互效应。
# 第一部分:从因果推断到机器学习 {#sec-transition}
## 两种文化 {#sec-two-cultures}
统计学家 Leo Breiman 在 2001 年发表了一篇影响深远的论文《Statistical Modeling: The Two Cultures》,明确提出了统计学中存在的两种截然不同的研究范式。
### 数据建模文化(Data Modeling Culture)
传统统计学和计量经济学的主流方法属于**数据建模文化**。这种方法假设数据由一个已知形式的随机模型生成,例如线性回归模型:
$$Y = \mathbf{X}'\boldsymbol{\beta} + \varepsilon, \quad \varepsilon \sim N(0, \sigma^2)$$
研究者的任务是估计参数 $\boldsymbol{\beta}$,并对其进行统计推断。模型的好坏通过拟合优度($R^2$)、显著性检验($t$ 统计量、$F$ 检验)等来评估。
### 算法建模文化(Algorithmic Modeling Culture)
机器学习属于**算法建模文化**。这种方法将数据生成过程视为未知的“黑箱”,不假设具体的函数形式。目标是找到一个预测函数 $\hat{f}(\mathbf{x})$,使其对**新数据**的预测误差最小:
$$\hat{f} = \arg\min_{f \in \mathcal{F}} E_{(x,y) \sim P}\left[\ell(y, f(x))\right]$$
模型的好坏通过**样本外预测表现**来衡量——这就是交叉验证的核心思想。
### Breiman 论文的历史影响
Breiman 这篇论文附带了若干统计学家的评论(David Cox、Bradley Efron 等),引发了激烈的学术辩论。Efron 认为数据建模文化在理解数据生成过程方面仍有巨大价值;而 Breiman 则指出,随着数据维度的增加和问题复杂度的提升,算法建模文化的优势将愈发明显。
二十多年后的今天,两种文化的融合趋势日益明显——**因果机器学习**(Causal ML)正是这一融合的产物。它试图兼具两者的优势:既利用 ML 的灵活预测能力,又保持因果推断的严谨识别策略。
## 什么是机器学习 {#sec-what-is-ml}
机器学习的核心思想是让计算机从数据中**自动学习**一个模型 $\hat{f}(\mathbf{x})$,而不是由研究者预先指定参数模型。这里的“学习”是指通过优化某个目标函数(通常是预测误差的最小化)来确定模型的参数和结构。
### 监督学习的形式化描述
给定训练数据 $\{(x_i, y_i)\}_{i=1}^n$,监督学习的目标是找到映射 $\hat{f}: \mathcal{X} \rightarrow \mathcal{Y}$,使得对于新的输入 $x_0$,预测值 $\hat{f}(x_0)$ 尽可能接近真实值 $y_0$。
$$\hat{f} = \arg\min_{f \in \mathcal{F}} \frac{1}{n}\sum_{i=1}^{n}\ell(y_i, f(x_i)) + \lambda \cdot \Omega(f)$$
其中 $\ell$ 是损失函数(如均方误差 $(y - f(x))^2$),$\Omega(f)$ 是正则化项(控制模型复杂度),$\lambda$ 是正则化参数。
### 机器学习的分类
$$\text{机器学习} \begin{cases}
\textbf{监督学习} \begin{cases}
\text{回归(Regression):} y \text{ 是连续变量} \\
\text{分类(Classification):} y \text{ 是类别变量}
\end{cases} \\
\textbf{非监督学习:} \text{聚类分析、降维,无 } y
\end{cases}$$
本课程聚焦**监督学习中的回归问题**——这也是经济学中最常见的应用场景。
## 灵活性与可解释性的权衡 {#sec-flexibility-interpretability}
不同的统计学习方法在灵活性和可解释性之间存在一个基本的权衡关系。ISL Figure 2.7 清晰地展示了这一格局:
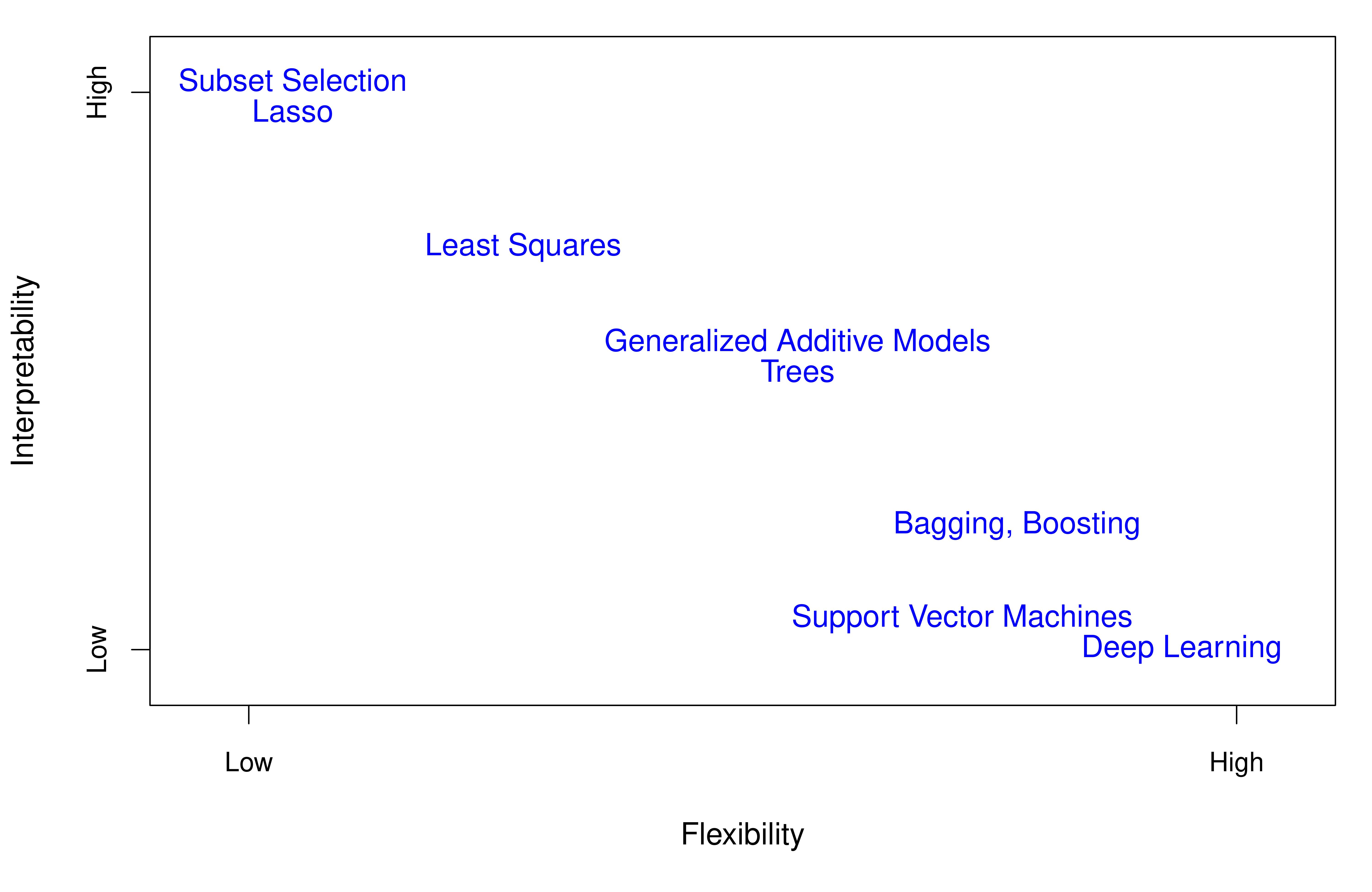{#fig-flexibility}
在图的左端,**线性回归**和 **Lasso** 是高度可解释的方法——我们可以直接从系数 $\beta_j$ 理解每个变量 $X_j$ 对 $Y$ 的边际效应。而在图的右端,**神经网络**和 **SVM** 虽然预测能力强大,但模型本身难以解释。
对于经济学家而言,可解释性往往至关重要——我们不仅要知道“什么会发生”,还要理解“为什么会发生”。这也是经济学最初对机器学习持谨慎态度的原因之一。然而,当我们的目标明确是预测(如收入预测、信用评分)时,更灵活的方法通常会带来显著的性能提升。
## 计量经济学 vs. 机器学习 {#sec-econometrics-vs-ml}
下表系统总结了两种范式的关键差异:
| 维度 | 计量经济学 | 机器学习 |
|:---|:---|:---|
| 核心目标 | 参数估计与因果推断 | 预测精度最大化 |
| 模型选择 | 经济理论驱动 | 数据驱动(交叉验证) |
| 评价标准 | 无偏性、一致性 | 测试集 MSE |
| 过拟合 | 较少关注 | 核心问题 |
| 变量选择 | 理论先验 | 自动化(LASSO、树等) |
| 样本需求 | 可处理小样本 | 通常需要大样本 |
值得注意的是,两者的融合趋势日益明显。Athey & Imbens (2019) 的综述论文《Machine Learning Methods That Economists Should Know About》系统介绍了机器学习方法如何被用于因果推断,包括异质性处理效应估计(CATE)、最优政策学习等前沿话题。这正是我们课程后半部分的核心内容。
# 第二部分:偏差-方差权衡 {#sec-bias-variance}
## 过拟合问题 {#sec-overfitting}
偏差-方差权衡是理解机器学习最重要的概念之一。它解释了为什么一个在训练数据上表现完美的模型,可能在新数据上表现很差。
### 什么是过拟合
考虑线性回归的 OLS 估计:
$$\hat{\boldsymbol{\epsilon}} = \mathbf{y} - \mathbf{X}\hat{\beta}_{OLS} = (\mathbf{I} - \mathbf{H})\boldsymbol{\epsilon}$$
其中 $\mathbf{H} = \mathbf{X}(\mathbf{X}'\mathbf{X})^{-1}\mathbf{X}'$ 是帽子矩阵(Hat Matrix)。当模型过于复杂时(如包含过多的变量或多项式项),帽子矩阵的对角元素 $h_{ii}$ 趋向于 1,这意味着 $\hat{\epsilon}_i \approx 0$——残差被人为压小了,但这并不意味着模型对新数据有好的预测能力。
::: {.callout-note}
## 直观理解
过拟合就像考试前把所有样题答案都背了下来。在这些样题上你当然能答对,但换一套新题就可能一塌糊涂。模型“记住”了噪声,而不是学到了数据中的规律。
另一个类比:想象你在记录天气规律。如果你的“规律”是“每个历史日期的温度都精确匹配”,这对预测明天的天气毫无帮助。好的规律应该是“夏天比冬天热”“气温有周期性变化”——这些是真正的模式。
:::
### 训练误差 vs. 测试误差
下图(ISL Figure 2.9)展示了一个关键发现:
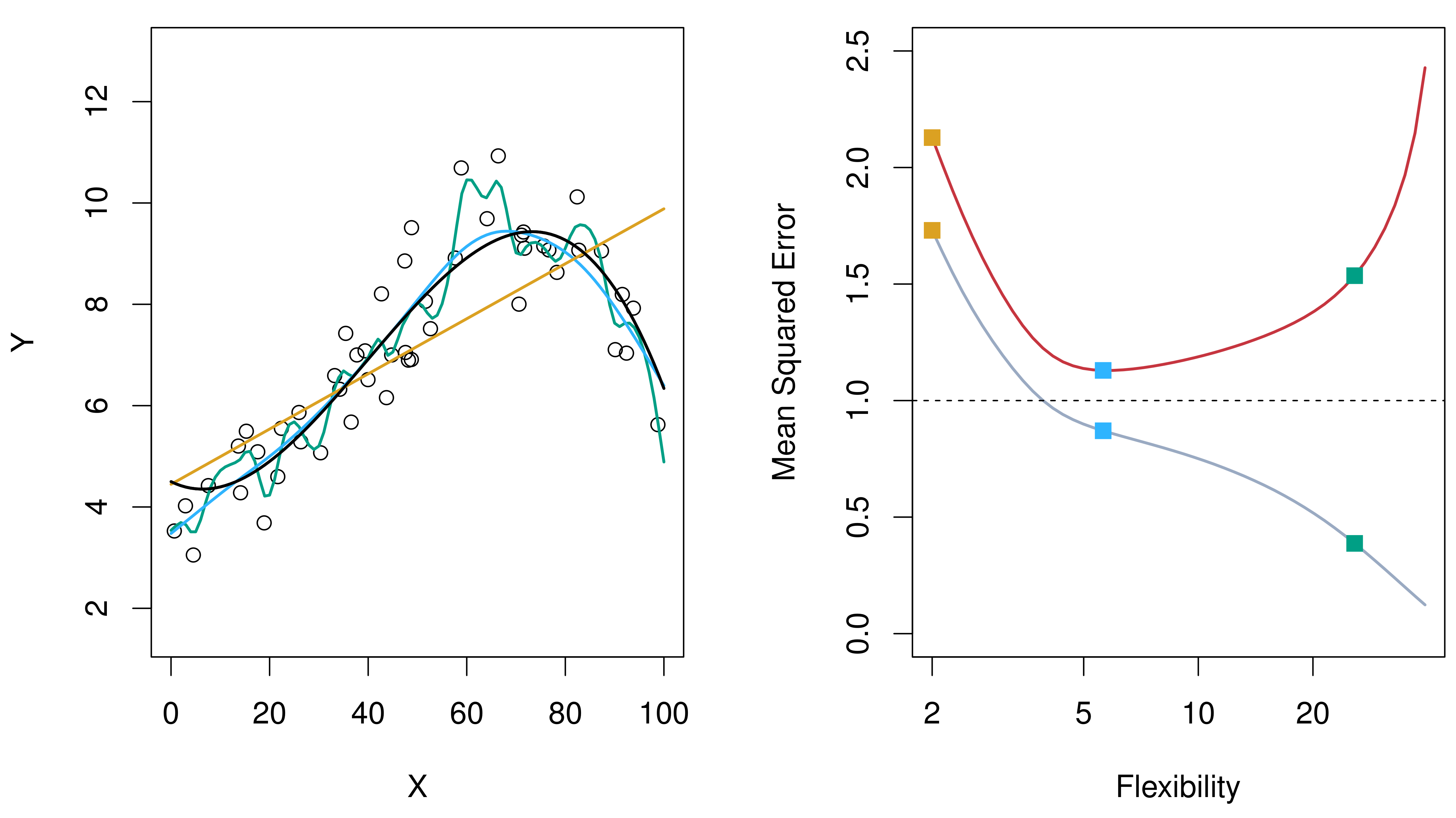{#fig-train-test}
**训练 MSE** 随模型复杂度(灵活性)增加而**单调递减**——因为更灵活的模型总能更好地拟合训练数据。但 **测试 MSE** 呈现 **U 形曲线**:在最优复杂度之前,增加灵活性有助于降低测试误差;超过最优点后,过拟合导致测试误差反而上升。
这一现象的根本原因就在于偏差-方差权衡。
## 偏差-方差分解 {#sec-bv-decomposition}
### 完整数学推导
对于任意测试点 $x_0$,假设真实模型为 $y = f(x) + \varepsilon$,其中 $E[\varepsilon] = 0$,$\text{Var}(\varepsilon) = \sigma^2$。预测误差可以精确分解为三个互不重叠的成分。
**推导过程**:
$$E\left[(y_0 - \hat{f}(x_0))^2\right]$$
对 $y_0 = f(x_0) + \varepsilon$ 进行代入:
$$= E\left[(f(x_0) + \varepsilon - \hat{f}(x_0))^2\right]$$
$$= E\left[((f(x_0) - \hat{f}(x_0)) + \varepsilon)^2\right]$$
展开平方:
$$= E\left[(f(x_0) - \hat{f}(x_0))^2\right] + 2E\left[(f(x_0) - \hat{f}(x_0))\varepsilon\right] + E[\varepsilon^2]$$
由于 $\varepsilon$ 与 $\hat{f}(x_0)$ 独立($\hat{f}$ 基于训练集估计,$\varepsilon$ 是测试点的噪声),交叉项为零:
$$= E\left[(f(x_0) - \hat{f}(x_0))^2\right] + \sigma^2$$
对第一项,加减 $E[\hat{f}(x_0)]$:
$$= E\left[(\hat{f}(x_0) - E[\hat{f}(x_0)] + E[\hat{f}(x_0)] - f(x_0))^2\right] + \sigma^2$$
$$= E\left[(\hat{f}(x_0) - E[\hat{f}(x_0)])^2\right] + (E[\hat{f}(x_0)] - f(x_0))^2 + \sigma^2$$
(交叉项为零,因为 $E[\hat{f}(x_0) - E[\hat{f}(x_0)]] = 0$)
最终得到:
$$\boxed{E\left[(y_0 - \hat{f}(x_0))^2\right] = \underbrace{\text{Var}(\hat{f}(x_0))}_{\text{方差}} + \underbrace{[\text{Bias}(\hat{f}(x_0))]^2}_{\text{偏差}^2} + \underbrace{\sigma^2}_{\text{不可约误差}}}$$
::: {.callout-tip}
## 三项的直觉含义
- **方差**(Variance):如果换一组训练数据,模型预测 $\hat{f}(x_0)$ 会变化多少?方差大意味着模型对数据“太敏感”。
- **偏差**(Bias):模型的系统性误差——即使有无穷多的训练数据,模型的平均预测是否还是偏离真实值?偏差大意味着模型“不够灵活”。
- **不可约误差**(Irreducible Error):数据本身的随机噪声,无论模型多好都无法消除。
:::
### 权衡的本质
| 模型复杂度 | 偏差 | 方差 | 总测试误差 |
|:---|:---|:---|:---|
| 低(如线性回归) | 高 | 低 | 可能高(欠拟合) |
| 高(如高次多项式) | 低 | 高 | 可能高(过拟合) |
| 适中 | 适中 | 适中 | **最低** |
下图(ISL Figure 2.12)进一步展示了这一关系:
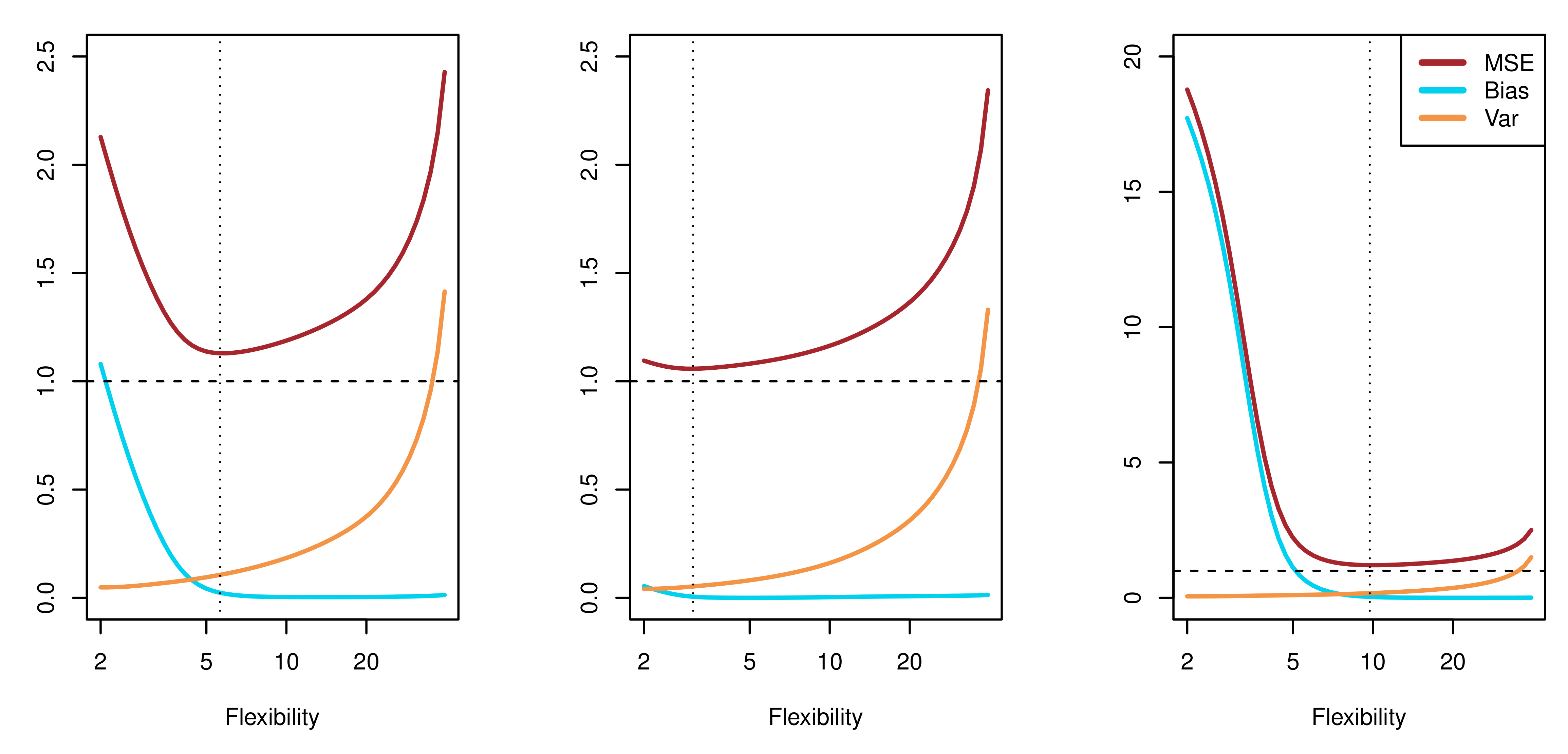{#fig-bv-tradeoff}
蓝色曲线(方差)随模型灵活性增加而上升,红色曲线(偏差²)随灵活性增加而下降。总测试误差(紫色)在某个中间点取得最小值——这就是最优模型复杂度。
### Python 模拟:多次重采样观察方差效应
下面的代码演示了偏差和方差在不同复杂度模型上的表现。我们对同一个真实函数进行多次重采样,观察不同多项式阶数的拟合结果如何随数据集变化。
```{python}
#| code-fold: show
#| code-summary: "点击查看完整代码"
#| fig-cap: "偏差-方差权衡:不同多项式阶数在多次重采样下的表现"
#| fig-width: 12
#| fig-height: 8
np.random.seed(42)
def f_true(x):
"""真实函数"""
return np.sin(2 * x) + 0.5 * x
x_test = np.linspace(0, 5, 200)
y_true = f_true(x_test)
# 模拟参数
n_samples = 30
n_repeats = 50
degrees = [1, 4, 15]
fig, axes = plt.subplots(2, 3, figsize=(12, 8))
for col, deg in enumerate(degrees):
predictions = np.zeros((n_repeats, len(x_test)))
for rep in range(n_repeats):
x_train = np.sort(np.random.uniform(0, 5, n_samples))
y_train = f_true(x_train) + np.random.normal(0, 0.5, n_samples)
coeffs = np.polyfit(x_train, y_train, deg)
predictions[rep] = np.polyval(coeffs, x_test)
# 上排:所有拟合叠加
ax = axes[0, col]
for rep in range(n_repeats):
ax.plot(x_test, predictions[rep], 'b-', alpha=0.1, linewidth=0.5)
ax.plot(x_test, y_true, 'k-', linewidth=2, label='真实函数')
ax.plot(x_test, predictions.mean(axis=0), 'r--', linewidth=2, label='平均预测')
ax.set_title(f'多项式阶数 = {deg}', fontsize=13)
ax.set_ylim(-3, 8)
ax.legend(fontsize=9)
# 下排:偏差和方差的空间分布
ax2 = axes[1, col]
bias = predictions.mean(axis=0) - y_true
variance = predictions.var(axis=0)
ax2.plot(x_test, bias**2, 'r-', linewidth=2, label='偏差²')
ax2.plot(x_test, variance, 'b-', linewidth=2, label='方差')
ax2.plot(x_test, bias**2 + variance, 'purple', linewidth=2, linestyle='--', label='偏差² + 方差')
ax2.set_title(f'度={deg}: 偏差²={np.mean(bias**2):.3f}, 方差={np.mean(variance):.3f}', fontsize=11)
ax2.legend(fontsize=9)
ax2.set_ylim(0, 3)
axes[0, 0].set_ylabel('预测值', fontsize=12)
axes[1, 0].set_ylabel('误差分解', fontsize=12)
plt.tight_layout()
plt.show()
```
这个模拟清楚地展示了:
- **度=1(线性)**:每次拟合结果都很“稳定”(低方差),但系统性地偏离真实函数(高偏差)
- **度=4**:拟合结果对真实函数很好地近似(低偏差),且不同数据集的拟合变化适中(适度方差)
- **度=15**:虽然平均来看接近真实函数,但每次拟合结果剧烈波动(极高方差),尤其在数据稀疏的区域
# 第三部分:交叉验证 {#sec-cross-validation}
## 为什么需要交叉验证 {#sec-why-cv}
偏差-方差权衡告诉我们:最优模型是在偏差和方差之间取平衡的模型。但在实践中,我们**无法直接观测真正的测试误差**——因为我们没有无穷多的新数据来评估预测表现。
交叉验证提供了一种巧妙的解决方案:**在现有数据中模拟“训练-测试”的过程**,从而估计模型在新数据上的表现。
### 与信息准则的比较
在传统计量经济学中,常用的模型选择工具是信息准则:
$$\text{AIC} = -2\ln \hat{L} + 2k, \quad \text{BIC} = -2\ln \hat{L} + k\ln n$$
其中 $k$ 是参数个数。信息准则通过惩罚模型复杂度来近似测试误差。
交叉验证与信息准则相比有以下优势:
| 特征 | 信息准则(AIC/BIC) | 交叉验证 |
|:---|:---|:---|
| 适用范围 | 需要似然函数的参数模型 | 任何预测方法 |
| 假设 | 依赖特定的渐近近似 | 不需要模型假设 |
| 灵活性 | 限于参数模型 | 可用于非参数方法(如树、随机森林) |
| 计算成本 | 低 | 相对较高 |
::: {.callout-note}
## 交叉验证是“免费午餐”吗
严格来说不是——交叉验证增加了计算成本,并且在小样本中可能有较大的估计方差。但它的适用范围远比信息准则广泛,尤其对于现代机器学习方法(树、森林、神经网络等),交叉验证几乎是唯一可行的模型选择工具。
:::
## 验证集方法 {#sec-validation-set}
最简单的估计测试误差的方法是**验证集方法**(Validation Set Approach):
1. 将数据随机分为两部分——训练集和验证集
2. 在训练集上拟合模型
3. 在验证集上计算预测误差
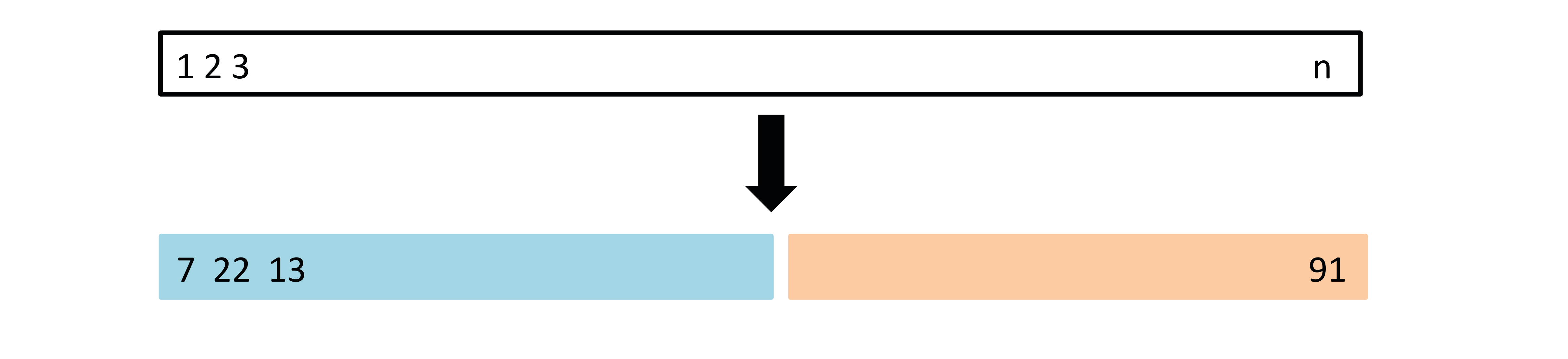{#fig-validation-set}
然而,这种方法有一个严重的稳定性问题。下图展示了对同一数据集进行多次随机划分后,验证 MSE 曲线的变化情况:
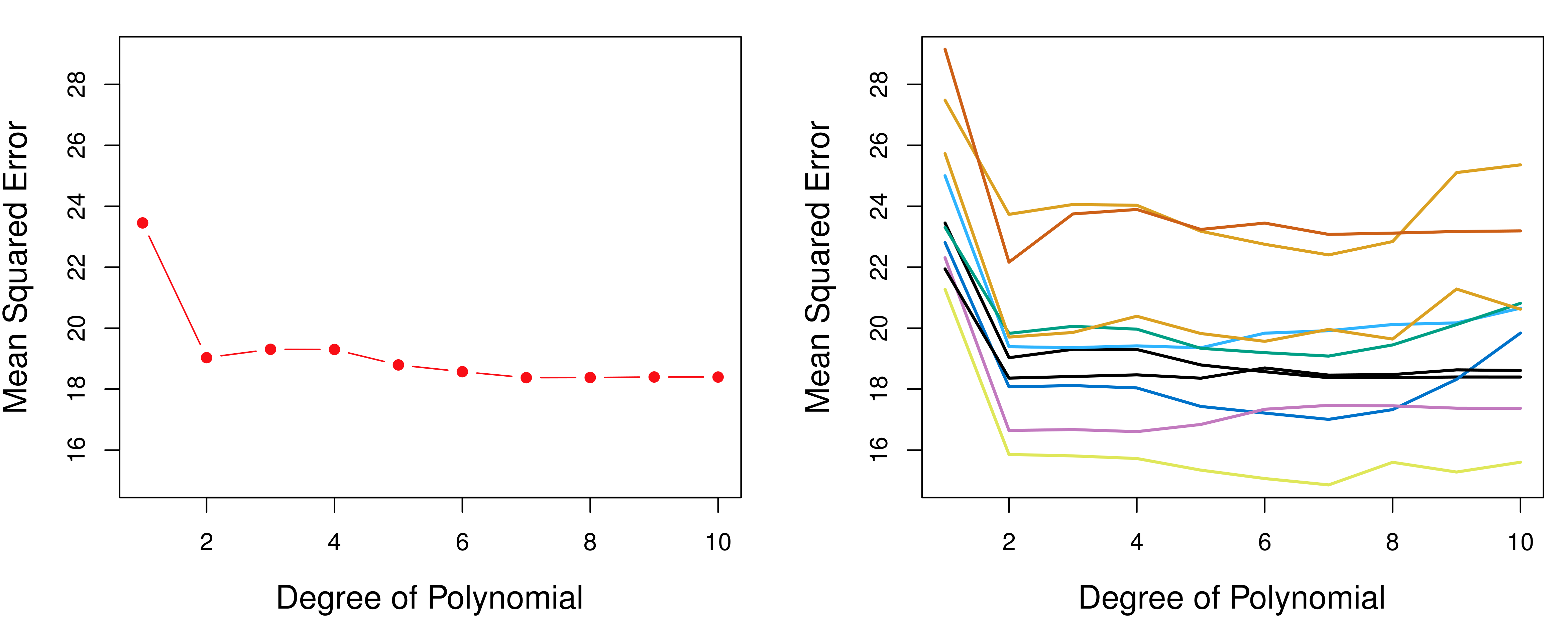{#fig-validation-instability}
每次随机划分给出了截然不同的验证 MSE 曲线——我们甚至可能得到不同的“最优”模型。这显然不是一个可靠的选择方法。
## K 折交叉验证 {#sec-kfold-cv}
K 折交叉验证通过**多次训练-验证循环**来解决上述稳定性问题。
### 算法描述
1. 将 $n$ 个观测随机分为 $K$ 个大小大致相等的折(fold)$C_1, C_2, \ldots, C_K$,每折约 $n/K$ 个样本
2. 对 $k = 1, 2, \ldots, K$:
- 将第 $k$ 折 $C_k$ 作为**验证集**
- 将其余 $K - 1$ 折的并集 $C_{-k}$ 作为**训练集**
- 在训练集上拟合模型,在验证集上计算 MSE$_k$
3. 最终的 CV 估计为所有折的平均:
$$CV_{(K)} = \frac{1}{K}\sum_{k=1}^{K} MSE_k = \frac{1}{K}\sum_{k=1}^{K}\frac{1}{n_k}\sum_{i \in C_k}(y_i - \hat{y}_i^{(-k)})^2$$
其中 $\hat{y}_i^{(-k)}$ 表示在删除第 $k$ 折后训练的模型对 $y_i$ 的预测。
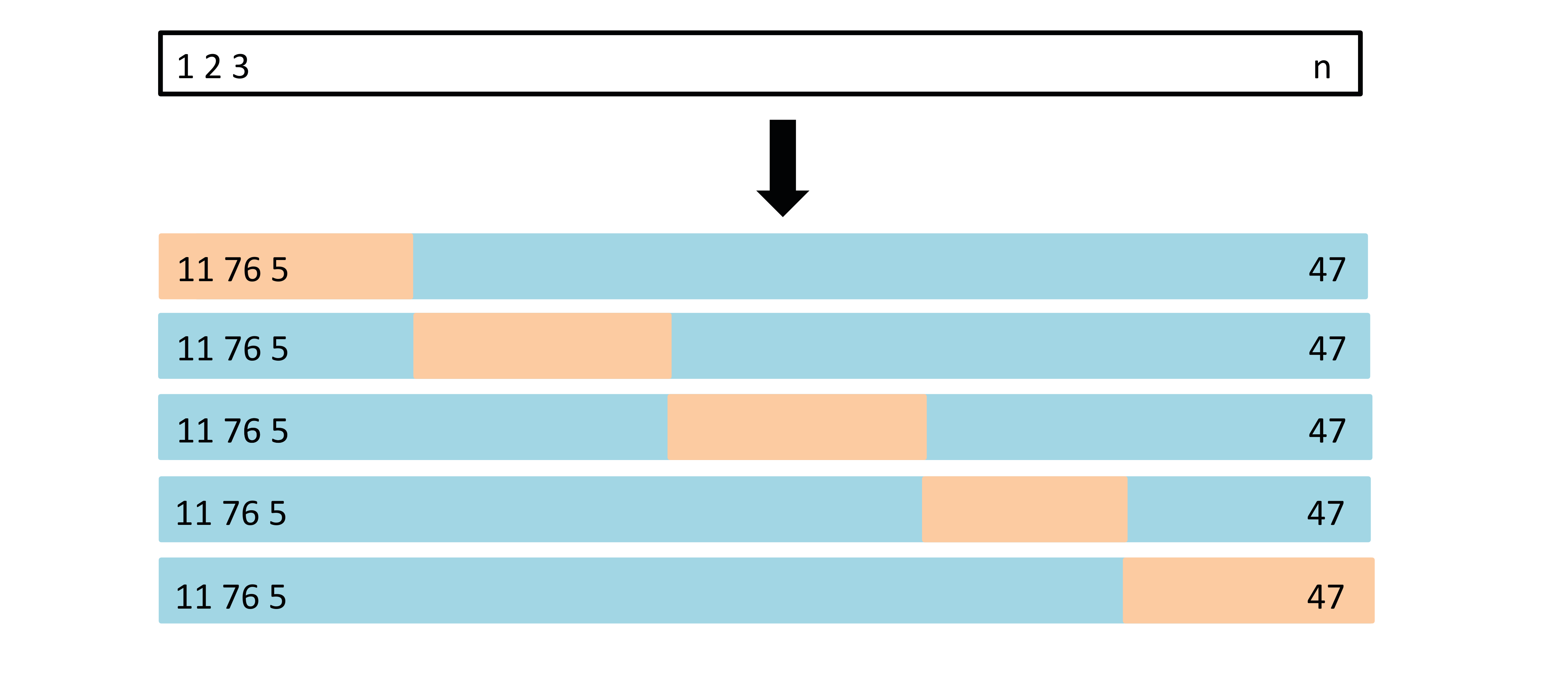{#fig-kfold}
### K 的选择
$K$ 的选择本身也涉及偏差-方差权衡:
| K 值 | 偏差 | 方差 | 计算量 | 推荐场景 |
|:---|:---|:---|:---|:---|
| $K = 5$ | 略高 | 较低 | 适中 | 大多数实践场景 |
| $K = 10$ | 较低 | 适中 | 适中 | 默认推荐 |
| $K = n$(LOOCV) | 最低 | 最高 | 最大 | 小样本 |
**为什么 LOOCV 方差最高?** 当 $K = n$ 时,每次训练集几乎完全相同(只差一个观测),导致 $K$ 个拟合结果高度相关。而 $K$ 个高度相关的估计量取平均,方差缩减效果很差。
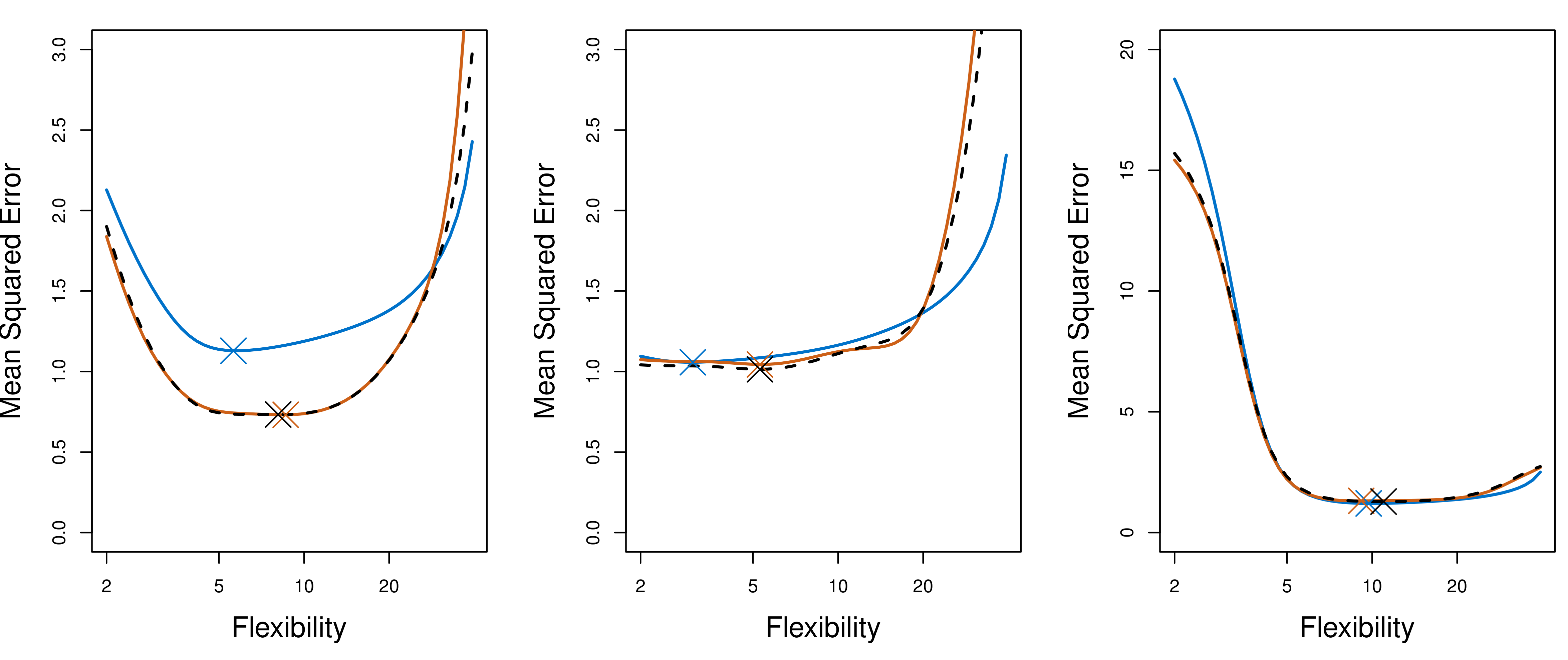{#fig-k-comparison}
### Python 实现:比较不同 K 值
```{python}
#| code-fold: show
#| code-summary: "点击查看完整代码"
#| fig-cap: "不同 K 值的交叉验证比较"
#| fig-width: 12
#| fig-height: 5
from sklearn.model_selection import cross_val_score, KFold, LeaveOneOut
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
np.random.seed(42)
n = 100
X = np.sort(np.random.uniform(0, 5, n)).reshape(-1, 1)
y = np.sin(2 * X.ravel()) + 0.5 * X.ravel() + np.random.normal(0, 0.5, n)
degrees = range(1, 13)
k_values = [5, 10]
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# 左图:不同 K 值的 CV 曲线
ax = axes[0]
for k in k_values:
cv_means = []
for d in degrees:
model = make_pipeline(PolynomialFeatures(d), LinearRegression())
scores = cross_val_score(model, X, y, cv=k, scoring='neg_mean_squared_error')
cv_means.append(-scores.mean())
ax.plot(degrees, cv_means, '-o', label=f'{k}-Fold CV', markersize=5)
# LOOCV
cv_loocv = []
for d in degrees:
model = make_pipeline(PolynomialFeatures(d), LinearRegression())
scores = cross_val_score(model, X, y, cv=LeaveOneOut(), scoring='neg_mean_squared_error')
cv_loocv.append(-scores.mean())
ax.plot(degrees, cv_loocv, '--o', label='LOOCV', markersize=5, alpha=0.7)
ax.set_xlabel('多项式阶数', fontsize=12)
ax.set_ylabel('CV MSE', fontsize=12)
ax.set_title('不同 K 值的交叉验证曲线', fontsize=13)
ax.legend(fontsize=11)
ax.set_ylim(0, max(cv_loocv) * 1.3)
# 右图:CV 估计的稳定性
ax2 = axes[1]
n_repeats = 20
for rep in range(n_repeats):
cv_5fold = []
kf = KFold(n_splits=5, shuffle=True, random_state=rep)
for d in degrees:
model = make_pipeline(PolynomialFeatures(d), LinearRegression())
scores = cross_val_score(model, X, y, cv=kf, scoring='neg_mean_squared_error')
cv_5fold.append(-scores.mean())
ax2.plot(degrees, cv_5fold, 'b-', alpha=0.15, linewidth=1)
# 叠加 10-fold 的稳定性
for rep in range(n_repeats):
cv_10fold = []
kf = KFold(n_splits=10, shuffle=True, random_state=rep + 100)
for d in degrees:
model = make_pipeline(PolynomialFeatures(d), LinearRegression())
scores = cross_val_score(model, X, y, cv=kf, scoring='neg_mean_squared_error')
cv_10fold.append(-scores.mean())
ax2.plot(degrees, cv_10fold, 'r-', alpha=0.15, linewidth=1)
ax2.plot([], [], 'b-', linewidth=2, label='5-Fold(20次随机划分)')
ax2.plot([], [], 'r-', linewidth=2, label='10-Fold(20次随机划分)')
ax2.set_xlabel('多项式阶数', fontsize=12)
ax2.set_ylabel('CV MSE', fontsize=12)
ax2.set_title('CV 估计的稳定性:5-Fold vs. 10-Fold', fontsize=13)
ax2.legend(fontsize=11)
ax2.set_ylim(0, 2)
plt.tight_layout()
plt.show()
```
### K-Fold CV 可视化:数据是如何分折的
```{python}
#| code-fold: show
#| code-summary: "点击查看 K-Fold CV 示意图代码"
#| fig-cap: "5-Fold 交叉验证的数据划分示意图"
#| fig-width: 10
#| fig-height: 4
fig, ax = plt.subplots(figsize=(10, 3.5))
K = 5
colors = plt.cm.Set3(np.linspace(0, 1, K))
for k in range(K):
for j in range(K):
if j == k:
rect = plt.Rectangle((j * 2, K - 1 - k), 1.8, 0.8,
facecolor='#AE0B2A', alpha=0.8)
ax.text(j * 2 + 0.9, K - 1 - k + 0.4, '验证',
ha='center', va='center', fontsize=11, color='white', fontweight='bold')
else:
rect = plt.Rectangle((j * 2, K - 1 - k), 1.8, 0.8,
facecolor='steelblue', alpha=0.6)
ax.text(j * 2 + 0.9, K - 1 - k + 0.4, '训练',
ha='center', va='center', fontsize=10, color='white')
ax.add_patch(rect)
ax.text(K * 2 + 0.5, K - 1 - k + 0.4, f'→ MSE$_{k+1}$',
ha='left', va='center', fontsize=11)
for j in range(K):
ax.text(j * 2 + 0.9, K + 0.2, f'折 {j+1}', ha='center', fontsize=11, fontweight='bold')
ax.text(K * 2 + 0.5, -0.7, f'CV = (1/{K}) Σ MSE$_k$',
ha='left', va='center', fontsize=12, fontweight='bold')
ax.set_xlim(-0.3, K * 2 + 3)
ax.set_ylim(-1.2, K + 0.6)
ax.set_aspect('equal')
ax.axis('off')
ax.set_title(f'{K}-Fold 交叉验证流程', fontsize=14, pad=10)
plt.tight_layout()
plt.show()
```
### R 语言对照
```{r}
#| eval: false
#| echo: true
library(caret)
# 使用 caret 进行 K-Fold CV
set.seed(42)
train_control <- trainControl(method = "cv", number = 10)
# 线性回归
lm_model <- train(y ~ poly(x, degree = 4), data = df,
method = "lm", trControl = train_control)
print(lm_model)
# 比较不同多项式阶数
results <- data.frame(degree = 1:12, RMSE = NA, Rsquared = NA)
for (d in 1:12) {
model <- train(y ~ poly(x, degree = d), data = df,
method = "lm", trControl = train_control)
results$RMSE[d] <- model$results$RMSE
results$Rsquared[d] <- model$results$Rsquared
}
plot(results$degree, results$RMSE, type = "b",
xlab = "Polynomial Degree", ylab = "CV RMSE")
```
# 第四部分:回归树 {#sec-regression-tree}
## 从线性模型到树模型 {#sec-tree-intro}
回归树是一种本质上不同于线性模型的预测方法。线性回归假设 $Y$ 和 $\mathbf{X}$ 之间存在线性关系:$Y = \mathbf{X}'\boldsymbol{\beta} + \varepsilon$。当真实关系是非线性的、存在交互效应或阈值效应时,线性模型可能严重偏离。
回归树的核心思想是:通过**递归地将特征空间划分为矩形区域**,在每个区域内用均值进行预测。这种方法不假设任何参数形式——完全由数据决定分裂位置和方向。
### 直观示例
ISL Figure 8.1 展示了一棵预测棒球运动员薪资的回归树:
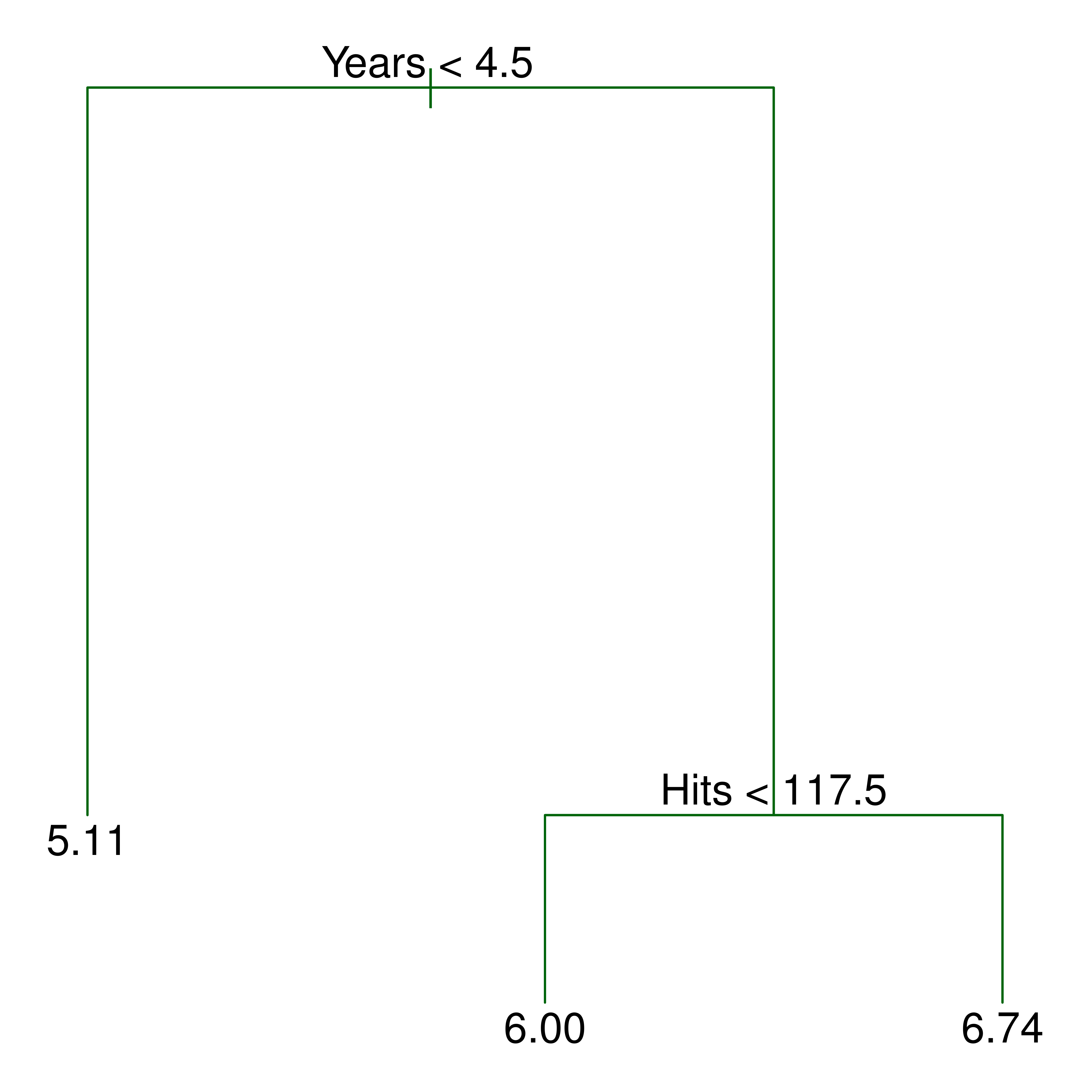{#fig-tree-example}
每个**内部节点**是一个分裂条件(如“工龄 < 4.5 年”),每个**叶节点**给出预测值($\log$ 薪资的均值)。沿着树从根节点到叶节点,就是一个分类决策过程。
### 特征空间的划分
回归树将特征空间划分为**互不重叠的矩形区域**:
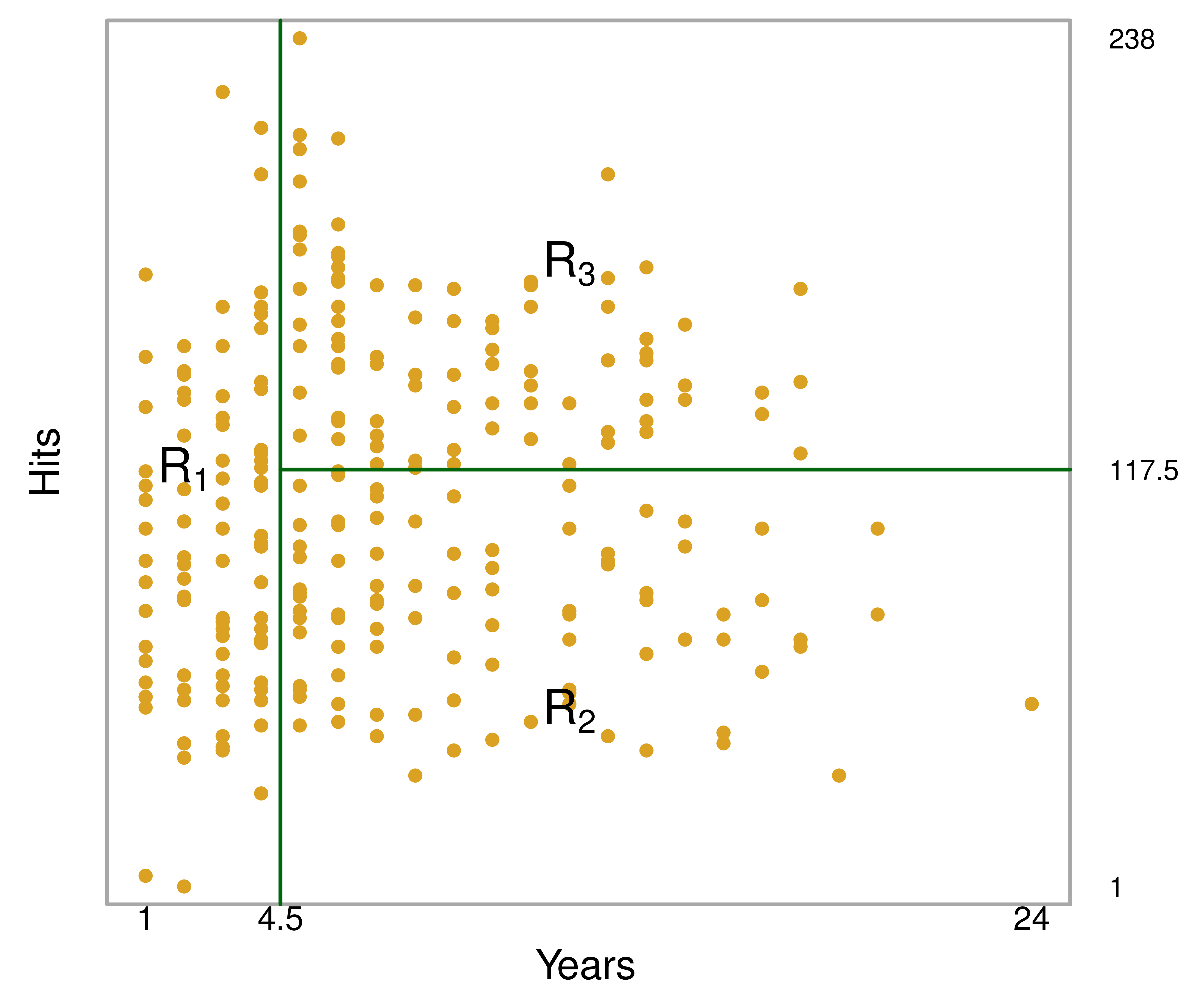{#fig-tree-partition}
每个区域 $R_j$ 对应一个叶节点。落入同一区域的所有观测值共享相同的预测值:
$$\hat{y}_i = \bar{y}_{R_j}, \quad \text{若 } x_i \in R_j$$
::: {.callout-note}
## 树模型的决策边界
树模型的决策边界总是**与坐标轴平行**的矩形。这是因为每次分裂只涉及一个变量和一个阈值($X_k \leq c$ 或 $X_k > c$),永远不会产生对角线方向的分界。这一特性使得树模型在面对斜向决策边界时可能需要很多分裂才能近似。
:::
## 回归树算法:递归二元分裂 {#sec-tree-algorithm}
### 形式化描述
回归树的构建目标是找到区域 $\{R_1, R_2, \ldots, R_J\}$,使得总残差平方和最小:
$$\min_{R_1, \ldots, R_J} \sum_{j=1}^{J} \sum_{i \in R_j} (y_i - \hat{y}_{R_j})^2$$
这是一个 NP-hard 的组合优化问题——枚举所有可能的划分是不现实的。因此我们采用**贪心算法**:在每一步选择使 RSS 下降最多的分裂。
### 分裂准则
在每个节点,我们遍历所有特征 $k$ 和所有可能的分裂点 $c$,计算分裂后的总 RSS:
$$Q(k, c) = \underbrace{\sum_{i: X_{ik} \leq c}(y_i - \bar{y}_{k,c}^L)^2}_{\text{左子节点 RSS}} + \underbrace{\sum_{i: X_{ik} > c}(y_i - \bar{y}_{k,c}^R)^2}_{\text{右子节点 RSS}}$$
其中 $\bar{y}_{k,c}^L = \text{mean}(y_i : X_{ik} \leq c)$ 是左子节点的预测值,$\bar{y}_{k,c}^R$ 是右子节点的预测值。选择使 $Q(k, c)$ 最小的 $(k, c)$ 进行分裂。
### 递归过程
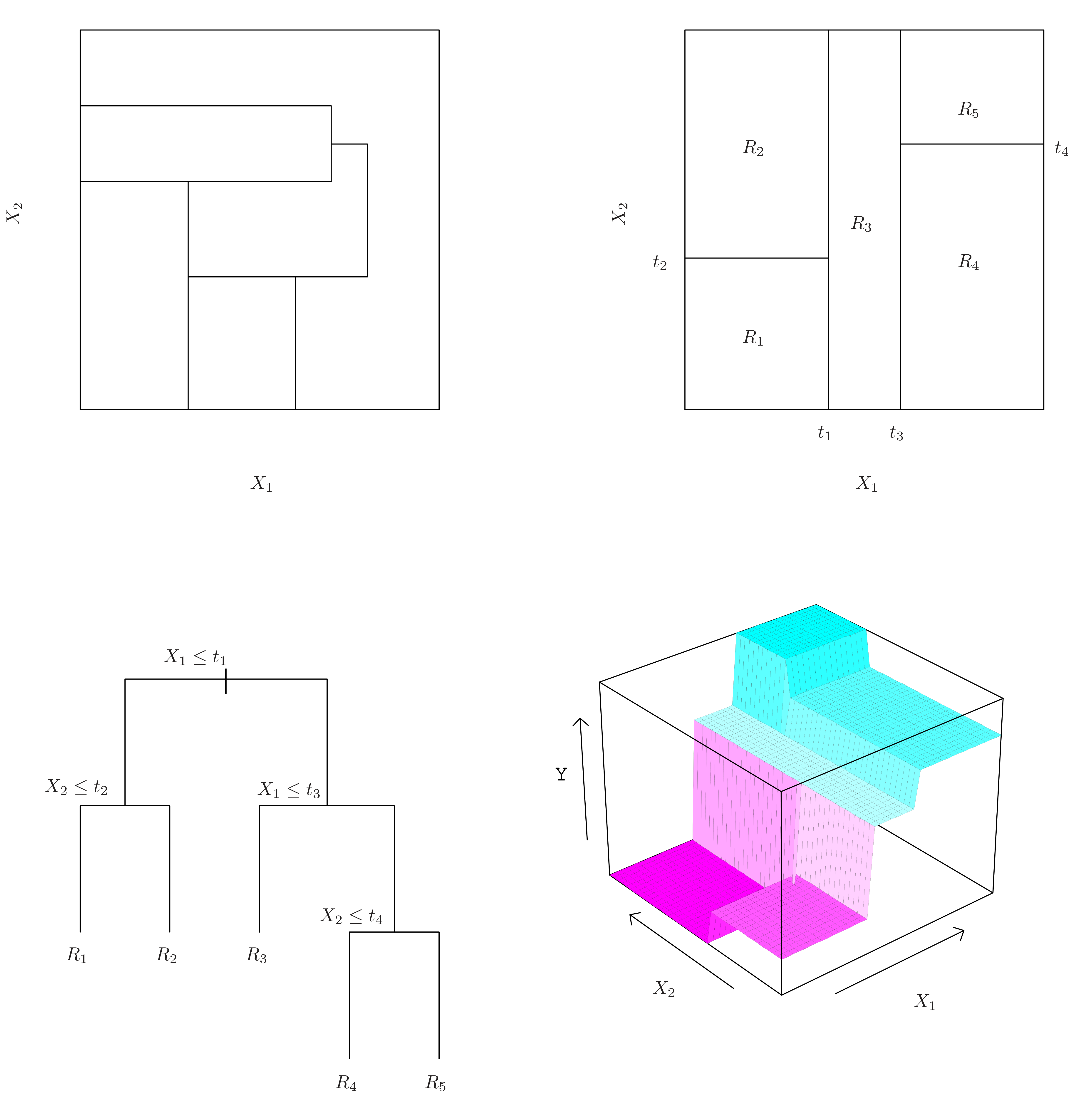{#fig-tree-recursive}
每一步分裂将一个已有的区域一分为二,然后对每个子区域独立地重复同样的分裂过程,直到满足停止条件(如最小节点大小、最大深度或 RSS 下降不显著)。
### 计算复杂度
对于 $n$ 个观测值和 $p$ 个特征,每次分裂的计算复杂度是 $O(np)$——遍历每个特征的 $n$ 个可能分裂点。如果树的深度为 $d$,总复杂度约为 $O(npd)$。这比线性回归的 $O(np^2)$ 在某些场景下更高效。
## 树剪枝 {#sec-pruning}
### 为什么需要剪枝
不加限制地生长树会导致严重的过拟合——每个叶节点可能只包含极少数观测值,使得模型本质上是在“记忆”训练数据。
### 代价复杂度剪枝
代价复杂度剪枝(Cost Complexity Pruning)在训练误差中加入对树大小的惩罚项:
$$C_\lambda(T) = \sum_{j=1}^{|T|}\sum_{i \in R_j}(y_i - \hat{y}_{R_j})^2 + \lambda|T|$$
其中 $|T|$ 是树 $T$ 的叶节点数量,$\lambda \geq 0$ 是调节参数。
- 当 $\lambda = 0$ 时,惩罚为零,等价于完全生长的树
- 随着 $\lambda$ 增大,对树的复杂度惩罚加重,倾向于选择较小的树
- $\lambda$ 的最优值通过**交叉验证**选择
这里可以清晰地看到前面学的交叉验证如何与树模型相结合——CV 帮助我们在树的“大小”(复杂度)上做出最优选择。
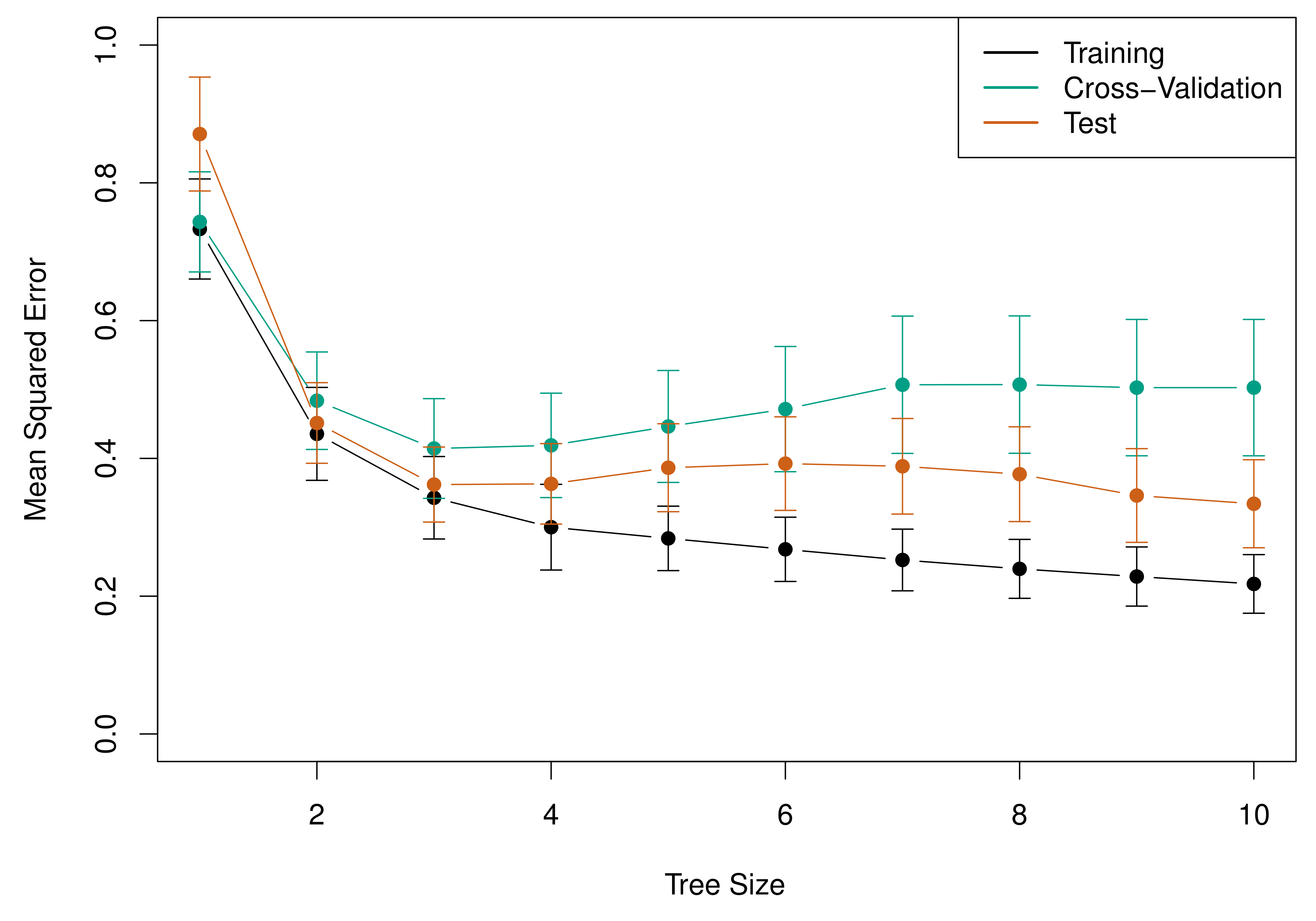{#fig-tree-cv}
## 树模型 vs. 线性模型 {#sec-tree-vs-linear}
什么时候该用树模型,什么时候该用线性模型?答案取决于真实数据生成过程的形状:
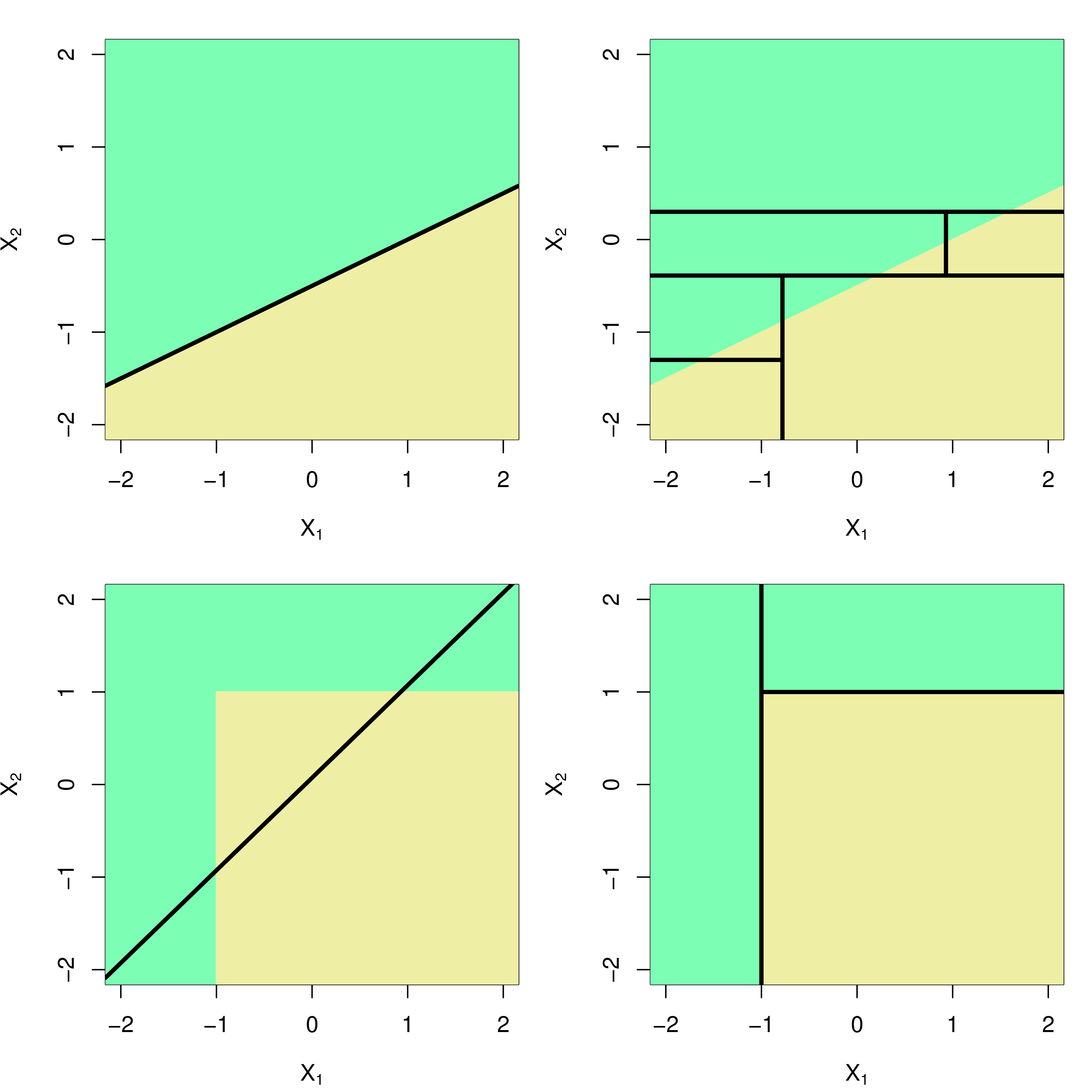{#fig-tree-vs-linear}
- **左图**:真实关系接近线性时,线性回归的预测更好
- **右图**:真实关系存在复杂的非线性和交互效应时,树模型更优
### Python 实现:回归树与剪枝
```{python}
#| code-fold: show
#| code-summary: "点击查看完整代码"
#| fig-cap: "不同深度的回归树拟合与树结构可视化"
#| fig-width: 12
#| fig-height: 10
from sklearn.tree import DecisionTreeRegressor, plot_tree
from sklearn.model_selection import cross_val_score
np.random.seed(42)
n = 200
X_tree = np.sort(np.random.uniform(0, 10, n)).reshape(-1, 1)
y_tree = np.sin(X_tree.ravel()) + 0.3 * X_tree.ravel() + np.random.normal(0, 0.5, n)
fig = plt.figure(figsize=(12, 10))
# 上排:不同深度的拟合效果
for idx, depth in enumerate([2, 4, 10]):
ax = fig.add_subplot(2, 3, idx + 1)
tree = DecisionTreeRegressor(max_depth=depth, random_state=42)
tree.fit(X_tree, y_tree)
X_plot = np.linspace(0, 10, 500).reshape(-1, 1)
y_pred = tree.predict(X_plot)
ax.scatter(X_tree, y_tree, c='steelblue', alpha=0.3, s=15)
ax.plot(X_plot, y_pred, 'r-', linewidth=2)
train_mse = np.mean((y_tree - tree.predict(X_tree))**2)
cv_scores = cross_val_score(tree, X_tree, y_tree, cv=10, scoring='neg_mean_squared_error')
cv_mse = -cv_scores.mean()
ax.set_title(f'depth={depth}\nTrain MSE={train_mse:.3f}, CV MSE={cv_mse:.3f}', fontsize=11)
# 下排:最优树的结构可视化
ax_tree = fig.add_subplot(2, 1, 2)
best_tree = DecisionTreeRegressor(max_depth=3, random_state=42)
best_tree.fit(X_tree, y_tree)
plot_tree(best_tree, ax=ax_tree, filled=True, rounded=True,
feature_names=['X'], fontsize=9, impurity=True)
ax_tree.set_title('回归树结构(max_depth=3)', fontsize=13)
plt.tight_layout()
plt.show()
```
### 剪枝路径:通过交叉验证选择最优深度
```{python}
#| code-fold: show
#| code-summary: "点击查看剪枝路径代码"
#| fig-cap: "通过交叉验证选择最优树深度"
#| fig-width: 10
#| fig-height: 5
depths = range(1, 21)
train_mses = []
cv_mses = []
cv_stds = []
for d in depths:
tree = DecisionTreeRegressor(max_depth=d, random_state=42)
tree.fit(X_tree, y_tree)
train_mses.append(np.mean((y_tree - tree.predict(X_tree))**2))
scores = cross_val_score(tree, X_tree, y_tree, cv=10, scoring='neg_mean_squared_error')
cv_mses.append(-scores.mean())
cv_stds.append(scores.std())
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(depths, train_mses, 'b--o', label='训练 MSE', markersize=5)
ax.plot(depths, cv_mses, 'r-o', label='10-Fold CV MSE', markersize=5)
ax.fill_between(depths,
np.array(cv_mses) - np.array(cv_stds),
np.array(cv_mses) + np.array(cv_stds), alpha=0.2, color='red')
best_depth = list(depths)[np.argmin(cv_mses)]
ax.axvline(x=best_depth, color='green', linestyle=':', linewidth=2,
label=f'最优深度 = {best_depth}')
ax.set_xlabel('树的最大深度', fontsize=12)
ax.set_ylabel('MSE', fontsize=12)
ax.set_title('回归树的训练误差 vs. 交叉验证误差', fontsize=14)
ax.legend(fontsize=11)
plt.tight_layout()
plt.show()
```
### R 语言对照
```{r}
#| eval: false
#| echo: true
library(rpart)
library(rpart.plot)
# 训练回归树
tree_model <- rpart(y ~ x, data = df,
control = rpart.control(cp = 0.01, maxdepth = 10))
# 可视化树结构
rpart.plot(tree_model, type = 4, extra = 101,
box.palette = "RdBu", main = "回归树")
# 查看剪枝路径(cp table)
printcp(tree_model)
plotcp(tree_model) # 交叉验证误差 vs. cp
# 选择最优 cp 并剪枝
best_cp <- tree_model$cptable[which.min(tree_model$cptable[, "xerror"]), "CP"]
pruned_tree <- prune(tree_model, cp = best_cp)
rpart.plot(pruned_tree, type = 4, extra = 101)
```
## 回归树的优缺点 {#sec-tree-pros-cons}
::: {.callout-tip}
## 优点
- **直观易解释**:树结构可以直接可视化,非专业人士也能理解
- **自动处理非线性和交互效应**:不需要手动创建交互项或多项式项
- **不需要特征标准化**:分裂只涉及单个变量的阈值比较
- **对异常值相对稳健**:基于排序而非距离的分裂方式
- **可作为变量选择工具**:分裂频率反映变量重要性
:::
::: {.callout-warning}
## 缺点
- **预测精度有限**:单棵树的预测精度通常不如其他方法
- **高方差**:对数据的微小变化非常敏感——增减几个观测值可能改变整棵树的结构
- **不擅长线性关系**:需要很多“台阶”来近似一条直线
- **决策边界受限**:轴平行的矩形边界,无法表达斜向分界
这些缺点引出了一个自然的改进方向——如何利用多棵树的“集体智慧”来克服单棵树的不足?
:::
# 第五部分:随机森林 {#sec-random-forest}
## 集成学习的核心思想 {#sec-ensemble-idea}
随机森林属于**集成学习**(Ensemble Learning)方法族——通过组合多个弱学习器来构建一个强学习器。其核心思想可以用一句中国谚语来概括:
> “三个臭皮匠,赛过一个诸葛亮。”
单棵决策树方差大、不稳定。但如果我们训练**很多棵树**,然后取它们的预测平均值,方差就会大幅降低。
### 为什么平均能降低方差
这背后的数学原理非常直观。如果 $Z_1, Z_2, \ldots, Z_B$ 是独立同分布的随机变量,$\text{Var}(Z_i) = \sigma^2$,那么它们均值的方差为:
$$\text{Var}(\bar{Z}) = \text{Var}\left(\frac{1}{B}\sum_{b=1}^{B}Z_b\right) = \frac{\sigma^2}{B}$$
当 $B$ 足够大时,方差趋近于零。但问题在于:**从同一数据集训练的多棵树是高度相关的**,它们并不是独立的!如果树与树之间的相关系数为 $\rho$,那么平均值的方差变为:
$$\text{Var}(\bar{Z}) = \rho\sigma^2 + \frac{1-\rho}{B}\sigma^2$$
第一项 $\rho\sigma^2$ 不随 $B$ 增加而减小——这就是为什么仅仅训练多棵相同的树并取平均(Bagging)还不够,我们还需要**降低树之间的相关性**。
## Bagging {#sec-bagging}
### Bootstrap Aggregation
Bagging(Bootstrap Aggregation)是第一步——通过自助抽样(Bootstrap)产生多个不同的训练集:
1. 从原始训练数据中**有放回地**抽取 $B$ 个自助样本
2. 在每个自助样本上独立训练一棵充分生长的深树(不剪枝)
3. 对 $B$ 棵树的预测取**平均**:
$$\hat{f}_{bag}(x) = \frac{1}{B}\sum_{b=1}^{B}\hat{f}_b(x)$$
每个自助样本大约包含原数据 63.2% 的独特观测值(剩余 36.8% 被称为 Out-of-Bag, OOB 样本)。OOB 样本可以作为“免费”的验证集,无需额外的交叉验证。
::: {.callout-warning}
## Bagging 的局限
如果存在一个**非常强的预测变量**(如 $X_1$),那么每棵树的顶层分裂几乎都会选择 $X_1$——所有的树在结构上高度相似。这意味着树与树的相关系数 $\rho$ 很大,方差缩减效果有限。
:::
## 随机森林算法 {#sec-rf-algorithm}
随机森林(Random Forest, Breiman, 2001)在 Bagging 的基础上增加了一个关键创新——**特征随机化**:在每次分裂时,只从 $p$ 个特征中随机选择 $m$ 个候选特征进行考虑(通常 $m = \sqrt{p}$ 或 $m = p/3$)。
### 完整算法
对 $b = 1, 2, \ldots, B$(通常 $B = 100 \sim 500$):
1. 从训练数据中有放回地抽取一个自助样本
2. 在自助样本上生长树,对每个节点的分裂:
a. 从全部 $p$ 个特征中**随机选择 $m$ 个**候选特征
b. 从这 $m$ 个特征中选择最优的分裂变量和分裂点
c. 将节点一分为二
3. 不进行剪枝,让树充分生长
最终预测为所有树的平均:
$$\hat{f}_{RF}(x) = \frac{1}{B}\sum_{b=1}^{B}\hat{f}_b(x)$$
### 去相关的直觉
为什么随机选择特征能降低树的相关性?考虑一个类比:
::: {.callout-tip}
## 类比:专家委员会
想象你要预测房价,召集了 100 位房产评估专家:
- **单棵决策树**:一位专家自己做所有判断
- **Bagging**:100 位专家分别独立评估——但每人面前摆的是**所有信息**,所以大家的评估逻辑很相似
- **随机森林**:100 位专家,但每人只看**随机几个因素**——有人重点看地段,有人重点看面积,有人重点看学区
当打分角度被强制分散后,每位专家的判断更加独立,集体投票的结果也更稳健、更准确。
:::
### 随机森林与核回归的关系
从数学角度看,随机森林本质上是一种**自适应加权近邻方法**:
$$\hat{\mu}_{RF}(x) = \sum_{i=1}^{n}\alpha_i(x) \cdot y_i, \quad \sum_{i=1}^{n}\alpha_i(x) = 1, \quad \alpha_i(x) \geq 0$$
权重 $\alpha_i(x)$ 是 $x$ 与 $x_i$ 在所有树中落入相同叶节点的频率。这等价于一种核回归,但核函数由数据**自适应**确定——它能自动发现哪些维度重要、哪些维度可以忽略,从而在高维空间中避免了“维度灾难”。
## 随机森林的实证表现 {#sec-rf-performance}
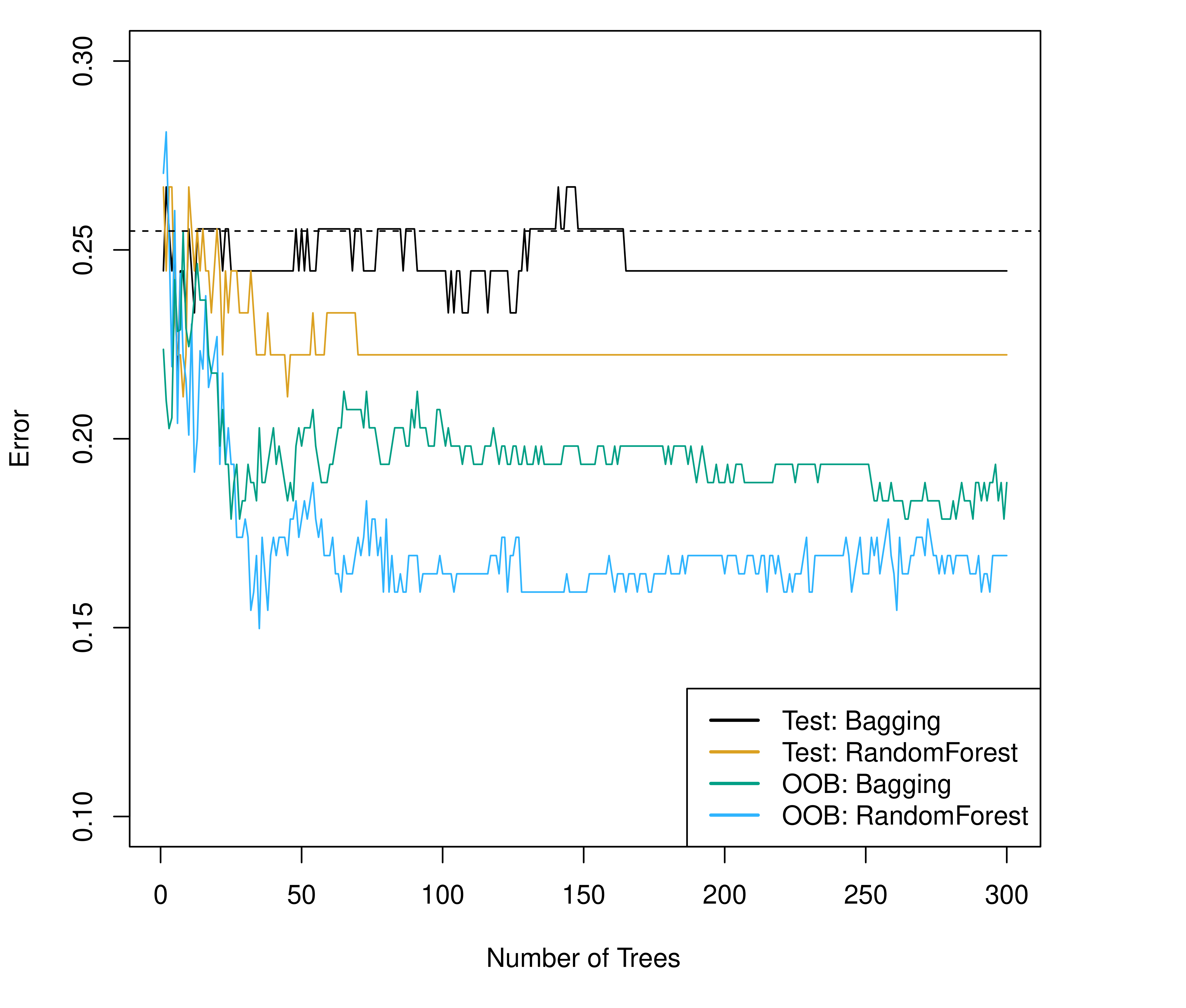{#fig-rf-bagging}
上图展示了 Bagging(绿色,$m = p$)与随机森林(橙色,$m = \sqrt{p}$)的预测误差随树数量增加的变化。随机森林在特征随机化的帮助下,通常能达到更低的测试误差——尤其当存在少数强预测变量时,效果差异更为显著。
## 变量重要性 {#sec-variable-importance}
虽然随机森林本身是一个“黑箱”模型,但我们可以通过**变量重要性**来理解哪些特征对预测最有贡献。
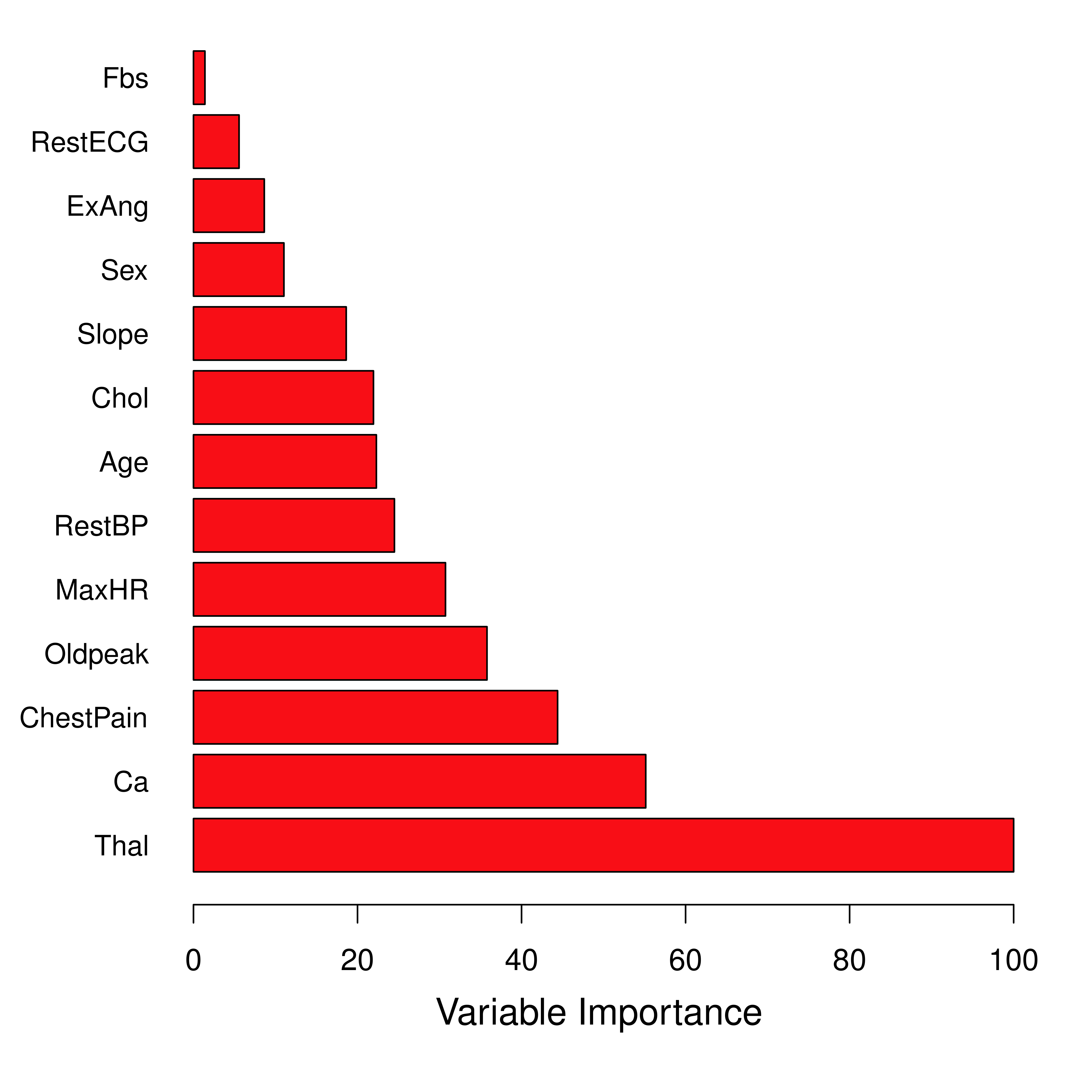{#fig-importance}
变量重要性的计算方法:对于每个特征 $X_k$,计算它在所有树的所有分裂中带来的 RSS 减少总量。分裂越频繁、RSS 减少越大的变量越“重要”。
另一种常用的度量是**排列重要性**(Permutation Importance):随机打乱变量 $X_k$ 的值,观察 OOB 误差增加了多少。误差增加越大,说明该变量越重要。
### Python 实现:完整的随机森林分析
```{python}
#| code-fold: show
#| code-summary: "点击查看完整代码"
#| fig-cap: "随机森林:预测对比、OOB 误差收敛与变量重要性"
#| fig-width: 12
#| fig-height: 10
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
np.random.seed(42)
n = 300
p = 5
X_rf = np.random.uniform(0, 10, (n, p))
y_rf = (np.sin(X_rf[:, 0]) + 0.5 * X_rf[:, 1] +
0.2 * X_rf[:, 0] * X_rf[:, 1] + np.random.normal(0, 0.5, n))
fig = plt.figure(figsize=(12, 10))
# 1. 单棵树 vs. 随机森林
ax1 = fig.add_subplot(2, 2, 1)
tree_single = DecisionTreeRegressor(max_depth=5, random_state=42)
rf_model = RandomForestRegressor(n_estimators=200, max_depth=5, random_state=42, oob_score=True)
tree_single.fit(X_rf, y_rf)
rf_model.fit(X_rf, y_rf)
x1_grid = np.linspace(0, 10, 200)
X_plot_rf = np.column_stack([x1_grid] + [np.full(200, 5)] * (p - 1))
ax1.plot(x1_grid, tree_single.predict(X_plot_rf), 'b--', alpha=0.7, linewidth=1.5, label='单棵树')
ax1.plot(x1_grid, rf_model.predict(X_plot_rf), 'r-', linewidth=2, label='随机森林 (200棵树)')
true_vals = np.sin(x1_grid) + 0.5 * 5 + 0.2 * x1_grid * 5
ax1.plot(x1_grid, true_vals, 'k--', alpha=0.5, linewidth=1, label='真实函数')
ax1.set_xlabel('$X_1$', fontsize=12)
ax1.set_ylabel('预测值', fontsize=12)
ax1.set_title('单棵树 vs. 随机森林', fontsize=13)
ax1.legend(fontsize=10)
# 2. OOB 误差随树数量的收敛
ax2 = fig.add_subplot(2, 2, 2)
n_trees_list = [1, 5, 10, 20, 50, 100, 200, 300, 500]
oob_errors = []
for n_trees in n_trees_list:
rf_temp = RandomForestRegressor(n_estimators=n_trees, max_depth=5,
random_state=42, oob_score=True)
rf_temp.fit(X_rf, y_rf)
oob_errors.append(1 - rf_temp.oob_score_)
ax2.plot(n_trees_list, oob_errors, 'b-o', markersize=5)
ax2.set_xlabel('树的数量', fontsize=12)
ax2.set_ylabel('OOB 误差', fontsize=12)
ax2.set_title('OOB 误差随树数量的收敛', fontsize=13)
ax2.set_xscale('log')
# 3. 变量重要性
ax3 = fig.add_subplot(2, 2, 3)
importances = rf_model.feature_importances_
features = [f'$X_{i+1}$' for i in range(p)]
sorted_idx = np.argsort(importances)
colors = ['#AE0B2A' if i in [0, 1] else 'steelblue' for i in sorted_idx]
ax3.barh(range(p), importances[sorted_idx], color=colors)
ax3.set_yticks(range(p))
ax3.set_yticklabels([features[i] for i in sorted_idx])
ax3.set_xlabel('重要性', fontsize=12)
ax3.set_title('变量重要性(红色 = 真实有效变量)', fontsize=13)
# 4. max_features 的影响
ax4 = fig.add_subplot(2, 2, 4)
m_values = range(1, p + 1)
cv_mses_m = []
for m in m_values:
rf_temp = RandomForestRegressor(n_estimators=100, max_features=m,
max_depth=5, random_state=42)
scores = cross_val_score(rf_temp, X_rf, y_rf, cv=10, scoring='neg_mean_squared_error')
cv_mses_m.append(-scores.mean())
ax4.bar(m_values, cv_mses_m, color='steelblue', alpha=0.7)
ax4.set_xlabel('max_features (m)', fontsize=12)
ax4.set_ylabel('10-Fold CV MSE', fontsize=12)
ax4.set_title(f'm 的选择(推荐 $\\sqrt{{p}}$ ≈ {int(np.sqrt(p))})', fontsize=13)
ax4.axvline(x=int(np.sqrt(p)), color='#AE0B2A', linestyle='--', linewidth=2)
plt.tight_layout()
plt.show()
```
### R 语言对照
```{r}
#| eval: false
#| echo: true
library(ranger)
library(vip)
# 训练随机森林
rf_model <- ranger(y ~ ., data = df,
num.trees = 500,
mtry = floor(sqrt(ncol(df) - 1)),
importance = "impurity",
oob.error = TRUE)
# 查看 OOB 误差
cat("OOB MSE:", rf_model$prediction.error, "\n")
# 变量重要性
vip(rf_model, num_features = 10, bar = TRUE) +
ggtitle("变量重要性(随机森林)")
# 使用 caret 进行超参数调优
library(caret)
tune_grid <- expand.grid(
mtry = 1:5,
splitrule = "variance",
min.node.size = c(1, 5, 10)
)
rf_tuned <- train(y ~ ., data = df, method = "ranger",
trControl = trainControl(method = "cv", number = 10),
tuneGrid = tune_grid)
print(rf_tuned)
plot(rf_tuned)
```
## 超参数调优 {#sec-hyperparameters}
随机森林的主要超参数及其调优建议:
| 参数 | 含义 | 典型值 | 调优建议 |
|:---|:---|:---|:---|
| `n_estimators` | 树的数量 $B$ | 100–500 | 越大越好(但收益递减),观察 OOB 误差收敛 |
| `max_depth` | 每棵树的最大深度 | `None` 或 5–20 | 通过 CV 选择 |
| `max_features` | 每次分裂的候选特征数 $m$ | $\sqrt{p}$ 或 $p/3$ | 回归默认 $p/3$,分类默认 $\sqrt{p}$ |
| `min_samples_leaf` | 叶节点最小样本数 | 1–10 | 较大的值有正则化效果 |
所有超参数都应通过**交叉验证**来选择——这也是本讲各部分串联的逻辑:偏差-方差权衡解释了为什么需要调参,交叉验证提供了调参的工具,树和森林是需要调参的模型。
# 总结 {#sec-summary}
## 本讲要点回顾 {#sec-key-points}
### 1. 从因果推断到机器学习
传统计量经济学和机器学习代表了两种不同的研究范式。前者关注参数估计和因果推断(“为什么”),后者关注预测精度的最大化(“如何预测”)。Breiman (2001) 的“两种文化”论文标志着这一对比的开端,而因果机器学习正在推动两者的融合。
### 2. 偏差-方差权衡
这是理解所有机器学习方法的核心框架。测试误差可以精确分解为偏差²、方差和不可约误差三个部分。模型太简单(高偏差、低方差)和太复杂(低偏差、高方差)都不是最优选择——关键是找到中间的平衡点。
### 3. 交叉验证
K 折交叉验证是估计测试误差的标准方法,广泛用于模型选择和超参数调优。实践中通常取 $K = 5$ 或 $K = 10$。与信息准则相比,CV 的最大优势是不依赖特定的模型假设,适用于任何预测方法。
### 4. 回归树
回归树通过递归二元分裂将特征空间划分为矩形区域。它直观、易解释,能自动处理非线性和交互效应。但单棵树的主要缺点是高方差——对数据变化过于敏感。代价复杂度剪枝通过惩罚树的大小来控制过拟合,$\lambda$ 通过 CV 选择。
### 5. 随机森林
随机森林通过 Bagging + 特征随机化构建多棵去相关的树,然后取平均。这同时降低了方差(通过平均)并保持了低偏差(每棵树充分生长)。变量重要性提供了一种理解“黑箱”模型的方式。
## 关键公式汇总 {#sec-formulas}
| 概念 | 公式 | 说明 |
|:---|:---|:---|
| 偏差-方差分解 | $E[(y_0 - \hat{f}(x_0))^2] = \text{Var}(\hat{f}) + \text{Bias}^2(\hat{f}) + \sigma^2$ | 测试误差的三项分解 |
| K 折 CV | $CV_{(K)} = \frac{1}{K}\sum_{k=1}^{K} MSE_k$ | $K$ 次验证误差的平均 |
| 树分裂准则 | $Q(k,c) = RSS_L + RSS_R$ | 选择使总 RSS 最小的 $(k, c)$ |
| 代价复杂度剪枝 | $C_\lambda(T) = \sum RSS_j + \lambda|T|$ | $\lambda$ 通过 CV 选择 |
| 随机森林预测 | $\hat{f}_{RF}(x) = \frac{1}{B}\sum_{b=1}^{B}\hat{f}_b(x)$ | $B$ 棵树的预测平均 |
| 相关树的方差 | $\text{Var}(\bar{Z}) = \rho\sigma^2 + \frac{(1-\rho)\sigma^2}{B}$ | 解释为何需要去相关 |
## 下一讲预告 {#sec-next}
**第八讲:机器学习基础 II——梯度提升、正则化与模型选择**
本讲学习了两大类对抗过拟合的方法:交叉验证(选择模型复杂度)和集成方法(通过组合多个模型降低方差)。下一讲将介绍另外两种重要的思路:
- **正则化方法**(LASSO、Ridge):在损失函数中直接惩罚模型复杂度,实现特征选择和系数压缩
- **梯度提升**(Gradient Boosting):与随机森林不同,它通过**顺序地**训练弱学习器来逐步改进预测,是目前 Kaggle 竞赛和工业实践中最强大的预测工具之一
- **模型选择与评估**:如何在多种 ML 方法之间做出选择
掌握这些工具后,我们将进入课程最核心的部分——**用机器学习方法估计异质性处理效应**(Causal Forest, Double/Debiased ML 等)。
## 推荐阅读路线 {#sec-reading}
对于有兴趣深入学习的同学,推荐以下阅读路线:
1. **入门**:James, Witten, Hastie & Tibshirani (2021). *An Introduction to Statistical Learning* (ISL), Chapters 2, 5, 8 — 本讲的主要参考
2. **进阶**:Hastie, Tibshirani & Friedman (2009). *The Elements of Statistical Learning* (ESL), Chapters 9, 15 — 更深入的数学处理
3. **经济学视角**:
- Mullainathan & Spiess (2017). Machine Learning: An Applied Econometric Approach. *JEP*
- Athey & Imbens (2019). Machine Learning Methods That Economists Should Know About. *ARE*
4. **前沿应用**:
- Athey & Wager (2018). Estimation and Inference of Heterogeneous Treatment Effects using Random Forests. *JASA*
- Chernozhukov et al. (2018). Double/Debiased Machine Learning. *Econometrics Journal*
## 课后思考 {#sec-questions}
1. **在你的研究领域**,能否找到一个传统线性回归可能不够用的预测问题?过拟合和欠拟合各自可能表现为什么?如何用交叉验证来选择最合适的模型复杂度?
2. **关于偏差-方差权衡**:一位同学认为“增加样本量总是能降低预测误差”。请从偏差-方差分解的角度分析这一说法是否正确。增加样本量对偏差、方差和不可约误差分别有什么影响?
3. **关于随机森林**:如果数据中只有 2 个特征($p = 2$),随机森林的 `max_features` 应该设为多少?此时随机森林与 Bagging 有何区别?这种情况下还有去相关的效果吗?
# 参考文献 {#sec-references}
1. Athey, S., & Imbens, G. W. (2019). Machine Learning Methods That Economists Should Know About. *Annual Review of Economics*, 11, 685-725.
2. Athey, S., & Wager, S. (2018). Estimation and Inference of Heterogeneous Treatment Effects using Random Forests. *Journal of the American Statistical Association*, 113(523), 1228-1242.
3. Breiman, L. (2001). Statistical Modeling: The Two Cultures. *Statistical Science*, 16(3), 199-231.
4. Breiman, L. (2001). Random Forests. *Machine Learning*, 45, 5-32.
5. Chernozhukov, V., Chetverikov, D., Demirer, M., Duflo, E., Hansen, C., Newey, W., & Robins, J. (2018). Double/Debiased Machine Learning for Treatment and Structural Parameters. *The Econometrics Journal*, 21(1), C1-C68.
6. Hastie, T., Tibshirani, R., & Friedman, J. (2009). *The Elements of Statistical Learning* (2nd ed.). Springer.
7. James, G., Witten, D., Hastie, T., & Tibshirani, R. (2021). *An Introduction to Statistical Learning: with Applications in Python*. Springer.
8. Mullainathan, S., & Spiess, J. (2017). Machine Learning: An Applied Econometric Approach. *Journal of Economic Perspectives*, 31(2), 87-106.
---
**联系方式**
- 邮箱:chenzhiyuan@rmbs.ruc.edu.cn
- 办公室:919
- Office Hours:邮件或微信预约
*本讲义基于 James et al. (2021) “An Introduction to Statistical Learning” Chapters 2, 5, 8 整理而成,结合了 Athey & Imbens (2019) 和 Mullainathan & Spiess (2017) 的经济学视角。*



















