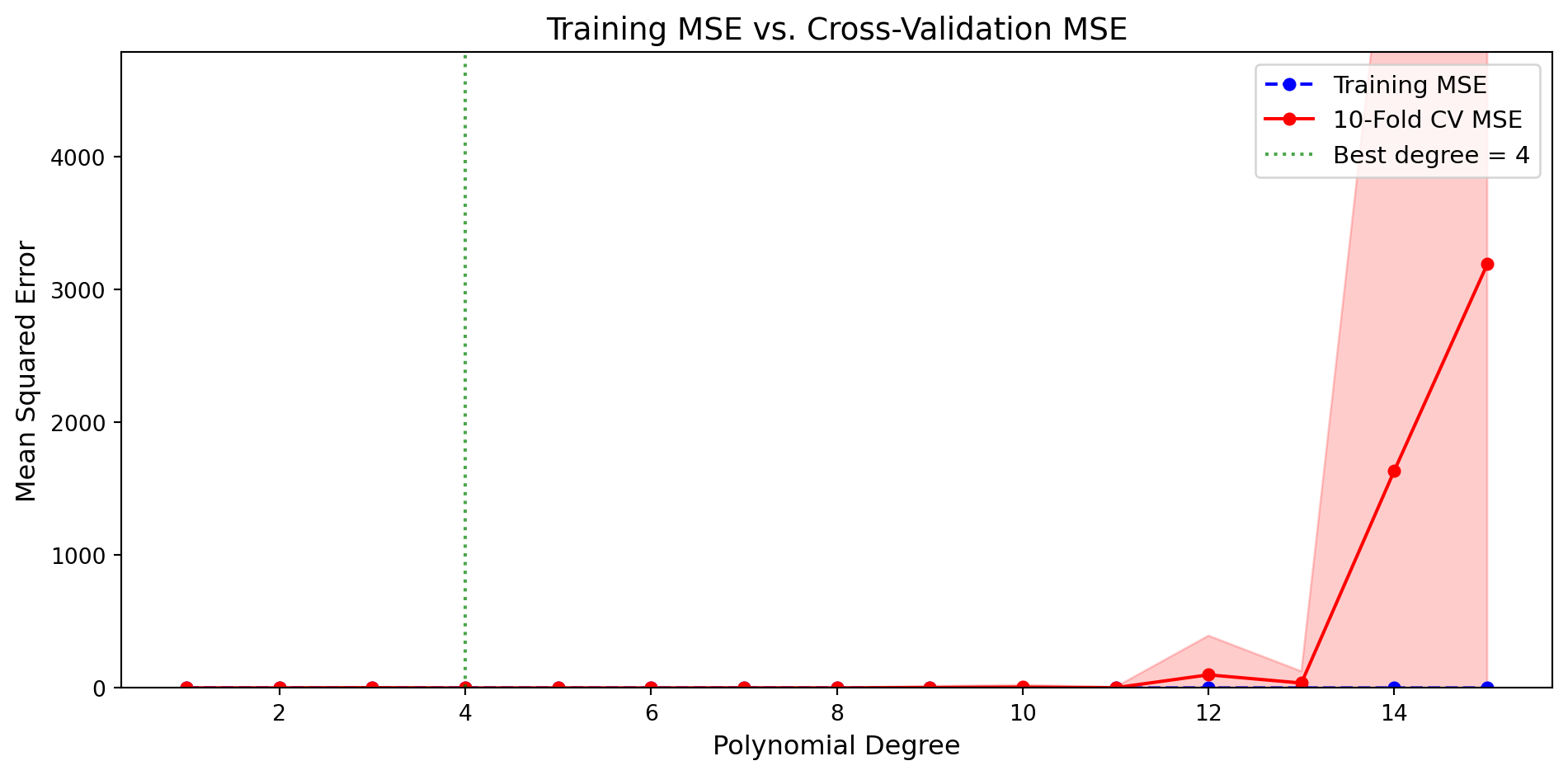
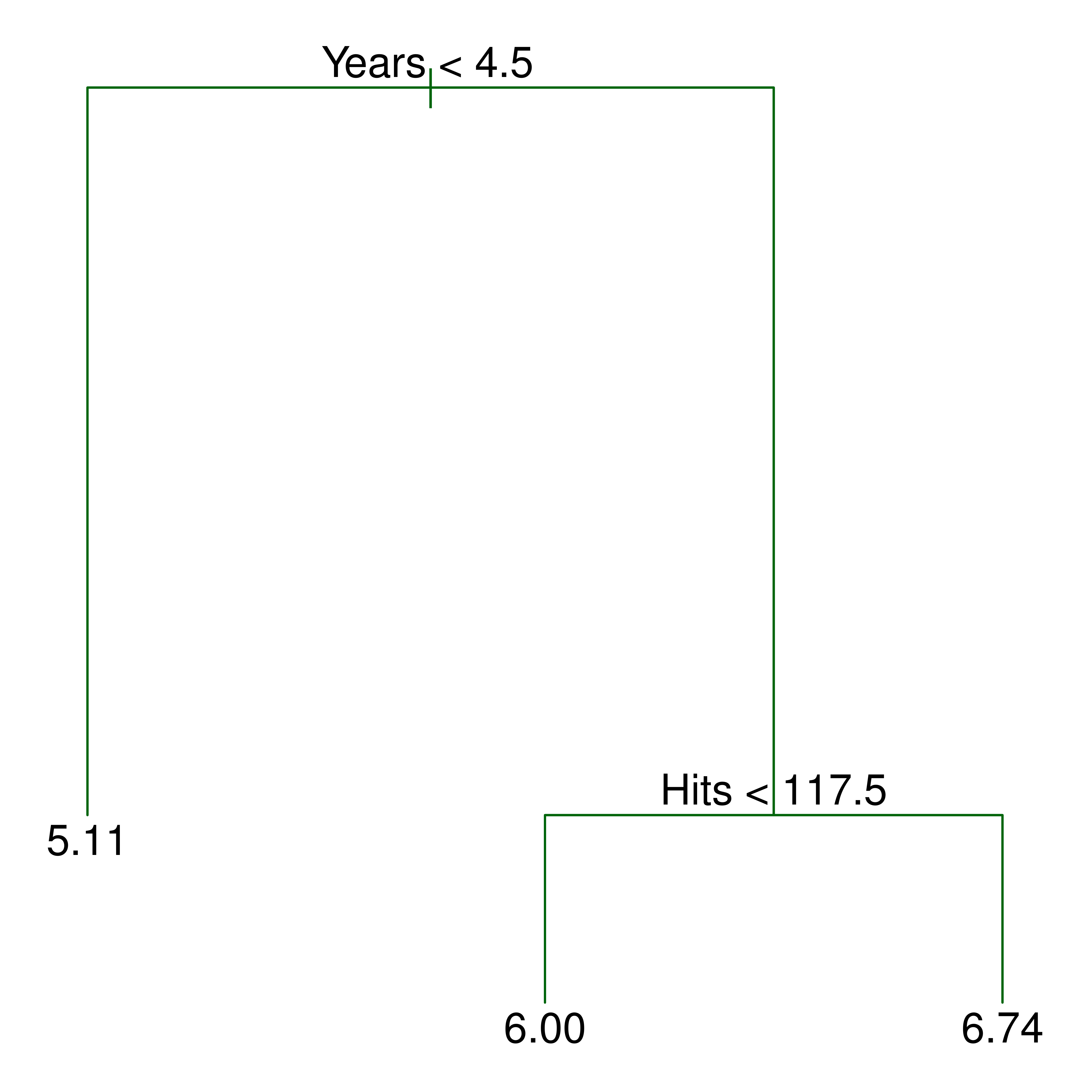
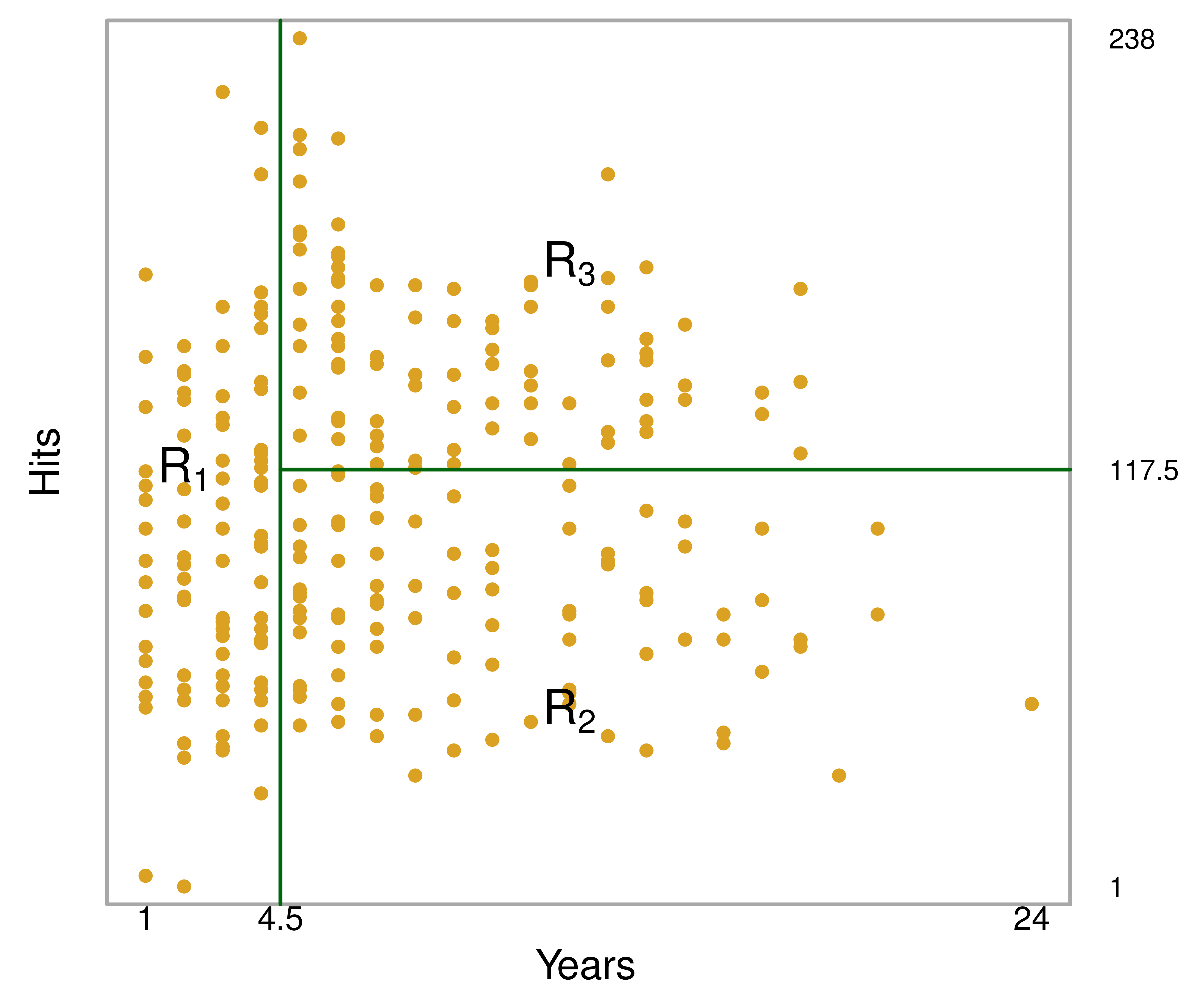
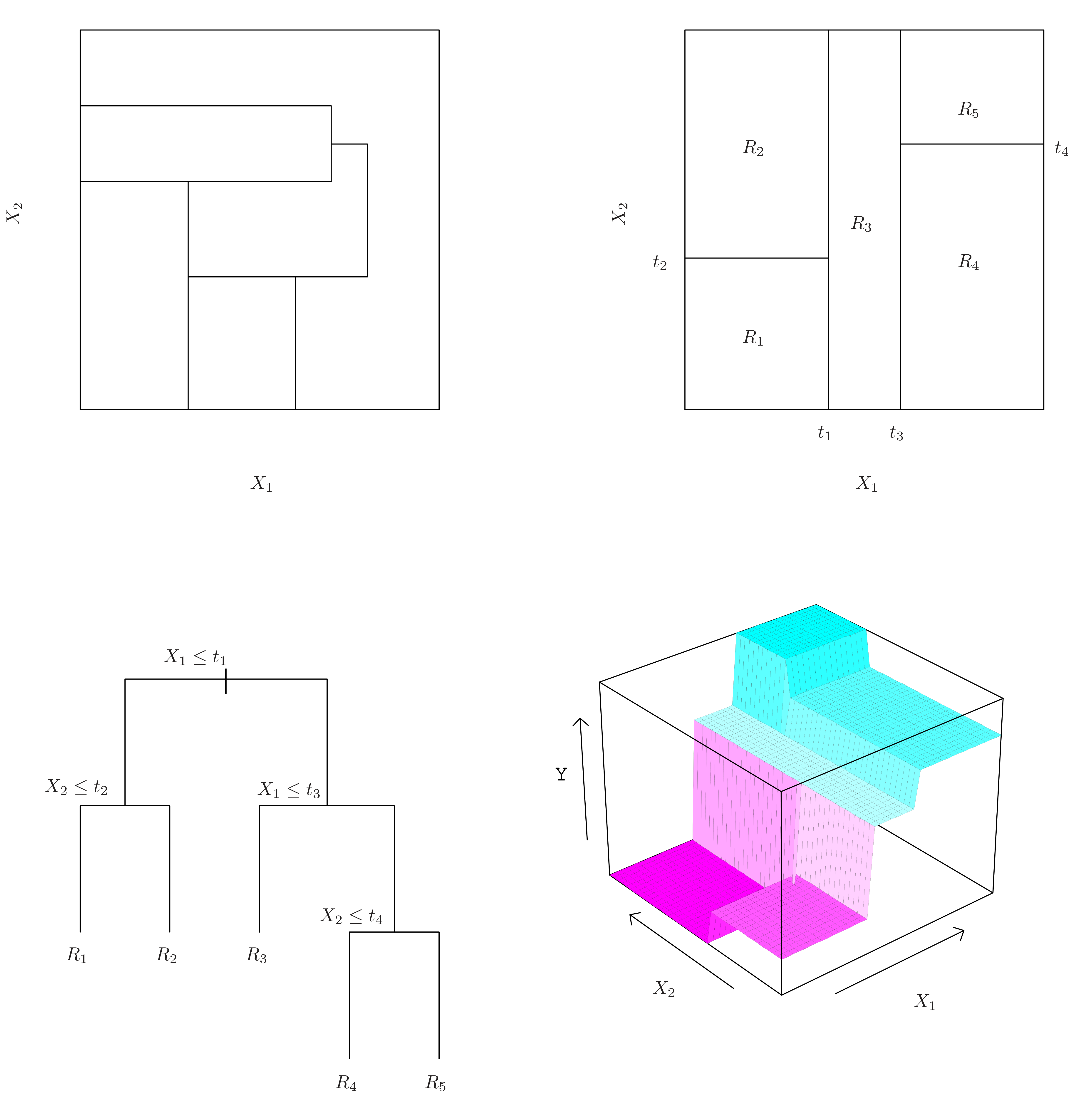
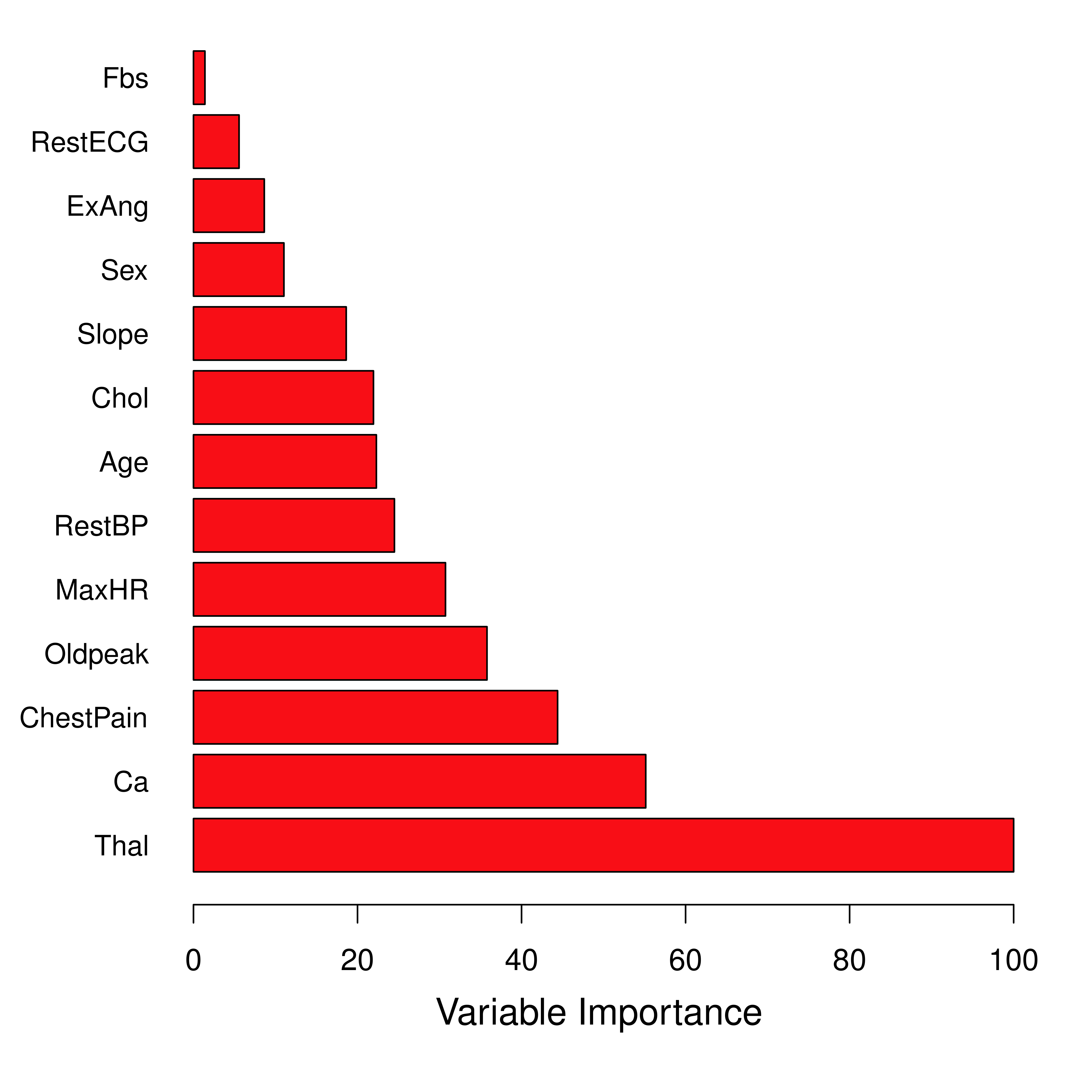
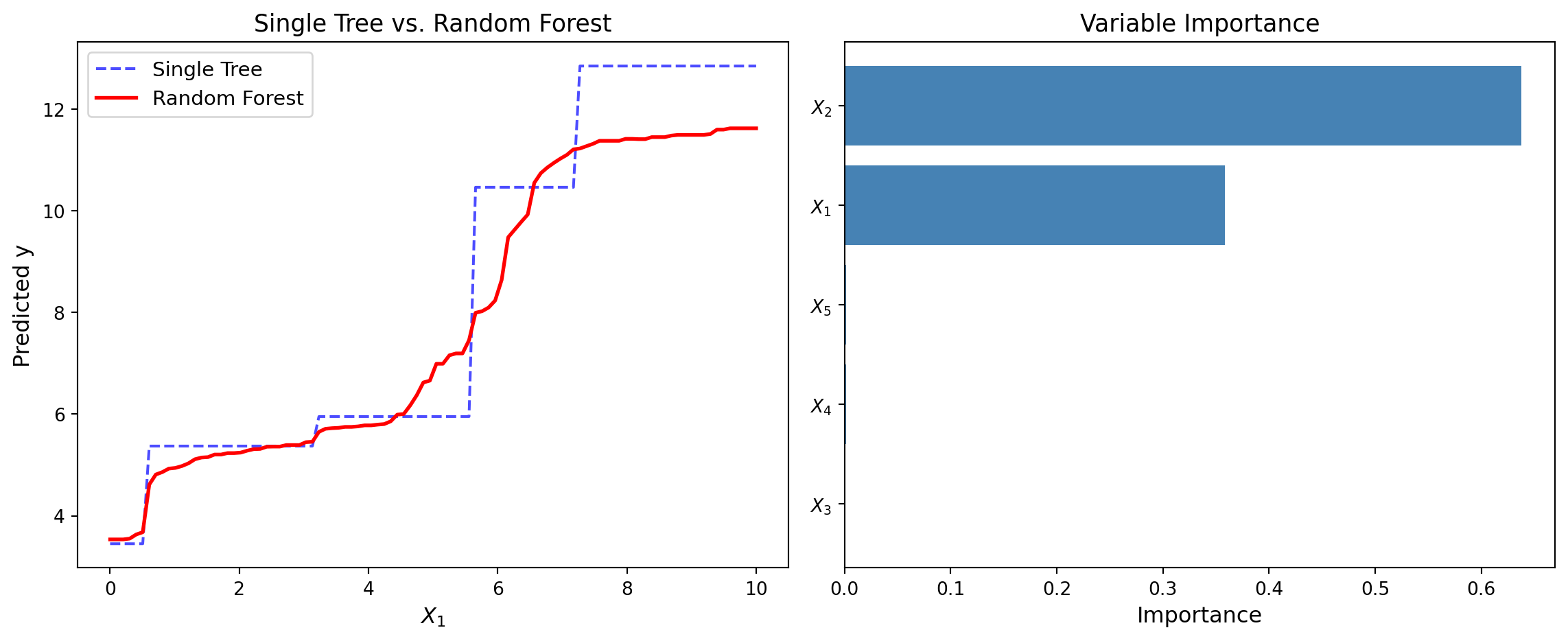
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import cross_val_score
np.random.seed(42)
n = 300
X_rf = np.random.uniform(0, 10, (n, 5))
y_rf = (np.sin(X_rf[:, 0]) + 0.5 * X_rf[:, 1] +
0.2 * X_rf[:, 0] * X_rf[:, 1] + np.random.normal(0, 0.5, n))
fig, axes = plt.subplots(1, 2, figsize=(12, 5))
# Left: Single tree vs Random Forest prediction
tree_single = DecisionTreeRegressor(max_depth=5, random_state=42)
rf = RandomForestRegressor(n_estimators=100, max_depth=5, random_state=42)
x1_grid = np.linspace(0, 10, 100)
X_plot_rf = np.column_stack([x1_grid, np.full(100, 5), np.full(100, 5),
np.full(100, 5), np.full(100, 5)])
tree_single.fit(X_rf, y_rf)
rf.fit(X_rf, y_rf)
axes[0].plot(x1_grid, tree_single.predict(X_plot_rf), 'b--', alpha=0.7, label='Single Tree')
axes[0].plot(x1_grid, rf.predict(X_plot_rf), 'r-', linewidth=2, label='Random Forest')
axes[0].set_xlabel('$X_1$', fontsize=12)
axes[0].set_ylabel('Predicted y', fontsize=12)
axes[0].set_title('Single Tree vs. Random Forest', fontsize=13)
axes[0].legend(fontsize=11)
# Right: Variable importance
importances = rf.feature_importances_
features = ['$X_1$', '$X_2$', '$X_3$', '$X_4$', '$X_5$']
sorted_idx = np.argsort(importances)
axes[1].barh(range(5), importances[sorted_idx], color='steelblue')
axes[1].set_yticks(range(5))
axes[1].set_yticklabels([features[i] for i in sorted_idx])
axes[1].set_xlabel('Importance', fontsize=12)
axes[1].set_title('Variable Importance', fontsize=13)
plt.tight_layout()
plt.show()