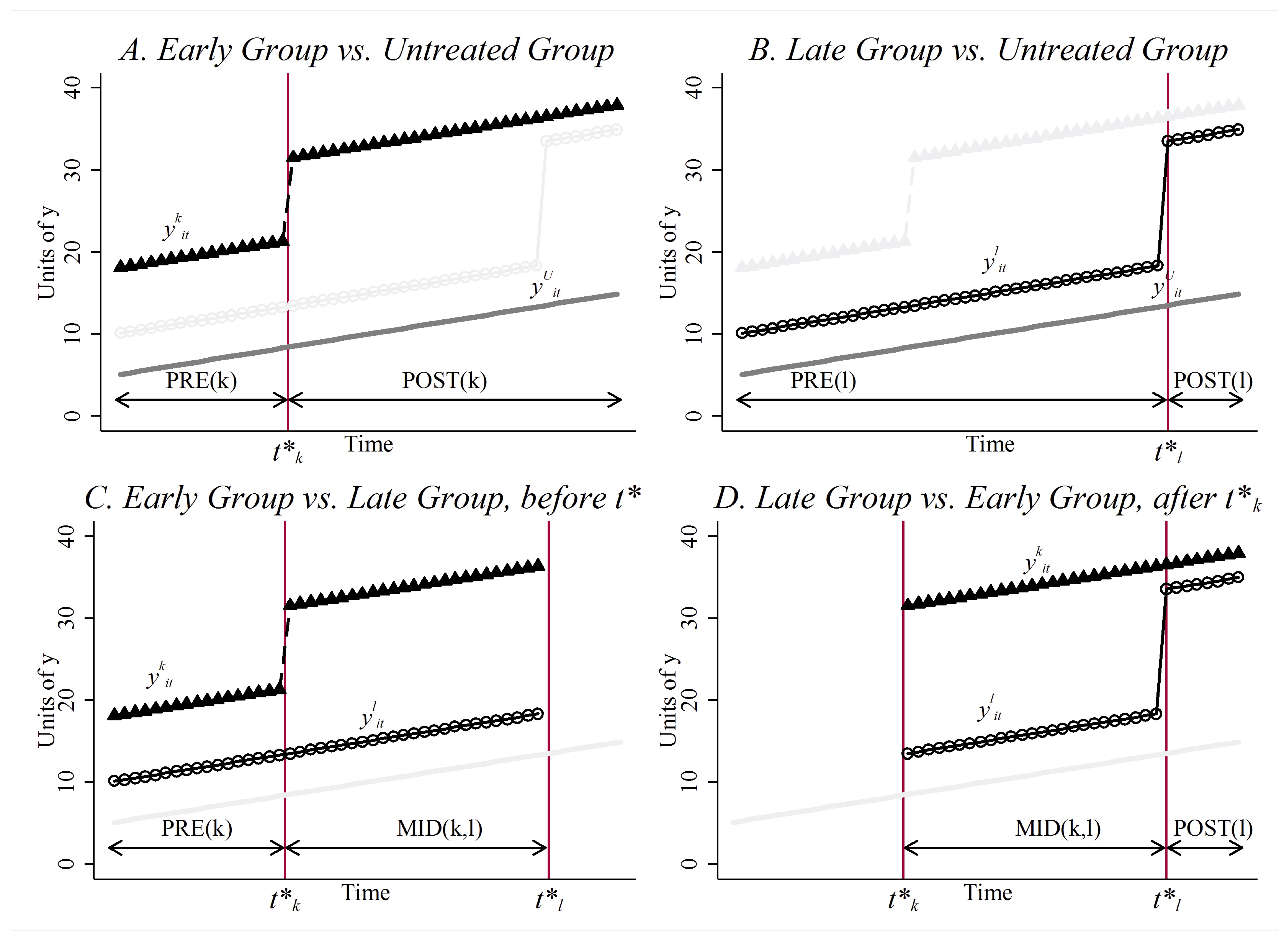
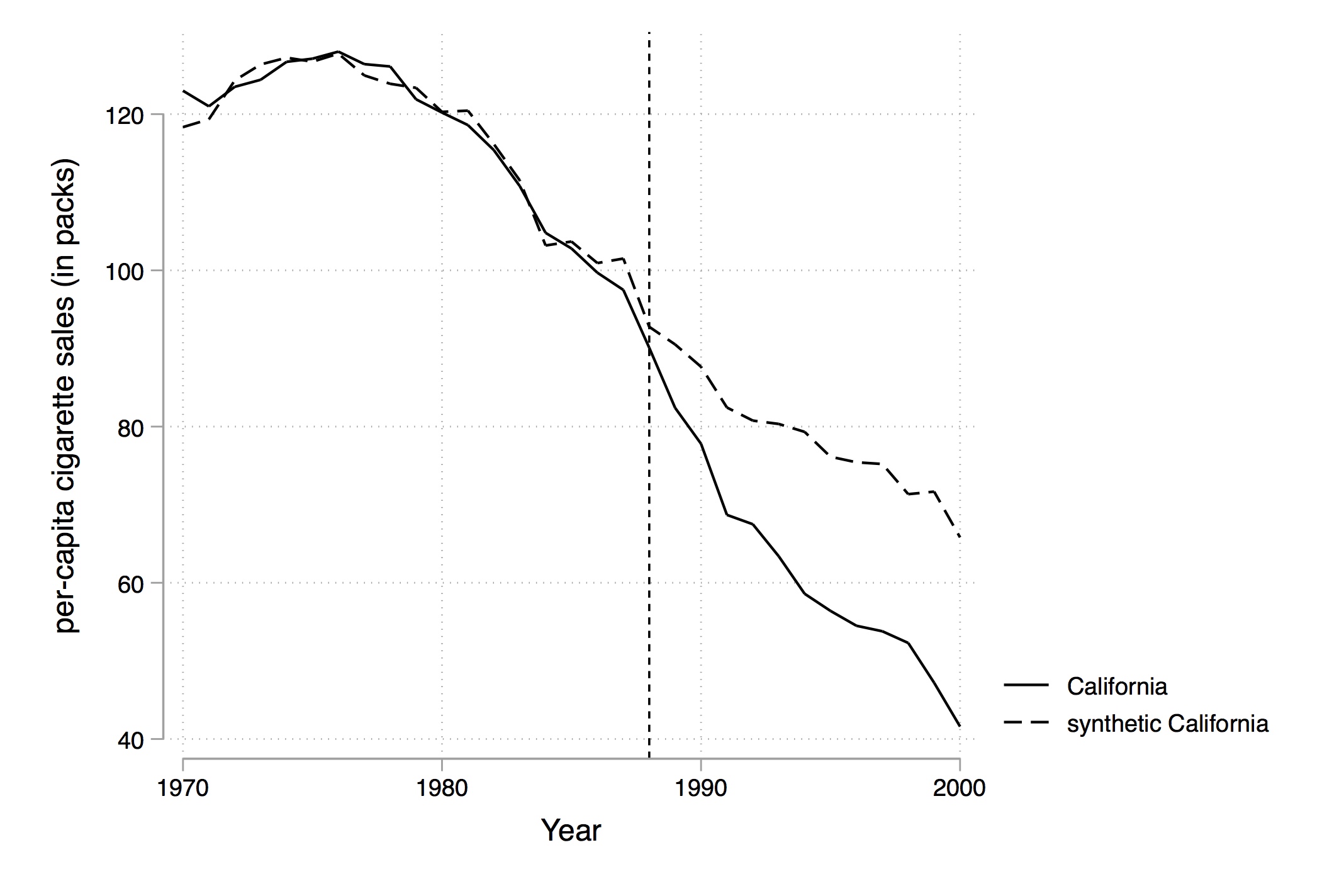
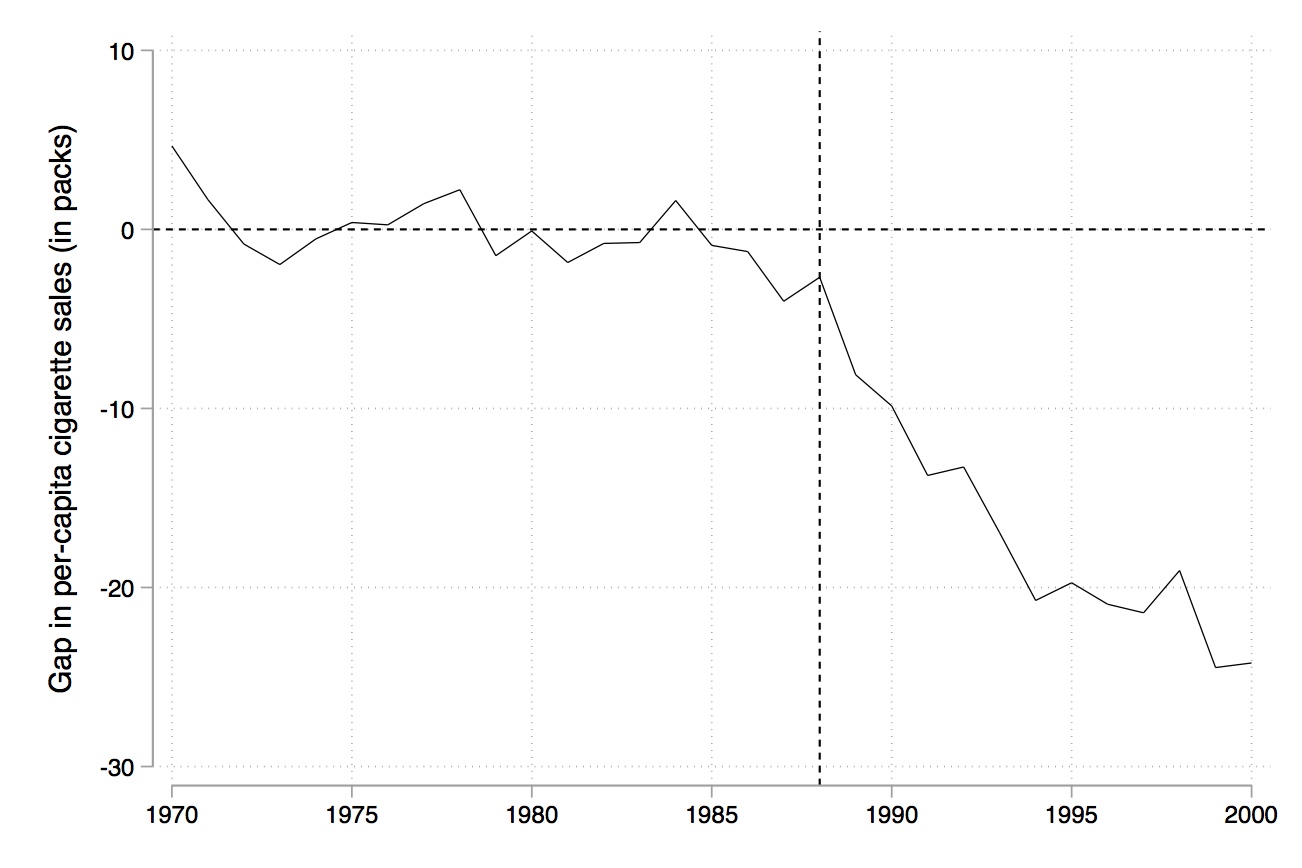
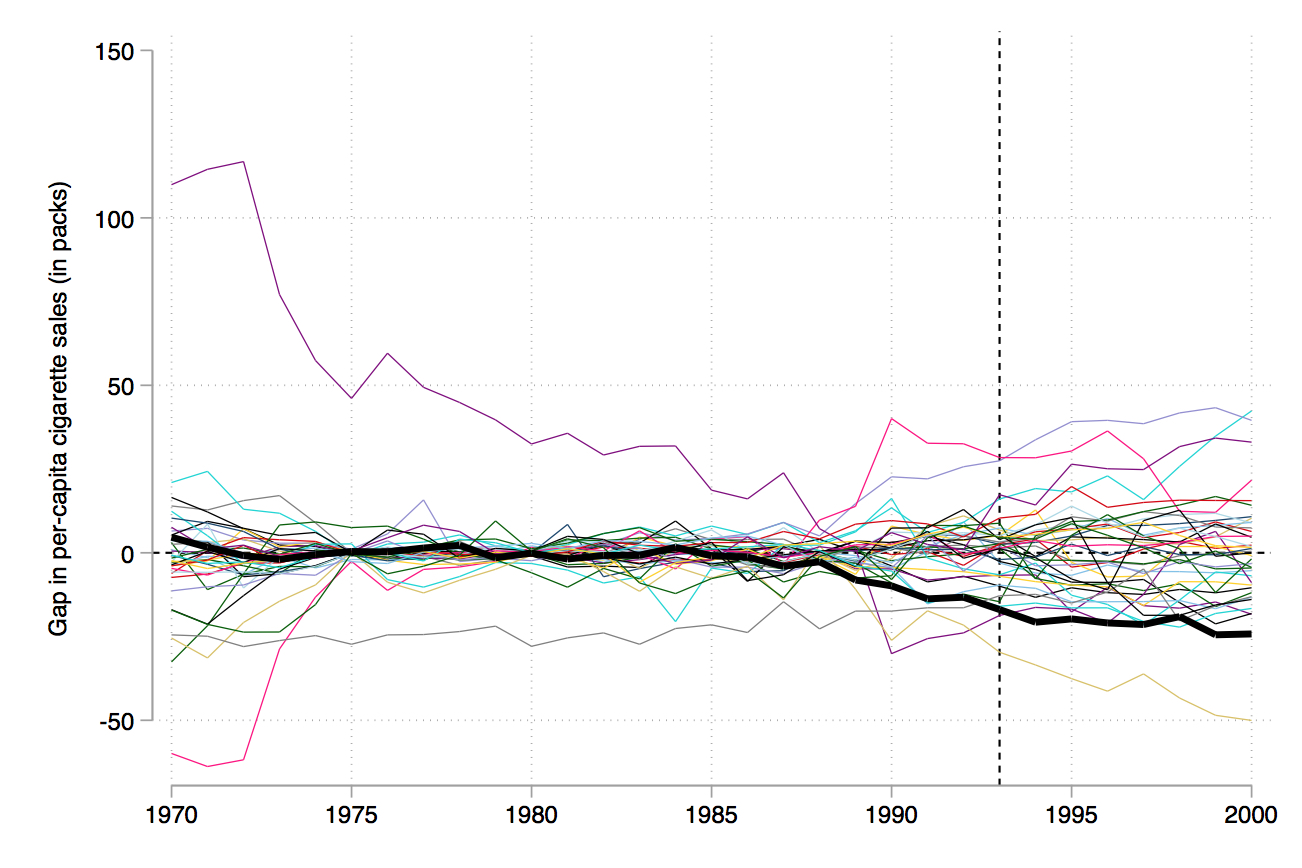
Abadie, A., Diamond, A., & Hainmueller, J. (2010). Synthetic Control Methods for Comparative Case Studies: Estimating the Effect of California’s Tobacco Control Program. Journal of the American Statistical Association, 105(490), 493-505.
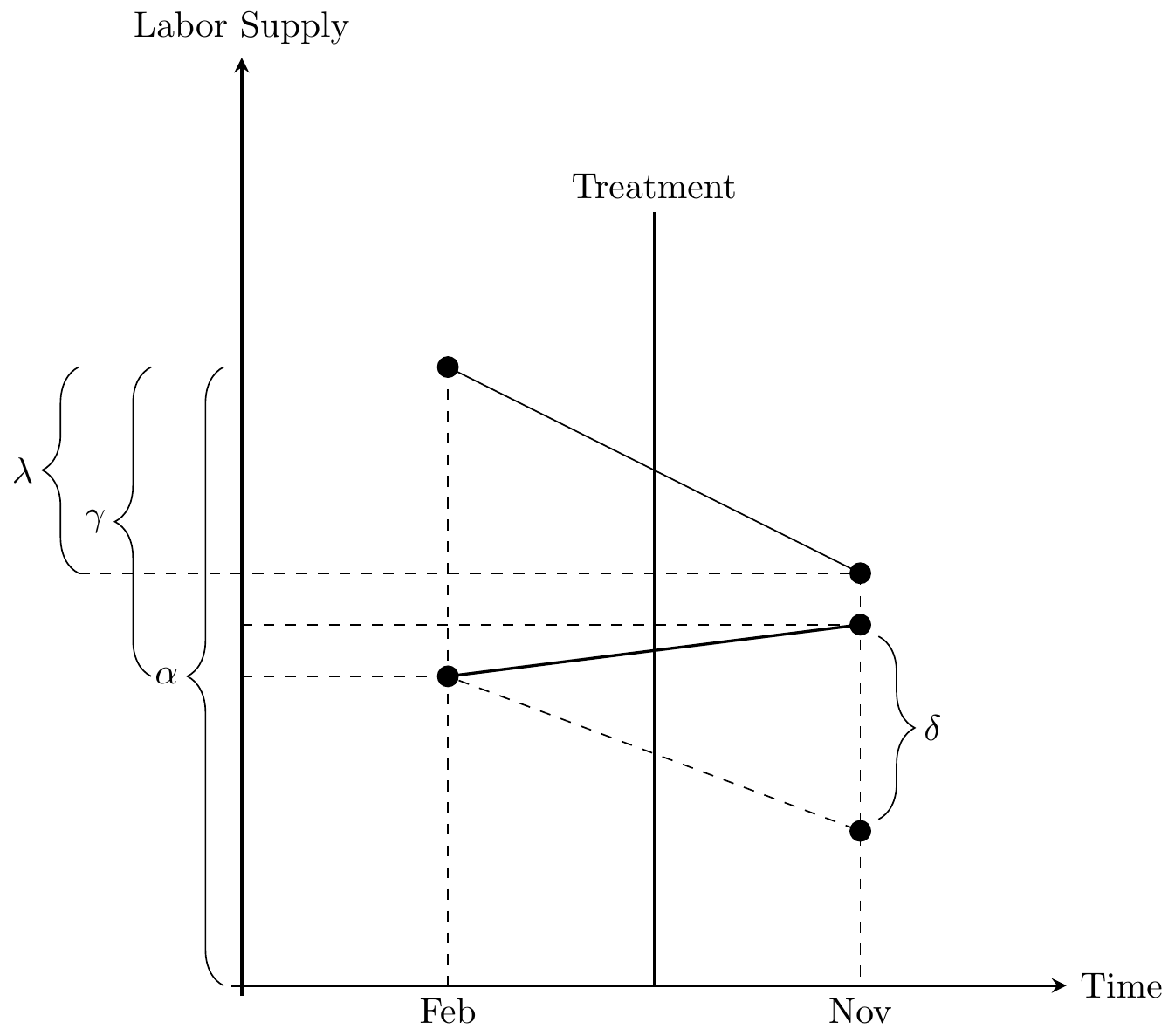
Angrist, J. D., & Pischke, J. S. (2009). Mostly Harmless Econometrics: An Empiricist’s Companion. Princeton University Press.
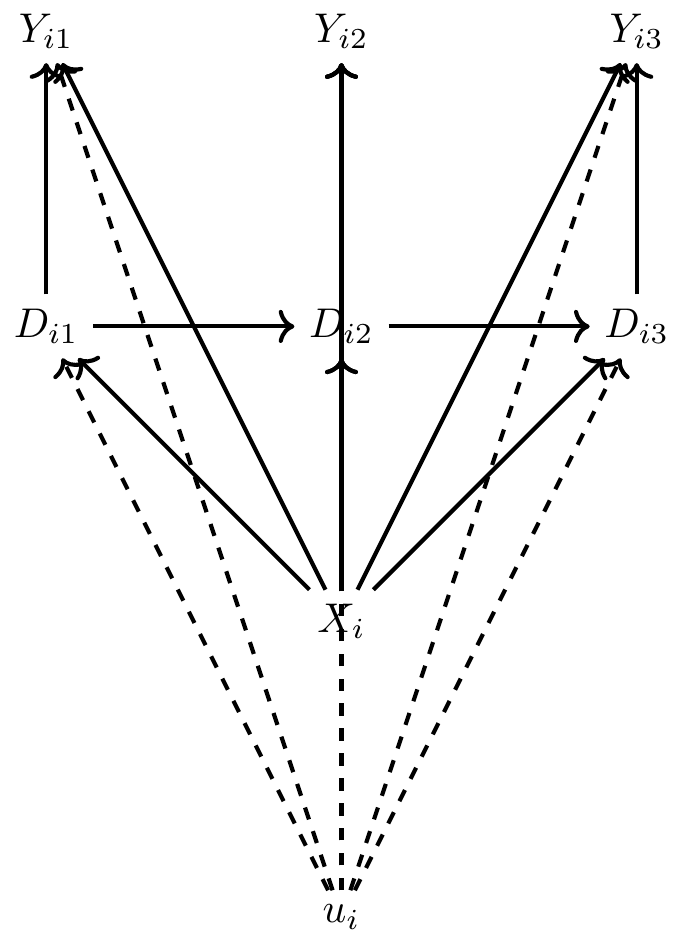
Callaway, B., & Sant’Anna, P. H. (2021). Difference-in-Differences with Multiple Time Periods. Journal of Econometrics, 225(2), 200-230.
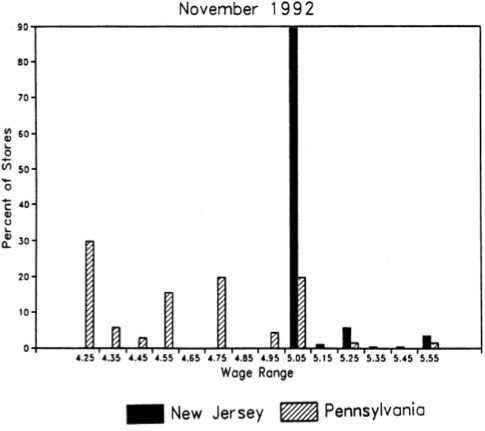
Card, D., & Krueger, A. B. (1994). Minimum Wages and Employment: A Case Study of the Fast-Food Industry in New Jersey and Pennsylvania. American Economic Review, 84(4), 772-793.
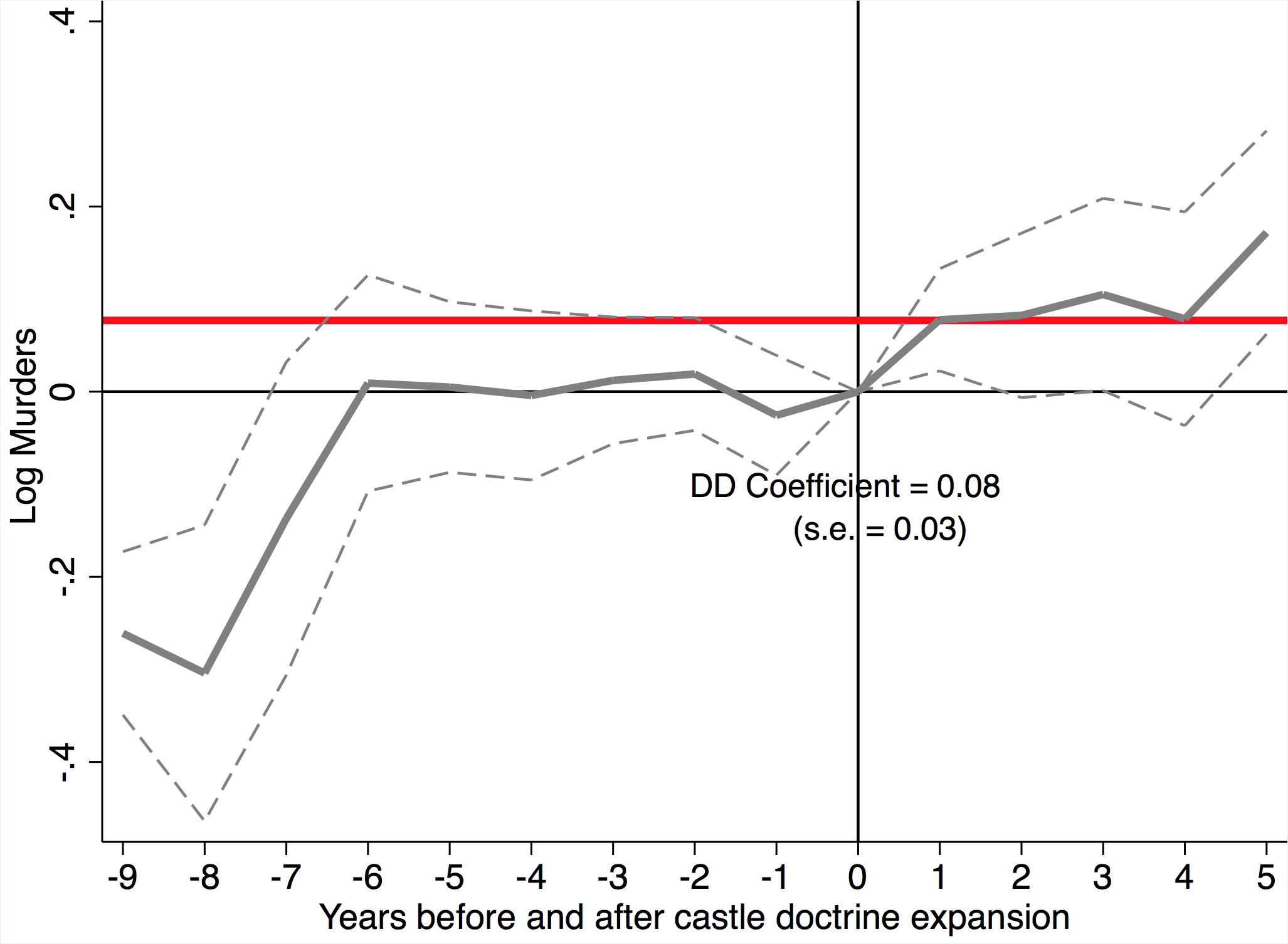
Goodman-Bacon, A. (2021). Difference-in-Differences with Variation in Treatment Timing. Journal of Econometrics, 225(2), 254-277.
Gruber, J. (1994). The Incidence of Mandated Maternity Benefits. American Economic Review, 84(3), 622-641.
Miller, S., Johnson, N., & Wherry, L. R. (2019). Medicaid and Mortality: New Evidence From Linked Survey and Administrative Data. NBER Working Paper No. 26081.