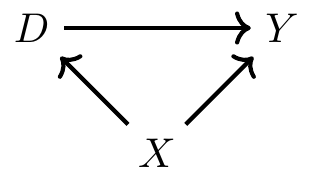
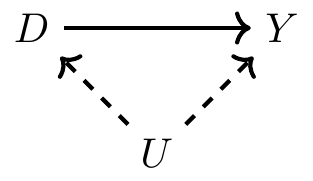
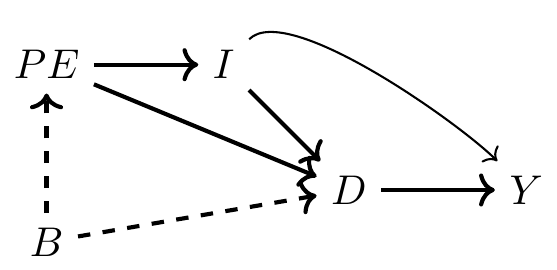
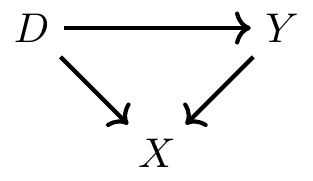
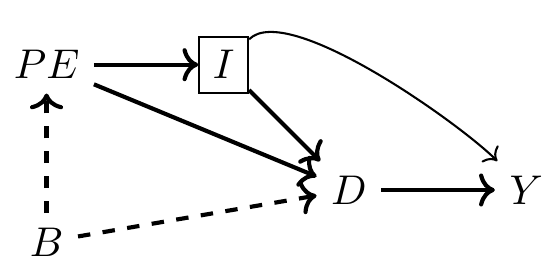
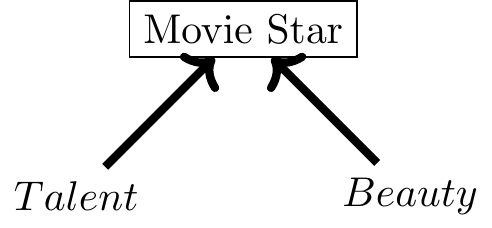
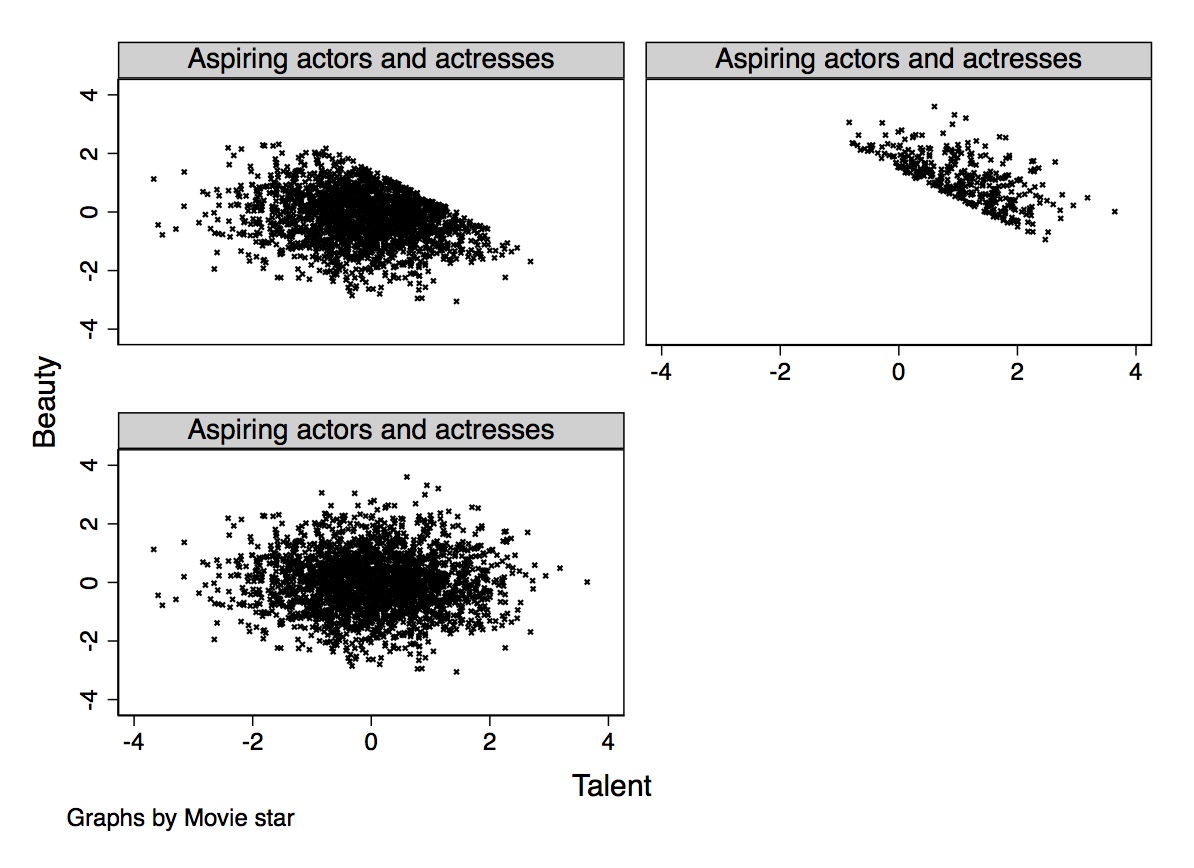
import networkx as nx
import matplotlib.pyplot as plt
# 创建有向图
G = nx.DiGraph()
nodes = [
('C', {'label': '能力(C)', 'type': 'confounder', 'color': '#FF6B6B'}),
('D', {'label': '培训(D)', 'type': 'treatment', 'color': '#4ECDC4'}),
('M', {'label': '技能(M)', 'type': 'mediator', 'color': '#95E1D3'}),
('Y', {'label': '绩效(Y)', 'type': 'outcome', 'color': '#F38181'}),
('L', {'label': '留任(L)', 'type': 'collider', 'color': '#FFA07A'})
]
G.add_nodes_from([(n, attr) for n, attr in nodes])
edges = [('C','D'), ('C','Y'), ('D','M'), ('M','Y'), ('D','Y'), ('D','L'), ('Y','L')]
for u, v in edges:
G.add_edge(u, v)
fig, ax = plt.subplots(figsize=(7, 4.5))
pos = {'C': (0, 2), 'D': (-1.5, 1), 'M': (0, 1.2), 'Y': (1.5, 1), 'L': (0, 0)}
node_colors = [G.nodes[n]['color'] for n in G.nodes()]
nx.draw_networkx_nodes(G, pos, node_color=node_colors, node_size=2000,
edgecolors='black', linewidths=2, ax=ax)
nx.draw_networkx_edges(G, pos, edge_color='#333333', width=2.5, arrows=True,
arrowstyle='-|>', arrowsize=28, ax=ax,
connectionstyle='arc3,rad=0.10')
labels = {n: G.nodes[n]['label'] for n in G.nodes()}
nx.draw_networkx_labels(G, pos, labels, font_size=9, font_weight='bold', ax=ax)
ax.set_title('NetworkX/CausalGraph 绘制 DAG', fontsize=12, fontweight='bold')
ax.axis('off')
ax.set_xlim(-2.5, 2.5)
ax.set_ylim(-0.5, 2.5)
# 图例(右下角)
legend_text = '节点类型:红色=混淆(C) 青色=处理(D) 浅绿=中介(M) 粉色=结果(Y) 橙色=碰撞(L)'
ax.text(2.3, -0.3, legend_text, ha='right', va='bottom', fontsize=7,
bbox=dict(boxstyle='round', facecolor='wheat', alpha=0.7))
plt.tight_layout()
plt.show()
print(f"DAG统计: {G.number_of_nodes()}节点, {G.number_of_edges()}边, 2条后门路径")
print("CausalGraph特点: 基于networkx.MultiDiGraph | 支持时序因果 | 兼容ggdag")