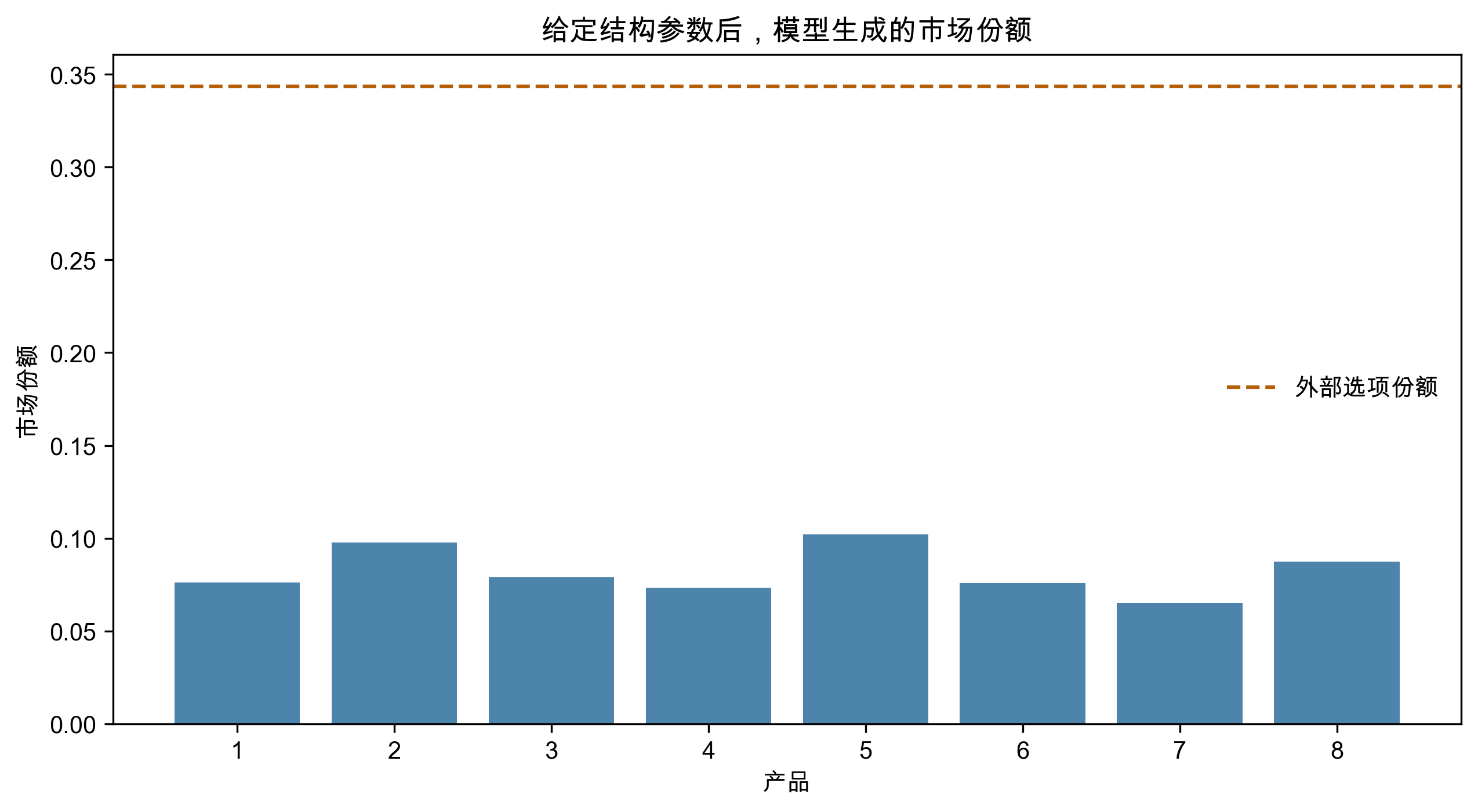
J = 8
alpha = 1.4
beta = 0.8
x = np.linspace(0.2, 2.0, J)
price = 1.0 + 0.5 * x + np.random.normal(0, 0.08, J)
xi = np.random.normal(0, 0.15, J)
delta = beta * x - alpha * price + xi
exp_delta = np.exp(delta)
shares = exp_delta / (1 + exp_delta.sum())
outside = 1 - shares.sum()
pd.DataFrame({"x": x, "price": price, "share": shares}).round(3)| x | price | share | |
|---|---|---|---|
| 0 | 0.200 | 1.140 | 0.076 |
| 1 | 0.457 | 1.218 | 0.098 |
| 2 | 0.714 | 1.409 | 0.079 |
| 3 | 0.971 | 1.608 | 0.073 |
| 4 | 1.229 | 1.596 | 0.102 |
| 5 | 1.486 | 1.724 | 0.076 |
| 6 | 1.743 | 1.998 | 0.065 |
| 7 | 2.000 | 2.061 | 0.087 |